
ML Case-study Interview Question: GNN-Powered Product Bundling: Tackling Sparsity in E-commerce Recommendations.


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce platform wants to increase multi-item purchases by offering product bundles. They have an extensive catalog with significant data sparsity and need a system that recommends a primary product (driver product) plus a set of complementary go-together products. Their initial approach used basic Association Rule Mining on product attributes but performed poorly in identifying driver products, often recommended overly similar products, and missed large segments of the catalog. Design and propose a new bundling solution that addresses these issues and improves coverage. Explain your architecture, data processing, modeling steps, deployment, and expected outcomes.
Detailed Solution
A straightforward approach uses Association Rule Mining on product attributes to capture co-occurrence. It struggles when joint purchases are sparse or when it cannot distinguish the correct driver product. A more robust method builds product graphs and applies Graph Neural Networks for link prediction. This approach uses historical cart and purchase events to construct weighted, directed edges, letting the system identify which product leads (driver) and which items can be recommended (go-together).
Graph Creation
Represent each category as a separate directed graph. Each node is a product. An edge from product A to product B indicates that guests often add or purchase B immediately after A. Edge weights accumulate from historical sessions. Normalize these weights and remove those below a threshold to reduce noise. This step yields edges that identify promising co-purchase relationships. However, many products remain disconnected because of sparse interactions.
Graph Padding With Similarity
Enhance coverage by incorporating edges from a “similar items” model, which predicts how closely two products resemble each other. If product X shares attributes or embeddings with product Y, and Y has edges to accessories Z1, Z2, etc., then X can also connect to those accessories. Merging these graphs adds new edges, boosting coverage.
GNN Link Prediction
Train a Graph Neural Network to predict probable links even if those products have never been co-purchased. A commonly used link prediction technique is the SEAL framework, which takes subgraph structures plus node features to output edge existence probability. One classic simplified formulation for predicting a potential link between node u and v is:
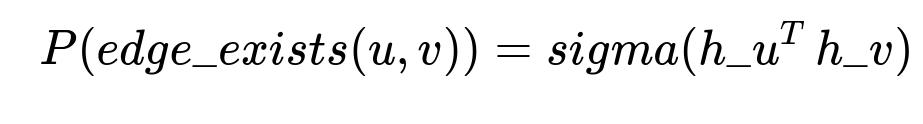
where P(edge_exists(u, v)) is the predicted probability of a link between u and v, sigma is a logistic function, h_u is the learned embedding for node u, and h_v is the learned embedding for node v. Positive training samples come from the existing edges. Negative samples are random pairs of nodes without an observed link. The GNN outputs a probability for each candidate edge. Keep edges with sufficiently high scores to form final bundles.
Deployment And Results
The model filters K recommended items per driver product. A large online test showed a double-digit percentage increase in click-based revenue and coverage. More products now receive bundle suggestions because unobserved interactions become discoverable through learned embeddings.
Example Python Code Explanation
Below is a brief pseudo-code snippet for handling the data:
import torch
from torch_geometric.nn import GCNConv
# Node features and edge indices come from historical cart data
node_features = ...
edge_index = ...
class SimpleGNN(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, 64)
self.conv2 = GCNConv(64, out_channels)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = torch.relu(x)
x = self.conv2(x, edge_index)
return x
model = SimpleGNN(in_channels=node_features.size(1), out_channels=64)
embeddings = model(node_features, edge_index)
# embeddings can then be used to compute link prediction scores
This snippet loads node features, builds a simple GCN, and generates embeddings. In practice, you would collect positive edges, sample negative edges, train the model to classify whether an edge exists, and then use the trained embeddings to infer new edges.
What if your graph becomes extremely large?
Partition the graph by category, use techniques such as mini-batching or sampling subgraphs, and store embeddings in memory-efficient formats. Distributed training frameworks like PyTorch Geometric and DGL can handle large-scale graphs by sharding.
How do you address cold start for newly launched products?
Retrain or fine-tune embeddings frequently. Seed new products with attribute-based similarity edges to existing products. This provides an initial set of predicted edges before enough purchase data accumulates.
How do you measure success for bundling recommendations?
Track coverage (fraction of products with valid bundles), click-through rate, and direct revenue lifts from recommended bundles. Online A/B tests show whether the new approach outperforms the baseline.
How do you prevent recommending highly similar products in a bundle?
Enforce diversity constraints by penalizing items that overlap in attributes with each other or with the driver product. During the final ranking, reject items whose features resemble the driver product or other bundle items beyond a threshold.
How do you maintain these models in a production environment?
Regularly refresh data with new cart sessions. Retrain or incrementally update embeddings. Monitor drift by comparing predicted edges against recent behaviors. If mismatch grows, schedule a new training cycle.
How would you handle real-time updates?
Use microservices that periodically batch-update edges with the latest cart events. Store embeddings in a fast retrieval layer. Full model retrains can happen offline, while incremental updates supply near-real-time improvements.
How do you handle explainability concerns?
Use the GNN subgraph structure for each recommended edge. Provide reasons such as past co-purchases with related items. Reveal high edge weights or top feature similarities that led to the recommendation.