
ML Case-study Interview Question: RAG-Powered Natural Language QA for Long-Form Video Transcripts


Browse all the ML Case-Studies here.
Case-Study question
You are given a long-form video platform that hosts user-generated content like lectures, presentations, corporate meetings, and events. A new feature is needed to allow end-users to ask natural language questions about a video and immediately receive text answers plus clickable timestamps in the video. The platform cannot rely on outside metadata or visual analysis. You only have automated speech-to-text transcripts. How would you design and implement a system that can:
Efficiently retrieve and rank relevant text segments from a large transcript to answer questions.
Handle various question types (high-level summaries, details about specific speakers, timestamps).
Identify speaker names within the transcript, despite no additional user-supplied speaker data.
Provide accurate quotes or timestamps of relevant parts of the video transcript.
Suggest additional related questions to keep viewers engaged.
Detailed solution
Relying on text-only transcripts of each video requires special handling of chunking, speaker detection, and retrieval augmentation. A retrieval augmented generation (RAG) pipeline can handle these tasks effectively.
RAG overview
RAG combines vector search with a large language model (LLM). It retrieves relevant text chunks from a vector database and appends them as context to the LLM’s prompt for final text generation. The LLM’s output is thus grounded in a specific text source, reducing hallucinations and ensuring domain relevance.
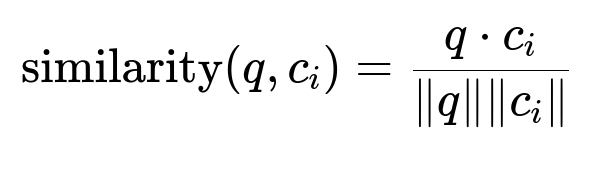
Here, q is the embedding of the query, and c_i is the embedding of the i-th text chunk. This formula measures the cosine similarity between the query and chunk embeddings. The top matching chunks become the augmented context.
Transcript chunking with bottom-up processing
Raw transcripts can be long. Chunk them into segments of 100–200 words to capture short context. Summarize larger 500-word segments to produce a middle layer. Merge these summaries to build a high-level description of the entire video. Register the original smaller chunks, the mid-level summaries, and the top-level description into the vector database. This multi-layer structure handles both detailed and broad questions.
Speaker identification without facial recognition
Clustering audio segments by speaker ID yields numeric labels. Identifying which name belongs to which label is done by analyzing transitions. The transcript around the change between two speakers is fed to an LLM multiple times with partial masking. The model votes on whether a name in these transitions refers to the new speaker. This multi-prompt voting process reduces errors. When enough votes converge on the same name, assign that name to the speaker ID. Names remain blank if certainty is too low.
Locating relevant quotes and timestamps
Answering the user’s question and finding exact quotes from the transcript can overload a single LLM prompt. Use two prompts:
Generate an answer using the retrieved text or summaries.
Embed the final answer, compute similarity against the retrieved chunks, and prompt the LLM again with only the text that aligns closely with the answer. Extract direct quotes plus their start and end timestamps. Present the viewer with these clickable segments.
Suggesting new questions
To propose additional questions after one has been asked, embed the answer and retrieve context neighbors. Ask the LLM to generate related questions that align with the same or closely overlapping context. Instruct it to avoid unanswerable questions and not to repeat details already given.
Example code snippet for chunk registration
import openai
import numpy as np
def embed_text(text):
# Pseudocode call to embedding API
return openai.Embedding.create(input=text).data[0].embedding
def register_transcript_chunks(chunks, db):
for chunk in chunks:
text_embedding = embed_text(chunk['text'])
db.add_record({
'text': chunk['text'],
'embedding': text_embedding,
'start_time': chunk['start'],
'end_time': chunk['end']
})
Explanation in simple terms: read each transcript chunk, get its embedding, and store the embedding plus the original text with the timestamps.
Potential follow-up questions
How would you ensure users cannot ask about private or restricted content?
Implement an access-control layer before retrieving any data. Generate a user-specific filter to ensure only chunks from transcripts the user is authorized to view are included. LLMs only see the filtered context.
Why not store entire transcripts in a single chunk for retrieval?
Memory, speed, and accuracy. Large chunks degrade retrieval granularity and slow vector operations. Small chunks improve precision. Too many small chunks can lose context, so a multi-level approach balances detail and broad coverage.
How would you handle transcripts containing multiple languages?
Produce language-specific embeddings, or unify everything with a multilingual embedding model. Language identification can route each chunk to the correct embedding pipeline. The LLM can handle answers in the user’s requested language if it supports multilingual outputs.
How would you address concerns around hallucinated speaker names?
Use the multi-vote approach in speaker detection. If the model cannot find enough votes, mark the speaker as unknown. Regular audits on a random sample of transcripts can highlight systematic misidentification. For high-stakes cases, manual verification might be required.
What if the user requests details not found in the transcript?
The LLM should respond that the information is not available in the transcript. RAG reduces hallucinations by exposing the LLM only to verified transcripts. If context is missing, the LLM cannot fabricate it.
How would you scale this system across thousands of videos with real-time requests?
Leverage a high-performance vector database and horizontal scaling with chunk-level sharding. Cache frequent or recent queries. Precompute and store embeddings for each new video. Use distributed retrieval services with load balancers, and optimize embedding lookups to maintain low latency.
Why generate both the final answer and the relevant timestamps separately?
It reduces cognitive load on the LLM. Focus on a coherent answer first. Then, embed the answer and locate exact quotes for time offsets. Trying to do both at once can exceed the LLM’s context window and diminish reliability.
How could you expand beyond audio transcripts to incorporate visual context?
Apply image recognition or visual captioning for keyframes or slides. Embed these text descriptions. Combine them with the transcript chunks to provide richer context for the LLM. This approach can address questions about on-screen diagrams or facial expressions.
How would you optimize the summarization step in the bottom-up approach?
Experiment with different summary lengths or specialized summarization prompts for technical domains. Fine-tune summarization models for domain-specific transcripts (for instance, medical or financial). Evaluate how well summaries answer user questions in test sets, adjusting the approach if coverage or precision is insufficient.