
ML Case-study Interview Question: Multitask Neural Networks for Real-Time Personalized Social Feed Ranking


Browse all the ML Case-Studies here.
Case-Study question
A major social platform with over 2 billion users needs to build a real-time personalized feed-ranking algorithm. The feed includes new posts and older unread posts from Groups, Pages, and friends. Each post has signals like recency, content type, and user interactions (e.g., likes, comments). The platform wants to optimize for long-term user value by capturing multiple possible engagement behaviors (likes, comments, shares) without overwhelming users with irrelevant or repetitive posts. Propose a complete end-to-end ranking solution that handles real-time updates, predicts multiple types of engagement, consolidates them into a single ranking score, and ensures diverse content presentation. Explain how you would approach the system design, data pipelines, and core prediction models. Suggest practical methods to gather training signals or labels that align with user-defined “meaningful interactions.” Address how you would evaluate, tune, and maintain the models at scale.
Proposed scenario:
A user logs in and has thousands of new or unread posts to view. The system must fetch relevant posts, predict engagement probabilities, aggregate these predictions into a single ranking score, and finally reorder posts in real time. The end goal: a personalized feed that maximizes user satisfaction over the long term.
Detailed solution
Overview of the ranking pipeline
Start with an aggregator. The aggregator queries all potential posts (friends, Groups, Pages), filters out deleted or ineligible posts, and collects relevant features. Unread posts from previous sessions can be re-entered if not yet viewed. Then run a multi-stage ranking process, typically in multiple passes to reduce computational costs for massive volumes.
Core prediction model
Use multitask neural networks to predict different engagement probabilities. Each candidate post has features such as post type, relationship with the content author, recency, and embedding-based representations. For each user and post, predict probabilities for actions like comment or share.
Consolidation into a single metric
Combine the predicted probabilities into a single ranking score. A common approach is a weighted linear combination of predicted probabilities.
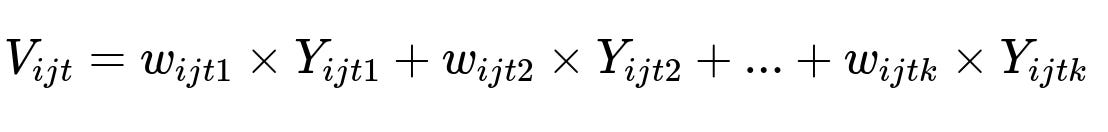
Where V_{ijt} is the final score for post i for user j at time t, Y_{ijtk} is the predicted probability for action k (like, comment, share), and w_{ijtk} is the weight for action k. Each weight can reflect user-specific preferences and global insights from surveys.
Pass-based ranking
Pass 0: Filter down to a more manageable set (e.g., top ~500 posts).
Pass 1: Use the richer model to score each candidate thoroughly, then rank them.
Pass 2: Re-check context (e.g., avoid showing too many videos consecutively).
Real-time updates
Ensure the aggregator system can quickly fetch the most current signals (like new reactions or new comments). Design your data infrastructure to update the user’s history so that repeated logins see content re-ranked with fresh inputs.
Training signals and evaluation
Collect user feedback through multiple channels: direct engagement (comment, share) and surveys that gauge content’s value. Align model outputs with these data sources. Periodically retrain models offline. Evaluate with A/B tests that measure improvements in user retention, self-reported satisfaction, or other success criteria.
Practical implementation details
Build a distributed system that runs inference on multiple machines in parallel for scale. Use embeddings for powerful generalization. Track user-item interactions for feature engineering. Regularly test for confounders to ensure each engagement type’s weight is meaningful.
Example code snippet (Python-like pseudocode)
import numpy as np
from my_neural_net_lib import MultiTaskModel
def rank_posts(user_id, candidate_posts, user_features, post_features):
model = MultiTaskModel.load("my_multitask_model_path")
predicted_engagements = []
for post in candidate_posts:
feats = extract_features(user_features[user_id], post_features[post.id])
# feats is a dict or vector of relevant inputs
probs = model.predict(feats) # returns dict: {'like': p1, 'comment': p2, ...}
score = 0.0
for action, weight in get_user_weights(user_id).items():
score += weight * probs[action]
predicted_engagements.append((post.id, score))
# Sort by descending score
ranked = sorted(predicted_engagements, key=lambda x: x[1], reverse=True)
return [p[0] for p in ranked]
Here, get_user_weights(user_id) retrieves personalized weights. The final ranking merges multiple probabilities.
How would you handle specific follow-up questions?
1) How do you prevent duplicate or repetitive content at the top of the feed?
Use a final pass to adjust scores with content diversity rules. If you see multiple items from the same source or the same format (video, text) in a row, reduce subsequent items’ rank incrementally so the feed remains varied.
2) How do you measure success in a long-term sense, beyond simple clicks?
Gather user feedback via surveys that ask if content is “worth time” or “meaningful.” Incorporate these signals into training labels. Use long-term metrics, such as daily active users or user retention. Run controlled tests, ensure improvements persist over time.
3) How do you handle real-time changes, like a user just engaging heavily with certain posts or authors?
Maintain an in-memory cache that logs recent user actions. When the system fetches next-rank candidates, incorporate those fresh signals (e.g., repeated comments on a certain Page’s posts) into the features. Keep partial model updates frequent or rely on real-time feature updates to nudge the aggregator’s decisions.
4) How do you tackle confounding effects when certain actions correlate with others?
Use causal or quasi-experimental approaches. If users who share often also comment more, naive weighting might distort the final score. Consider matching or doubly robust estimation. Conduct incremental tests that isolate the effect of each event type weighting. Examine user cohorts with similar traits to see how changes in weighting shift user behaviors.
5) How do you scale model training and online serving?
Distribute training across large clusters with high-performance frameworks. For serving, split candidate posts across multiple servers, run inference in parallel, then aggregate results. Invest in caching strategies and an efficient feature store. Minimize latency by using approximate top-k approaches in pass 0, then apply heavyweight models in pass 1.
6) What is your approach to ensuring each user sees the most relevant content without missing older high-quality posts?
Use unread bumping, so older but unseen posts reappear. Incorporate pass-based re-ranking. If a post accumulates new engagement after a user session, re-qualify it in the next session. Track user’s possible interest based on historical interactions.
7) How do you handle fairness or exposure concerns, such as small creators or lesser-known posts?
Apply constraints or calibrated scoring. Include a rule that ensures a portion of the feed is allocated to underrepresented content sources. Evaluate distribution metrics (e.g., share of feed from emerging content producers). Adjust weighting to balance user satisfaction with fairness objectives.
8) How do you monitor and mitigate negative feedback or harmful posts?
Include integrity checks before pass 0 (e.g., removing harmful content). Use specialized classifiers that flag problematic posts and reduce or remove them from ranking. Continuously log user feedback (hide post, spam reports). Incorporate those signals into future ranking logic.