
ML Case-study Interview Question: Overcoming Sparsity: Using Synthetic Data for Robust Flight Price Forecasting.


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a large online travel platform. Your team wants to build a flight price forecasting system. However, the real user-driven search data is sparse because different routes, trip dates, and passenger counts do not get searched often enough to form a consistent time series. You propose creating synthetic search data by scripting daily searches for specific popular routes, trip dates, and passenger counts. This ensures a consistent dataset where each route is searched at least once a day. The system then logs the resulting prices. However, generating these synthetic searches involves extra costs and added load on the search infrastructure. How would you design a solution that uses synthetic searches to improve flight price forecasts while balancing data storage costs, system strain, and the goal of covering as many routes as possible?
Detailed solution
Understanding the data sparsity problem
Real user-driven searches do not always create reliable time series data for each route. Many departure-destination pairs and trip dates have irregular or missing observations. This complicates time series forecasting models because they rely on consistent, frequent observations across the timeline.
Using synthetic search data to fill gaps
Synthetic searches let you pick which routes, trip lengths, and departure dates to query each day. This ensures each combination has at least one search per day, forming a continuous price history. These results can feed into time series or other predictive models. You must limit the scope to popular routes and feasible search parameters to control cost and infrastructure load. Synthetic data guarantees continuity but introduces overhead in terms of traffic and storage.
Core forecasting approach
Training a predictive model requires a daily sequence of prices per route. A common loss function to measure forecasting quality is Mean Absolute Percentage Error (MAPE). One example of MAPE is shown below.
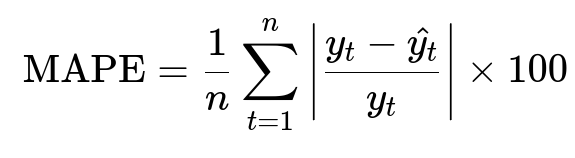
Here, n is the number of data points in the test set, y_t is the actual price at time t, and hat{y_t} is the predicted price at time t.
Models could include classical time series methods or more advanced architectures (random forest regressors, gradient-boosted trees, or deep learning models). Synthetic data provides a uniform time series. This reduces missing gaps and helps train stable models.
Practical system design
A Python job can be scheduled to run each day. It queries a set of routes (for example, top 1,000 city pairs) for each departure date in a certain advance purchase window (for example, 180 days ahead), and for both one-way and roundtrip flights. The synthetic queries run against the platform's search system. The returned flight data is captured in a central storage system. Each day’s newly generated data is appended, so each route has a daily record of prices. This approach ensures consistent coverage.
A second job can orchestrate cleaning and transformation. It may remove anomalous prices or handle last-minute seat availability issues. It can aggregate flight offers or pick the lowest fare, depending on the forecasting goals.
Balancing coverage and cost
The system can be scaled up to include more routes, but costs will increase with the number of daily searches. Network usage, compute usage, and data storage must be tracked. If you expand to additional routes, you must check that this does not overload the production search system. Storing large daily snapshots can get expensive. This might involve compressing or summarizing data in a data warehouse or using an efficient data format.
Model scalability
A model can be restricted to a finite set of routes covered by synthetic data. This gives reliable forecasts for those routes but does not generalize to all possible routes. A more generalized model, such as a deep learning model trained on route embeddings, can extend coverage. You can still seed such a model with synthetic data for major routes and rely on partial real data for others. A hybrid solution is to cluster routes by geographic or commercial similarity, fill major representatives with synthetic data, and train a more unified model across clusters.
Example Python snippet for daily synthetic search
import requests
import datetime
routes = [("LAX", "JFK"), ("SEA", "SFO"), ...]
days_ahead = 180
base_url = "https://www.example-travel-platform.com/api/flights"
def run_synthetic_queries():
today = datetime.date.today()
for origin, destination in routes:
for offset in range(days_ahead):
departure_date = today + datetime.timedelta(days=offset)
# Roundtrip examples for a range of trip lengths
for trip_length in [3, 5, 7]:
return_date = departure_date + datetime.timedelta(days=trip_length)
query_params = {
"origin": origin,
"destination": destination,
"departure_date": departure_date.isoformat(),
"return_date": return_date.isoformat(),
"num_passengers": 1,
}
response = requests.get(base_url, params=query_params)
store_response(response.json(), origin, destination, departure_date, return_date)
def store_response(data, origin, destination, departure_date, return_date):
# Save data to your storage system
pass
This code sends a set of requests to a flight search API, collecting results for each route-date combination. The results can be saved in a database or object storage. The concept is straightforward but requires optimization for production-scale usage.
What-if follow-up questions and answers
How do you decide the threshold for including a route in the synthetic search?
You prioritize routes that cover a high percentage of total bookings. Historical booking data can show the top 1,000 city pairs capturing 70%+ of ticket sales. This approach ensures you maximize coverage while limiting cost. Adding routes beyond that threshold may not yield proportional ROI. You can also factor in marketing priorities or strategic destinations.
How do you manage data gaps caused by system outages or query failures?
You can implement retries for failed synthetic searches. If an outage persists, you can interpolate prices on those missed days, or you can exclude that day from your training window to avoid corrupting your time series. You could also track response errors and raise an alert for critical routes that fail searches for several days in a row.
How would you extend the forecast to less-popular routes that have no synthetic data?
You can build a generalized model that consumes real user searches combined with cluster-level features. You can cluster similar routes by distance, region, or demand profile. You can then train a multi-task model that relies on the synthetic data for popular routes and uses partial real data for less-popular routes. Transfer learning or embedding-based models (for instance, learning route embeddings) can infer patterns for routes without synthetic coverage.
How do you ensure synthetic queries do not disrupt the production environment?
You can schedule them during off-peak hours. You can set an upper rate limit for synthetic queries to avoid spikes. You can coordinate with platform teams to confirm your query volume aligns with system capacity. You can monitor system metrics (CPU usage, latency, error rates) in real time and reduce or pause synthetic queries if the search service shows stress.
How do you evaluate model performance in real production scenarios?
One approach is to compare the model’s predictions against actual observed prices at different future intervals (for example, 7 days before departure, 30 days before departure). You can measure forecast error metrics such as MAPE. You can also run online experiments where you show forecasted price advice to a subset of users and track engagement or conversion rates compared to a control group. You should ensure that your offline metrics correlate well with real-world user behavior and booking decisions.
What methods would you consider for representing and handling seasonality?
Time series models like SARIMA capture weekly, monthly, or annual seasonality. Gradient-boosted trees or neural networks can incorporate date-based features (month, day of week, holiday indicators) to model seasonal fluctuations. If you store flight searches daily, you can add features representing monthly or weekly cycles. You can also incorporate external event data, such as major holidays, conferences, or big travel seasons, as categorical or numerical covariates.
How do you handle anomalies or sudden fare changes?
You can add rules that detect if a price changes drastically compared to recent historical averages. If the deviation is too large, the data might be flagged for manual review or assigned a lower weight in training. You can also incorporate outlier detection algorithms. Some advanced models can detect sudden regime shifts and adapt quickly if they see abrupt changes in the time series.
Why not just rely on organic user searches for every route?
It is unstructured. Many routes do not get searched daily, and even popular routes may have data gaps on certain dates. This leads to missing points in your time series, which complicates training and reduces accuracy. Synthetic searches fix that by ensuring daily coverage for a curated set of routes. The trade-off is higher cost and system load, so the system must be carefully scaled.
How do you store and manage the synthetic data for quick access during model training?
You can store raw responses in a data lake or warehouse. Then transform them into clean time series tables keyed by route and date. Partition the tables by date or route to handle large-scale queries. Use columnar formats for faster aggregation. You can set up processes that merge daily synthetic data with any relevant booking or event data so that your model can access the combined dataset without repeated joins.
How does this approach evolve as the company grows or changes focus?
Additional routes or bigger coverage might become necessary if the platform enters new markets or sees shifts in travel demand. The data collection pipeline must be modular, so you can add or remove routes without major rework. You can refine or expand your forecasting models to handle more route variety. You might adopt distributed computing or more advanced time series frameworks to handle large-scale forecasting tasks if you decide to track thousands of extra routes.