
ML Case-study Interview Question: Explainable ML for Triaging E-commerce Fraud Orders


Browse all the ML Case-Studies here.
Case-Study question
An e-commerce platform faces suspicious credit card orders that might be fraudulent. They want a binary classification system to distinguish fraudulent orders from legitimate ones. The solution must handle three categories: Fraud, Non-Fraud, and a middle region of uncertain cases sent to human reviewers. The leadership demands explanations for each automated decision to assist the manual review process. Design a fraud detection pipeline using machine learning, describe how you would train and evaluate it, and explain how you would integrate model interpretability techniques for local and global explanations.
Detailed Solution Approach
Treat this as a supervised classification problem with labeled historical orders. Split the data into Fraud and Non-Fraud labels, and place uncertain samples into a third set for manual escalation. Use features like account age, billing-to-shipping address match, previous order count, and others relevant to suspicious activity. Train a predictive model such as a tree-based classifier or a neural network.
Model performance must be measured in terms of precision and recall for Fraud detection. Avoid high false positives because that annoys genuine customers, and avoid high false negatives because that can lose money.
Use an explainability framework that supports local (per order) and global (across all orders) interpretations. Global explanations help the data science team verify overall feature importance. Local explanations help human reviewers see why a particular order is flagged.
Model Selection and Training
Many start with logistic regression or decision trees. For logistic regression, an interpretable global view is straightforward because the model is a weighted sum of features. A typical logistic regression prediction for probability p can be shown by:
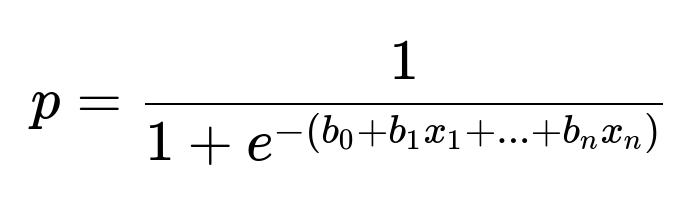
Here, p is the predicted probability of Fraud. b0, b1, ..., bn are learned coefficients, and x1, x2, ..., xn are input features. Large positive coefficients for a feature mean that feature increases the likelihood of Fraud, and large negative coefficients do the opposite.
Decision trees also have a direct explanation path from root to leaf. Random forests or gradient boosting frameworks can improve accuracy but require more intricate explanation methods. After initial hyperparameter tuning, evaluate with cross-validation and measure classification metrics such as AUC or average precision.
Introducing Explanation Methods
Permutation Importance checks how shuffling each feature affects model performance. For correlated features, it may underestimate importance because one feature can compensate for another.
LIME (Local Interpretable Model-Agnostic Explanations) perturbs one sample’s features and trains a simpler model to mimic the complex model’s decision boundaries near that sample. This local surrogate reveals which feature changes drive the decision for a single order. However, LIME can produce variability in the presence of redundant features.
SHAP (SHapley Additive exPlanations) uses ideas from game theory to measure each feature’s contribution. It often yields consistent local explanations and can also aggregate results to give a global perspective. Tree-based models can be explained very efficiently with specialized SHAP implementations.
Integrating Human Review
Some orders remain uncertain. Route them to a manual queue. Provide a local explanation so reviewers see which features contributed most to classifying an order as Fraud. For example, if no 2-factor authentication is present, or the billing city doesn’t match the shipping city, highlight those as key risk signals. This transparency builds trust in the model.
Example Code Snippet
A simple Python snippet using scikit-learn could look like this:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
data = pd.read_csv("orders.csv")
X = data.drop("fraud_label", axis=1)
y = data["fraud_label"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = DecisionTreeClassifier(max_depth=5, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
Train separate models or a single model with a threshold for uncertain outputs that get escalated. Then integrate LIME or SHAP to generate local explanations for each order.
Potential Follow-Up Question 1
How do you handle correlated features in permutation-based importance?
Answer: Correlated features lead to confusion in permutation importance because shuffling one feature at a time may not degrade performance if the same information is captured by another feature. Group features into sets or permute them jointly. Another approach is to use SHAP or partial dependency plots, which better handle shared information between features.
Potential Follow-Up Question 2
Why would you pick SHAP over LIME in certain scenarios?
Answer: SHAP assigns consistent importance values anchored in coalitional game theory. It fairly distributes credit among features for each prediction and shows stable results across many samples. LIME generates local surrogates via randomized perturbations, so it can produce less stable explanations if features are highly correlated or if the data manifold is complex. SHAP also offers a fast tree-based explainer.
Potential Follow-Up Question 3
How would you address model bias in Fraud detection?
Answer: Check for bias by slicing data on sensitive attributes and inspecting metrics. Compare false positive and false negative rates across demographic groups. Use fairness frameworks or specialized constraints like demographic parity or equalized odds. If bias is found, rebalance the dataset or adjust training with reweighing or adversarial methods. Evaluate interpretability across groups to ensure the model is consistent.
Potential Follow-Up Question 4
How do you handle real-time scoring and updates to the model?
Answer: Use a pipeline that loads the trained model into a service endpoint. When a new order arrives, extract the relevant features, apply any transformations, and run the model inference. Capture feedback from the fraud investigation team and continuously retrain the model as fraud patterns evolve. Consider a feature store for consistent transformations. Monitor model drift by analyzing changing data distributions.
Potential Follow-Up Question 5
What kind of logging and monitoring would you implement?
Answer: Log prediction probabilities and final classification decisions for each order. Track feedback loops when manual reviewers override the decision. Keep metrics over time (daily or weekly) to detect shifts in patterns or performance drops. Implement alerting when certain thresholds (like false positives or recall) go out of range. Logging helps with auditing and regulatory requirements for explainable decisions.