
ML Case-study Interview Question: Scalable Multi-Stage Recommendations Using Two-Tower Neural Networks for Massive Content Discovery


Browse all the ML Case-Studies here.
Case-Study question
A large social platform has a massive content pool of billions of items. The platform wants to build a multi-stage recommendation pipeline to serve the most relevant content to hundreds of millions of people who check a dedicated discovery section daily. The goal is to retrieve thousands of promising items from the billions, then rank them in multiple steps, and finally apply business or integrity rules to refine and reorder. Propose an end-to-end approach that includes:
Retrieval methods.
Multi-stage ranking models.
Integration of caching and precomputation for efficiency.
A final reranking strategy with relevant constraints.
Parameter tuning methods.
Propose a system design with modeling details. Show how to handle real-time updates, maintain scalability, and ensure diversity and integrity. Outline key metrics, explain how you will measure success, and describe how you will iterate on these models. Assume real-time latency constraints and massive user-interaction volumes. Provide a detailed plan for implementation, deployment, and continuous improvement.
Most detailed solution
Retrieval
The system first retrieves a manageable subset of items for each user. It uses multiple sources that produce a few hundred candidates. Sources can be based on trending items or user interaction histories, augmented with advanced models:
Two Tower neural networks can represent users and items in a shared embedding space. One tower encodes user features (like demographics and interaction patterns). The other tower encodes item features (like content ID and metadata). The training objective is to predict engagement likelihood as a similarity between user and item embeddings. After training, the system stores item embeddings in an approximate nearest neighbor service such as FAISS or HNSW. Online inference uses the user tower to generate a user embedding and queries the service for the closest item embeddings.
Another retrieval method uses item embeddings directly from a user’s recent interactions. It finds items similar to the ones a user liked or shared. This is combined with filtering rules that exclude objectionable or poor-quality items.
First-stage ranking
It ranks thousands of retrieved items quickly with a lighter neural network. This model predicts how likely each item is to end up highly ranked by the heavier second-stage model. Two Tower caching helps here as well. The user and item representations are precomputed, allowing fast vector lookups. The first-stage model discards lower-probability items and passes only the top candidates to the next stage.
Second-stage ranking
It applies a heavier multi-task multi-label neural network to a smaller set of top items. This network predicts probabilities for multiple events such as click, like, or negative feedback. It can consume rich user-item interaction features because it operates on fewer items. To handle peak loads, the platform may precompute results for some users during off-peak hours. The final numeric score for ranking is an expected value estimate that weights each predicted event by its importance to overall objectives.
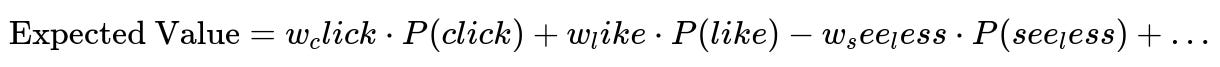
Here, w_click is the weight for clicks. P(click) is the predicted probability a user clicks on the item. w_like is the weight for likes. P(like) is the probability of a like. w_see_less is the weight for negative feedback. P(see_less) is the probability of negative feedback. The system sums these weighted terms to get one final score used for ordering.
Final reranking
The system then applies business or integrity rules to further adjust item positions, remove unsafe content, and broaden diversity. This might downrank repeated authors or block disallowed categories. The final list is then displayed to the user.
Parameter tuning
The approach must tune many parameters such as the number of items retrieved, Two Tower similarity thresholds, neural network hyperparameters, and the value model weights. Bayesian optimization can automate online tuning but can be slow. Offline tuning can speed up trials if the offline metrics correlate reliably with online performance. Combining these methods helps converge on an optimal set of parameters that align with defined metrics.
Practical considerations
Implementation must handle real-time feature updates to track new user behavior. Embeddings for items need periodic refresh. Some users may have their second-stage results precomputed to reduce peak-time costs. The system should log every serving decision, user action, and outcome to fuel hourly or daily retraining. Quality assurance needs A/B testing to validate that new models improve engagement, retention, and integrity signals.
How would you handle cold-start items or new users?
New items have no historical engagements. One approach uses content-based features or author embeddings for similarity searches. The second-stage model can fallback to generic popularity or specialized signals until enough interactions exist. For brand new users, use demographic or platform-level trending signals for retrieval. The system transitions them to more personalized embeddings once adequate interaction data is collected.
How would you guard against recommendation loops?
Repeatedly showing the same items can narrow user exposure. Breaking loops requires randomization in retrieval or reranking. The system should maintain a rolling memory of recently shown items and penalize them if they appear too often. Item-level diversity or user-level session diversity ensures exposure to fresh content.
How would you reduce negative content exposure?
A specialized integrity score can flag items that show potential policy violations. These items get downranked or removed entirely in reranking. The second-stage model also predicts the probability of see_less or other negative actions, which contributes to a negative penalty in the final value model. This ensures negative content has limited visibility.
How do you continuously adapt to changing user interests?
Ingest new data on user behaviors hourly or daily. Retrain or fine-tune the Two Tower and the second-stage models to capture shifting trends. The multi-stage pipeline is easily adjustable by changing retrieval weights or the final value model weights. This rebalances item distributions for real-time adaptability.
How would you ensure scalability across billions of items?
Approximate nearest neighbor search systems scale embeddings for billions of items by sharding and using indexing structures such as HNSW. Precomputation reduces runtime inference for frequent users. Multi-stage ranking keeps the heavier computations on a smaller set of items. Distributed training on large GPU clusters handles the hourly or daily model updates.
How do you measure success?
Metrics include click-through rate, long-term user satisfaction, negative feedback reports, and retention. Online A/B tests track changes in these metrics to confirm significance. The system also monitors real-time latencies to ensure the multi-stage architecture does not exceed strict deadlines.
How would you handle user privacy concerns?
The system collects engagement data but only uses aggregated or anonymized signals for training. Personal identifiers are hashed. Sensitive data is never stored in plain text. The pipeline must follow data protection regulations and honor user opt-out requests. Logs are secured and audited to prevent misuse.
How do you manage real-time updates to embeddings?
Maintain a streaming pipeline that captures events. Retrain or fine-tune towers with these fresh samples. Items that get viral engagement can see embedding shifts that reflect popularity changes. The system can schedule frequent partial index rebuilds to keep similarity searches in line with the latest item embeddings.
How can you mitigate high computational costs?
Caching user and item embeddings is critical. Precompute as many user-item scores as possible. Compress or quantize embeddings to save memory. Prune the candidate list aggressively in the first-stage ranker to avoid applying the expensive second-stage model to all items. Periodically run offline experiments to see if simpler models match or surpass heavy models in performance.
How do you maintain system reliability?
Deploy the multi-stage pipeline in a fault-tolerant environment. Use load balancing across multiple servers for each ranking stage. Store embeddings in replicated databases. Monitor metrics like retrieval success rates, inference latencies, and throughput. Fallback to simpler retrieval sources if the main models degrade under load.
How do you incorporate new objectives or signals over time?
Add new labels or tasks to the second-stage model. Include new objectives in the value model. Retrain with multi-task learning so the system learns to balance multiple engagement targets. If online performance shifts, readjust the final weighting. Validate that the system does not compromise other important metrics.
How do you diagnose model biases?
Compare distributions of results across demographics. Examine fairness metrics for potential disproportionate exposure. Introduce fairness or representation constraints in the reranking stage. Use interpretability tools to uncover how the network weighs different features. Adjust training data or add bias correction signals if needed.
How do you handle rapidly evolving item catalogs?
Monitor item churn rates. If certain topics die out, remove them from retrieval sources. If new topics trend, push them with higher retrieval weights or specialized embeddings. The second-stage model re-calibrates daily or hourly with fresh data, so it quickly adapts to new item categories. This flow ensures coverage of the latest content.
How do you prevent user fatigue from repeated recommendations?
Add a user-based penalty for repeated authors or content categories. Track session-level variety. If the user sees too many of the same type of item, inject novelty from different genres. Switch up the recommended set after each refresh or scroll event. Combine older signals with short-term session signals so the pipeline balances consistency and variety.
How do you ensure consistent model quality during rapid iteration?
Maintain a stable environment for large-scale A/B tests. Roll out new models with canary deployments. Track changes in real time for critical metrics. Revert if metrics regress. Keep versioned training data sets. Document each model update with all changes in features or hyperparameters for quick debugging if performance drops.
How would you integrate ranking with existing product infrastructure?
Embed this pipeline into existing microservices. One service handles retrieval and maintains the approximate nearest neighbor indexes. Another service runs the first-stage ranker. Another runs the second-stage ranker. The final reranking logic resides in a dedicated post-processing layer that manages filters and rules. Containerize each layer for easy horizontal scaling.
How would you handle separate objectives like maximizing watch time or supporting a commerce feature?
Train specialized multi-task heads in the second-stage model for each objective. Merge these predictions into the final value model with tailored weights. If a user tends to watch long videos, shift the final weighting toward watch time. The system can store user preferences or context to factor them into the final reranking. Adjust weighting in real time if user behavior changes.
How do you future-proof this recommendation pipeline?
Continually improve embedding methods. Consolidate retrieval approaches into a few highly customizable frameworks. Introduce new data sources like textual or visual embeddings if they become critical. Keep the multi-stage design flexible so each stage can upgrade or swap out models independently. Regularly benchmark new architectures to ensure ongoing relevance.