
ML Case-study Interview Question: Personalized Training Recommendations Using Two-Stage Deep Learning and Content Embeddings


Browse all the ML Case-Studies here.
Case-Study question
A large retail chain wants to create a deep learning recommendation system for its in-house training platform. Millions of store associates log in daily to complete task-based learning modules. The chain wants to show each associate highly relevant, personalized training content when they open the platform. The platform has thousands of available learning pages. The chain needs a robust solution that can handle huge amounts of click data, new content, frequent content updates, and real-time serving constraints. How would you design and implement a two-stage recommendation system that first narrows down candidate modules and then ranks them for maximum relevance? Explain how you will capture the associates’ past interactions, incorporate content-based features for newer modules, generate embeddings for each training page, and then apply a deep learning ranking model for final output. Include how you will implement a regular re-training pipeline that handles data drift, model performance checks, and continuous integration of new content.
Proposed Detailed Solution
A two-stage recommendation system includes candidate generation and a deep learning ranking algorithm. Candidate generation filters a large pool of content. The ranking algorithm re-sorts a smaller batch of potential content to produce final recommendations.
Candidate Generation
Use two approaches. Collaborative filtering to find neighbors based on historical clicks and a content-based Natural Language Processing method to handle sparse cold-start items.
Collaborative Filtering Build a click matrix that captures which associates viewed specific pages. Represent each module in a latent vector space. Identify top-k similar modules for each page. Store these neighbors as potential recommendations.
Content-Based Similarity Parse each content’s text and extract keywords using a graph-based summarization method similar to TextRank but weighted by inverse document frequency. Train word embeddings on the full corpus to represent each keyword. Compare keyword pairs across pages to calculate content similarity scores. Identify top-k similar items for each content and keep them for the next stage.
Skip-Gram Content Embedding
Treat each content page as a "word" and sequences of an associate’s page views within a 30-minute window as a "sentence." Train a skip-gram model that predicts neighboring pages from a target page. Acquire an n-dimensional embedding for each page. These embeddings capture co-occurrence patterns of content usage.
A minimal Python example:
import gensim
# Suppose each session is a list of content IDs
sessions = [
["pageA", "pageB", "pageC"],
["pageX", "pageY"],
...
]
model = gensim.models.Word2Vec(
sessions,
vector_size=128,
window=5,
min_count=1,
sg=1 # skip-gram
)
# Content embedding lookup
embedding_pageA = model.wv["pageA"]
Deep Learning Ranking Model
Combine wide and deep architecture to handle memorization and generalization. The wide component uses factorization machines to manage interaction features. The deep component is a feed-forward neural network.
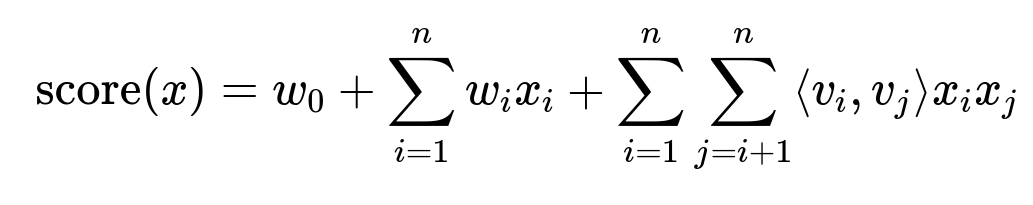
Here, x represents the feature vector of associate and content. w0 is the global bias term. w_i are the weights for each feature. v_i and v_j are latent factor vectors of dimension d. The last term is the pairwise interaction between features i and j. This factorization machine is integrated as the wide component to memorize patterns such as recurring seasonal behaviors. The deep component uses dense embeddings of the same input features to discover new patterns that were absent or sparse in historical data.
Re-Training Pipeline
Schedule different frequencies. Candidate models (collaborative filtering and similarity) can run daily to accommodate newly published content. The skip-gram embedding model can re-train weekly, producing vectors for fresh modules. The deep ranking model can re-train monthly to avoid heavy compute while still staying up to date. Implement data-drift detection to check for anomalies before model re-training. If performance metrics (e.g. AUC or recall) fall below thresholds, alert the engineering team.
Model Serving
Generate a short list from collaborative filtering and content-based similarity. Pass these items to the deep ranking model. Sort final outputs by predicted score. Deliver the top recommendations to the training platform in real-time.
Potential Follow-Up Question 1
How would you address the cold-start problem for new content or associates with minimal click history?
Answer Include content-based similarity to surface new pages by analyzing their textual features. Re-train skip-gram more frequently to assign embeddings to new items, even if partially based on shorter interactions. Default to aggregated popularity-based content for completely new users, then incrementally shift to personalized models once enough behavior data is collected.
Potential Follow-Up Question 2
Why is a wide component necessary when you already have a deep neural network?
Answer A purely deep network may generalize well but lose specific historical correlations. The wide component (with factorization machine) memorizes crucial feature interactions that appear repeatedly (such as time-of-day usage or recurring seasonal content). It handles known triggers and direct relationships in a linear format.
Potential Follow-Up Question 3
How can you guarantee real-time performance under heavy traffic?
Answer Pre-generate candidate lists offline and keep them in a fast key-value store. Assign each content a precomputed embedding. In real-time, retrieve only the top candidates. Then run a small forward pass of the ranking model on that shortened list (for example, 20 candidates). Deploy using a low-latency inference environment with hardware acceleration where necessary.
Potential Follow-Up Question 4
How do you handle data drift detection in a pipeline?
Answer Set statistical monitors on input distributions. Compare daily or weekly aggregates (mean, variance, ratio of categorical values) with historical baselines. If distributions deviate beyond a threshold, pause re-training and send alerts. Investigate unusual spikes or missing data. This prevents feeding corrupted or inconsistent data into the new model.
Potential Follow-Up Question 5
What if performance drops for a newly deployed ranking model?
Answer Keep the last stable model. Include performance checks in the pipeline. If metrics like AUC, precision, or click-through rate degrade past a limit, revert to the stable model. Investigate training logs for overfitting, underfitting, or mislabeled data. Re-run hyperparameter tuning and debugging steps before re-deploying.
Potential Follow-Up Question 6
How would you integrate user feedback beyond simple clicks?
Answer Add explicit feedback signals such as ratings or comments as features. If associates complete or skip modules quickly, feed that engagement pattern back into feature columns for the next training cycle. Track dwell time. If associates often exit pages early, treat that as negative feedback. Include these signals in the wide component or embed them in the deep network.
Potential Follow-Up Question 7
Why does skip-gram help generate more effective item embeddings than simpler methods?
Answer Skip-gram captures local context within session windows. Modules viewed consecutively or in close temporal proximity share semantic connections. Purely frequency-based embeddings might miss nuanced transitions between items. Skip-gram preserves sequence patterns in a continuous vector space. This yields more expressive embeddings that help the ranking model.
Potential Follow-Up Question 8
What are the most critical hyperparameters to tune in the final ranking model?
Answer Tune dimension of latent factors in the factorization machine. Adjust depth and width of the deep neural network. Adjust learning rate and regularization parameters. Run cross-validation or Bayesian optimization to find the best trade-off between memorization in the wide component and generalization in the deep component.
Potential Follow-Up Question 9
How does the recommendation system ensure time-sensitive results?
Answer Capture login day, hour, or shift as part of the feature vector. Factorization machines memorize the distribution of content usage over different time segments. The deep network generalizes these temporal patterns to new scenarios. This ensures that if certain content is typically consumed in the morning, it ranks higher during that time window.
Potential Follow-Up Question 10
Could you use a different neural architecture for the ranking stage?
Answer Yes. Some teams use gradient boosted decision trees, attention-based networks, or transformer models. The choice depends on data volume, feature complexity, and interpretability. Deep Factorization Machines provide an efficient wide-and-deep approach that handles large-scale data with lower engineering complexity than a full transformer stack.