
ML Case-study Interview Question: Deploying Large Language Models for Scalable Text Interpretation


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a large technology platform. The platform plans to incorporate Generative AI to help users interpret and manage massive amounts of text content across communities. The goal is to design and deploy a new feature using a Large Language Model to summarize discussions, assist in content moderation, and improve user experience. The platform expects heavy throughput from millions of users, but also wants low-latency responses and robust privacy safeguards. How would you architect, prototype, test, and fully launch this Generative AI feature at scale?
Proposed Solution
Start by clarifying the target user problems the AI-powered feature should address. Identify areas where a standard rules-based or smaller model would not suffice. Generative AI is a resource-intensive tool. Focus on clear product outcomes, such as interpreting unstructured text for summarization or moderation.
Define exact product requirements. Decide how fast the system must respond. Consider how domain-specific the queries will be. Examine how much context prompts will carry. If high accuracy is required, off-the-shelf Large Language Models with robust performance can be used. For rapid experimentation, use a strong commercial provider to see if the feature is actually valuable. If the top-tier model fails to meet expectations, your problem might not be solvable by current Generative AI technology.
Begin prototyping. Formulate a starter prompt for the LLM. Refine the wording to yield clearer outputs. Rigorously evaluate quality by checking whether the outputs align with expected tasks. Use AI-assisted evaluation by letting a separate advanced model critique and score the responses. This helps you systematically improve prompts instead of randomly guessing which adjustments work.
Roll out a limited release or A/B test to see how real users interact. Monitor user satisfaction metrics and note system health, focusing on response time, throughput, parsing errors, and cost. Adjust the prompt or introduce post-processing if the raw output is inconsistent. If metrics show success, plan a full deployment.
Plan the production infrastructure. Connect your front-end or service to an inference server. For large-scale commercial LLM usage, incorporate safety filters and data minimization. If in-house control of data is essential, consider self-hosting an open-source or fine-tuned model. Expect more engineering overhead for hosting. Acquire the appropriate GPUs, optimize your serving stack for throughput, and tune batch sizes for performance.
When scaling, watch costs. You can approximate cost by the throughput, tokens used, and per-token price. A typical formula for usage-based cost might be shown below.
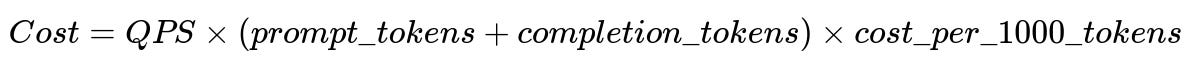
Where QPS is requests per second, prompt_tokens are how many tokens the model reads, completion_tokens are how many tokens the model writes, and cost_per_1000_tokens is the price from your LLM provider. Watch these metrics to ensure you can sustain the feature financially.
Use data from your pilot phase to validate user value and weigh trade-offs in response time, accuracy, and cost. If the final results indicate that the feature fulfills user needs with manageable latency and cost, launch it at scale. Otherwise, iterate on prompt design, model choices, or architecture configuration.
Follow-up Question 1
How would you decide if a simpler, rules-based approach is sufficient compared to a full Generative AI solution?
Answer Assess the complexity of the unstructured text. If you can capture most patterns with heuristics or a simpler predictive model, Generative AI may not be worth the overhead. Check whether data has consistent patterns that are easily encoded. For example, short, structured messages might only need a keyword-based filter. If the content is highly varied and context-heavy, Generative AI is more suitable. Evaluate the projected workload. Simpler methods are cheaper to maintain. Generative AI is better when key tasks involve nuanced language understanding across diverse topics.
Follow-up Question 2
How would you handle privacy concerns when user data is sent to the inference server?
Answer Minimize data in the prompts, sending only what is crucial. Apply sanitization and anonymization where possible. For extremely sensitive information, consider on-premise or private cloud hosting. Keep logs of requests and responses in an access-controlled environment. Implement internal privacy audits, ensuring compliance with relevant regulations. Maintain strict data retention policies. When working with an external provider, incorporate robust data-handling agreements or encryption protocols to protect user information.
Follow-up Question 3
What would you do if the LLM frequently fabricates content (hallucinates) and provides incorrect answers?
Answer Inject guardrails into the prompts to emphasize factual precision. Post-process the output to spot potential falsehoods. Provide the model with structured references or ground-truth data. Use AI-assisted evaluation to detect factual inconsistencies, then filter them out. If you control the entire pipeline, fine-tune the LLM with your domain-specific data. Include disclaimers or highlight uncertain outputs to the user. Keep collecting user feedback about specific inaccuracies to refine your next iteration.
Follow-up Question 4
Why might you choose to self-host a model rather than rely on a third-party commercial API?
Answer Self-hosting can dramatically reduce long-term costs, especially at scale. It allows more flexibility in model customization, giving you the option to fine-tune or adapt the LLM with in-house data. Data never leaves your control, which is valuable for privacy-sensitive use cases. The downsides are engineering overhead and potential performance bottlenecks if not optimized. Budget for high-end GPUs and distributed systems. If your team can maintain reliable infrastructure and you can handle the initial setup costs, self-hosting is viable.
Follow-up Question 5
How would you optimize a self-hosted LLM for high throughput and low latency?
Answer Use a dedicated model serving framework optimized for GPU inference. Configure batch sizes so your pipeline can serve multiple requests simultaneously without delaying single-query responses. Select smaller or quantized models if response speed is critical, but only if they meet accuracy needs. Ensure your system architecture supports concurrent requests at the network and GPU layers. Fine-tune the model and calibrate prompt lengths. Experiment with caching repeated contexts. Profile end-to-end latency to locate bottlenecks in data transfer, model initialization, or result parsing.
Follow-up Question 6
How do you measure success once the feature is in production?
Answer Use real user metrics such as feature adoption, engagement, or explicit user ratings. Compare usage before and after introducing Generative AI. Track error rates where the model fails or times out. Ask for direct user feedback on the relevance and correctness of outputs. Collect cost data to see if the feature is profitable. Maintain logs on harmful or incorrect generations. Combine these to decide if the solution aligns with business goals and user satisfaction. If short of targets, iterate on prompt design or model selection.
Follow-up Question 7
What engineering or product improvements might you make once the system is stable?
Answer Gradually incorporate advanced features such as domain-specific fine-tuning or new languages. Experiment with more compact or specialized models to reduce costs. Improve the user interface for better transparency when results might be incorrect or partial. Integrate user feedback loops for continuous prompt refinement. Automate monitoring dashboards so non-technical stakeholders can see performance metrics at any time. Evaluate new open-source innovations that lower latency or enhance output consistency. Keep prioritizing user experience and aligning updates with evolving product requirements.