
ML Case-study Interview Question: Designing an AI Group Travel Planner with LLMs and Real-Time Personalization


Browse all the ML Case-Studies here.
Case-Study question
You are working at a travel platform that wants to launch a new AI-based solution to help groups plan trips, handle real-time disruptions, and offer personalized recommendations. The platform wants a single interface where a user can invite an AI assistant into a group chat, ask it to retrieve relevant trip details from emails, suggest hotels or flights matching personal preferences, monitor flight changes, and provide on-the-fly itinerary updates. You are tasked with designing and building this end-to-end system. Propose a detailed solution covering architecture, data flows, AI models, and how to integrate it into existing mobile apps and chat interfaces.
Detailed Solution
Start by laying out the end-to-end flow. The platform needs a pipeline that merges group chat data, user preferences, and real-time booking or travel data. The solution architecture can be divided into data ingestion, AI service layer, and user-facing channels.
The data ingestion layer collects textual messages from group chats, existing bookings from email confirmations, and real-time info on flight changes or weather disruptions. Store this in a consolidated environment such as a cloud-based data lake, ensuring compliance with privacy policies.
The AI service layer handles natural language processing, recommendation logic, personalization, and real-time monitoring. Large Language Model (LLM) APIs interpret group chat discussions and summarize relevant requests, such as, “need pet-friendly hotel with a rooftop pool.” Another module predicts flight price trends based on historical data and real-time feeds. A dynamic service component monitors flight delays or cancellations and cross-references local events or weather changes to provide new suggestions on demand.
The user-facing channel can be integrated via messaging platforms like WhatsApp or iMessage. A back-end system listens for mentions of the AI assistant’s handle and routes the request to the LLM-based interface, which returns suggestions in the group chat. Connect it to the travel platform’s app so users can instantly see recommended flights, hotels, or activities. If an itinerary is confirmed, the assistant updates everyone’s timeline and handles change requests.
Use a personalization approach to improve suggestions. For each user, keep track of prior bookings, lodging preferences, and activity types. Vector embedding methods can match user preferences to hotels or flights with similar attributes.
Below is an example Python snippet showing how you might integrate a large language model to summarize a group’s chat context. It uses a pseudo-LLM library for demonstration:
import llm_api
def summarize_group_chat(messages):
conversation_text = " ".join(messages)
prompt = f"Summarize these group travel preferences: {conversation_text}"
summary = llm_api.generate_text(prompt)
return summary
This code gathers recent chat messages, constructs a prompt, and gets a summary. In practice, you would attach user IDs, apply role-based security, and handle rate limits for calls to your model.
Core Formula for Embedding-Based Similarity
When matching a user’s preferences with a hotel’s attributes, you can embed both into vector space and compute similarity. A common measure is cosine similarity.
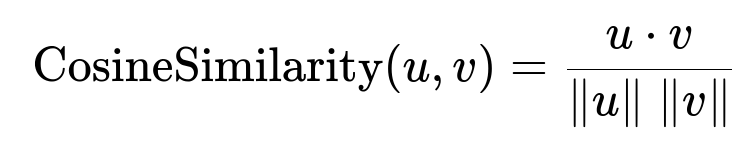
Where u and v are embedding vectors representing user preferences and a hotel’s feature set, u dot v is their dot product, and ||u|| and ||v|| are their Euclidean norms. Higher similarity values indicate better matches.
Below that formula, integrate a machine learning-driven flight price prediction model. Train it on historical flight pricing data, route popularity, seasonal effects, and current booking trends. A time series model or a regression-based approach is common. Output a predicted price range for future travel dates, enabling the platform to recommend best times to book.
Make sure to handle scalability. LLM queries can be slow, so cache repeated requests and maintain an efficient indexing strategy for search queries. A streaming architecture can ingest real-time flight changes or group chat updates. A microservices design lets each component handle a distinct function (summarization, recommendation, flight price prediction).
Keep an eye on data governance. Secure group chat data with user-level encryption. For each user, apply strict permission checks so they only see relevant or shared information.
Implementation Example
If you want to deploy real-time notifications when a flight is delayed or canceled, set up a listening service that polls or receives flight status webhooks. Suppose flight status is updated via an external provider’s API:
def notify_disruption(flight_id, new_status):
if new_status in ["delayed", "canceled"]:
# Query LLM to generate alternative suggestions
alternate_flights = llm_api.generate_alternatives(flight_id)
# Send a message to the group chat with new suggestions
send_message_to_chat(alternate_flights)
Explain in code comments how it fetches a list of new flights or possible ground transport. Then the function posts an alert to the group chat.
Follow-Up Question 1
How would you handle out-of-scope queries and prevent the AI assistant from returning irrelevant or inaccurate information?
Answer and Explanation
Filter each user query through a domain classifier that checks if the question is about travel. If not, respond with a polite fallback message. For large language models, apply a system prompt that constrains responses to only travel-related content. Maintain guardrails for uncertain or missing data. If the LLM is not confident about an answer, have it default to suggesting standard resources or disclaimers. In production, store logs of out-of-scope queries to improve the classifier by retraining it to identify new patterns of user requests.
Follow-Up Question 2
How do you ensure reliable and fast conversational experiences, given that LLM calls can be expensive and slow?
Answer and Explanation
Cache frequent queries. If many travelers keep asking about “hotel with a rooftop pool in Italy,” store the LLM-generated response for a certain duration. Precompute summarizations of older chat content. Apply token-level optimization or use smaller, specialized models for narrower tasks like real-time flight updates. Use an asynchronous, event-driven architecture so user requests don’t get blocked while waiting for a large response. Horizontally scale the LLM service by distributing queries across multiple nodes or GPU resources. Monitor throughput with a load balancer that directs requests where capacity is available.
Follow-Up Question 3
How can you incorporate user reviews in hotel recommendations, and how do you filter out spam or irrelevant reviews?
Answer and Explanation
Retrieve a hotel’s set of reviews and transform them with a summarization pipeline. An LLM model can convert raw review text into short highlights. Compute a sentiment score by analyzing the frequency of positive or negative terms. Filter out spam by training a review-classification model on textual patterns of inauthentic entries. If the confidence in authenticity is low, exclude that review from the summarized feedback. For scaling, batch-process reviews daily and update cached summaries. If new reviews appear, incrementally re-run summarization on that subset to keep data fresh.
Follow-Up Question 4
How do you personalize suggestions for each traveler in a group, especially when people have conflicting preferences?
Answer and Explanation
Store each person’s preference vector in a user profile database. Generate a combined group embedding by averaging or clustering individual preferences. Compare the group embedding against recommended destinations or hotels. If individuals have strong outlier preferences, surface a few suggestions tailored to them separately. Show the group the main recommendation plus an optional alternative. Log acceptance or rejection so future suggestions adapt in real time. For conflicting preferences, show data on trade-offs (price vs. location, pet-friendly vs. non-pet-friendly) so the group can make informed compromises.
Follow-Up Question 5
How do you handle the privacy and security of user data when integrating chat logs, email details, and booking confirmations?
Answer and Explanation
Mask or tokenize sensitive information on ingestion. Implement role-based access controls so that only authorized systems can read raw messages. Encrypt chat logs at rest and in transit using recognized security standards. Use secure APIs for booking confirmations so no unencrypted email data is stored on the platform’s servers. For compliance, maintain an audit log of data access, including timestamps and user identifiers. Inform users that the AI assistant will parse their chat or emails only to improve trip planning. Give them the option to opt out at any stage or limit data usage.
Follow-Up Question 6
How would you measure success and refine the system?
Answer and Explanation
Track metrics for query resolution time, user satisfaction scores, booking conversion rates, average time spent finalizing a group trip, and cost of LLM usage. Conduct A/B tests with different summarization strategies or recommendation models to see which yields faster bookings or fewer user complaints. Monitor user feedback for inaccurate or repetitive answers, then retrain models to reduce error rates. Evaluate how often the assistant successfully handles disruptions like flight cancellations. If too many rebooking requests fail or time out, optimize that pipeline.
Follow-Up Question 7
Which technical challenges arise if you scale this solution from thousands to millions of daily active users?
Answer and Explanation
Increased traffic can overload LLM inference endpoints, so you need load balancing and GPU scaling. Storage costs balloon if chat logs and user profiles grow significantly, so adopt sharding or a managed distributed database. Real-time flight tracking for millions of travelers can stress any external APIs or message queues, so ensure robust retry policies and circuit breakers. If large volumes of user data push boundaries on data privacy, invest in higher-level encryption and secure key management. Monitor concurrency in group chats to avoid race conditions in rewriting itineraries.