
ML Case-study Interview Question: Optimizing AdGroup Marketing Spend with Thompson Sampling


Browse all the ML Case-Studies here.
Case-Study question
A consumer product enterprise wants to optimize marketing spend across several audience segments (AdGroups). Each AdGroup has unknown performance potential, and the business wants to maximize conversions while reducing cost-per-acquisition. They plan to use Reinforcement Learning and specifically explore multi-armed bandit strategies, including Thompson Sampling, to dynamically allocate spend. The goal is to identify which AdGroups yield higher returns and to adapt spending over time based on real-world performance. How would you design and implement a solution that iteratively refines spend decisions, updates distribution estimates for each AdGroup, and delivers an actionable budget allocation strategy to campaign managers?
Detailed Solution
Reinforcement Learning can find an optimal strategy for distributing budgets among different AdGroups. The multi-armed bandit framework addresses the exploration-exploitation tradeoff. Thompson Sampling is used because it balances exploration (testing various AdGroups) and exploitation (focusing on high-performing AdGroups) in a Bayesian manner.
Multi-Armed Bandit Overview
A multi-armed bandit problem involves multiple choices or arms (here, AdGroups). At each iteration, we pick one AdGroup and observe its reward. In marketing, the reward can be conversions or click-through rates. Over time, the algorithm refines which AdGroup is most likely to generate the best reward.
Thompson Sampling
Thompson Sampling maintains a probability distribution for each AdGroup’s performance. Initially, these distributions are broad because of limited prior information. Every time an AdGroup is chosen, the result updates its distribution, making it more precise. This helps the model concentrate on promising AdGroups without completely ignoring others.
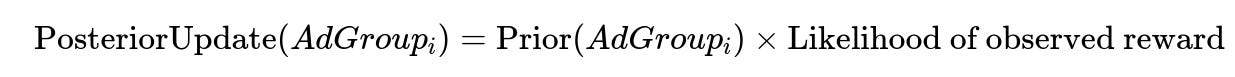
This formula illustrates that the posterior distribution is proportional to the product of the prior distribution and the likelihood derived from the new reward data. “Prior” represents our initial guess about the AdGroup’s performance, while “Likelihood of observed reward” represents how probable the observed data is under the current distribution.
Once all AdGroups have updated distributions, budget recommendations come from sampling these distributions. The AdGroup whose draw yields the most favorable result is assigned the highest proportion of the budget. Repeated draws over many iterations yield a ratio for budget allocation.
Practical Implementation
Use Python and relevant libraries (scikit-learn, PySpark, statsmodels, SciPy) for data engineering and model development. Store raw campaign data in a cloud infrastructure. Create a data pipeline that transforms raw marketing data into a standard schema. Train Thompson Sampling models on aggregated daily or weekly data.
A typical metric is CTR (click-through rate) or CPA (cost per action). For instance:
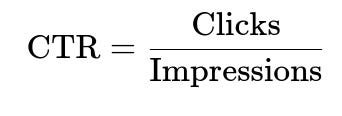
CPA is total cost divided by total conversions. Because Thompson Sampling is iterative, you feed in daily or weekly performance data for each AdGroup, update its distribution parameters, then reassign the budget.
Integrating Contextual Bandits
Contextual bandits incorporate information about environment or AdGroup context (e.g., time of week, user demographics). Campaign managers manually influence context by adjusting creative content or focusing on best-performing audiences. This approach refines the bandit framework to ensure the model captures environment-dependent behavior.
Final Deliverable
A budget recommendation module outputs the fraction of budget per AdGroup. The resulting ratios can be displayed on a dashboard for marketing teams. They can override or adjust allocations based on external insights.
How would you handle data sparsity when certain AdGroups have very few impressions?
Thompson Sampling updates distributions using Bayesian methods that still function with limited data. When impressions are sparse, the algorithm’s prior distributions remain wide, reflecting high uncertainty. You can start by assigning modest budgets to those AdGroups, then let incremental data either confirm or adjust their performance estimates. If an AdGroup stays unproven, the algorithm naturally allocates fewer resources. Gathering more data or combining historical distributions with domain knowledge also helps.
How do you ensure the solution remains robust to non-stationary user behavior?
AdGroup performance can change over time if user preferences shift. You can implement a rolling window for updates, giving more weight to recent performance and gradually discounting older data. Another approach is to reset or partially reset the distributions at specific intervals to account for seasonality or market changes. This keeps the Thompson Sampling model adaptable to dynamic conditions.
How do you measure success and validate the model?
One metric is cumulative reward (conversions or revenue). Higher cumulative reward implies better budget allocation. Another metric is regret, comparing actual performance to an ideal policy that always picks the true best AdGroup. If regret remains low, the model is adapting well. You can also run controlled experiments where a certain subset of the traffic is allocated according to a baseline method. Compare the performance of the Thompson Sampling approach against that baseline over the same time window.
How can campaign managers incorporate domain expertise into the model?
They can set priors to reflect prior knowledge about likely top performers. For instance, if internal data suggests a particular AdGroup is highly engaged, its prior distribution can start more optimistic. Managers also change the context by adjusting ads or messaging. The contextual bandit approach looks at these adjustments and learns which environment-AdGroup combinations work best. If managers suspect diminishing returns for certain AdGroups, they can tweak input data or add constraints to the budget allocation code to limit maximum spend.
What if the marketing team wants to optimize multiple metrics simultaneously?
You can formulate a multi-objective approach, weighting metrics like return on ad spend (ROAS), click-through rate, or brand engagement. One strategy is to combine them into a single utility function, with weights reflecting business priorities. Thompson Sampling then maximizes that composite utility. Alternatively, you can maintain separate bandit models for each metric and combine recommendations with a final decision rule. The choice depends on whether the business can unify metrics into a single objective or needs a more segmented allocation.
How would you handle outliers and noise in the performance data?
Use robust statistics to mitigate outliers. For instance, winsorize extremely high or low reward values to maintain stable parameter updates. Bayesian updates tend to absorb noise by broadening distribution estimates, so Thompson Sampling can handle moderate outliers. If outliers are frequent, investigate root causes in data collection. If they stem from tracking errors, filtering or imputing data is wise. If they stem from real but rare events, keep them in the model’s distribution with proper weighting.
How do you move from an offline training to real-time inference?
Retain an initial model trained on historical data. Serve this model in a production environment that receives live feedback on each AdGroup’s performance. After a specified number of actions or time intervals, update your Bayesian parameters in a near-real-time loop. You can schedule model updates daily or weekly, depending on data volume. This pipeline requires close integration with your data store and a robust testing procedure to ensure you don’t push erroneous updates into production.