
ML Case-study Interview Question: Distilled Hybrid Seq2Seq Models for Efficient On-Device Grammar Correction


Browse all the ML Case-Studies here.
Case-Study question
A major tech organization wants to implement on-device grammar correction for a new smartphone keyboard. They have strict memory and latency constraints, but require high-quality grammar suggestions. They need a solution that can handle partial sentences in real-time, without sending any text to external servers. Design a complete approach, including data collection strategy, model architecture, training methods, deployment considerations, and a mechanism to transform corrected sentences into specific suggestions. Propose the entire solution in detail.
Detailed solution
Model Architecture
A compact sequence-to-sequence neural network uses a Transformer-based encoder and an LSTM-based decoder. The encoder processes the input text, generating contextual embeddings for each token. The decoder uses those embeddings to produce a grammatically corrected sequence. The hybrid design balances accuracy with the low latency needed on a smartphone.
Shared embedding reduces file size by using the same parameters for input and output embeddings. Factorized embedding further decouples embedding dimension from the vocabulary size. Quantization converts 32-bit weights to 8-bit, minimizing storage and memory usage.
Training Data Collection
A large external grammar correction system running on powerful servers generates <original, corrected> pairs from vast text corpora. This step is called hard distillation. The large system predicts grammar fixes for many public English sentences, creating a new dataset oriented toward on-device usage.
Handling partial sentences requires labeled examples of prefixes. A cloud model is trained to correct both full sentences and prefixes. Its predictions create fresh prefix-correction pairs. Finally, the small on-device model trains on the combined set of full-sentence and prefix pairs, enabling correction suggestions when the user has not finished typing.
Handling Partial Sentences
A prefix is deemed grammatically correct if it can be extended into a valid sentence. If no valid completion exists, the prefix is considered incorrect. This distinction ensures the model can correct errors in incomplete messages, which is critical in chat scenarios where users omit final punctuation.
Converting Corrected Sentences into Suggestions
The model outputs a full corrected sentence. The system underlines possible errors and suggests replacements. This requires aligning the user’s original text with the model’s corrected output via minimal edit distance.
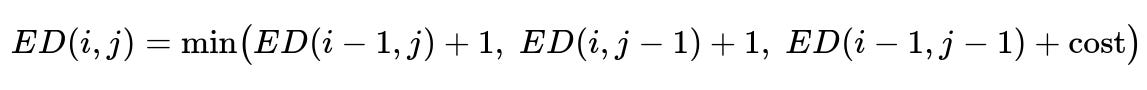
ED(i, j) is the minimal edit distance between the first i characters of one string and the first j characters of the other. cost is 0 if the characters match, or 1 otherwise. The alignment is recovered by tracing the dynamic programming table. Insertions and deletions become replacements in a user interface, such as “replace ‘puts’ with ‘put in.’”
Example Python Code for Edit Extraction
def suggest_edits(original, corrected):
# Build DP table for Levenshtein distance
len_o = len(original)
len_c = len(corrected)
dp = [[0]*(len_c+1) for _ in range(len_o+1)]
for i in range(len_o+1):
dp[i][0] = i
for j in range(len_c+1):
dp[0][j] = j
for i in range(1, len_o+1):
for j in range(1, len_c+1):
cost = 0 if original[i-1] == corrected[j-1] else 1
dp[i][j] = min(dp[i-1][j] + 1, # deletion
dp[i][j-1] + 1, # insertion
dp[i-1][j-1] + cost) # substitution
# Trace back to get edits
i, j = len_o, len_c
edits = []
while i > 0 or j > 0:
if i > 0 and dp[i][j] == dp[i-1][j] + 1:
i -= 1
elif j > 0 and dp[i][j] == dp[i][j-1] + 1:
j -= 1
else:
if original[i-1] != corrected[j-1]:
edits.append((i-1, j-1))
i -= 1
j -= 1
edits.reverse()
return edits
This logic identifies mismatched positions for user-facing replacement suggestions.
Deployment and Latency
The final model is just 20 MB, runs inference in about 20 ms on a modern phone CPU, and does not upload keystrokes to any server. This maintains privacy while delivering near-instant grammar suggestions.
Potential Follow-Up Questions
How do you handle out-of-vocabulary words during inference?
The model includes a large vocabulary, but rarely encountered words may still appear. The system splits unknown words into subword tokens. Shared embeddings help handle these efficiently, preventing major drops in accuracy and ensuring the model can still align them in context.
Why choose a Transformer encoder with an LSTM decoder instead of a full Transformer or full LSTM?
A pure Transformer might exceed on-device memory or latency constraints. A full LSTM might be less accurate. The mixed approach harnesses the Transformer’s superior context encoding while keeping the decoder footprint smaller. Shared embeddings and factorized embeddings fit well into this architecture.
Could you have used knowledge distillation with a simpler method?
Hard distillation is particularly effective because the large cloud system directly creates labeled pairs for the smaller model’s domain. Classic teacher-student distillation that only matches model logits could work but might not align the on-device data distribution as precisely.
How do you verify correctness for sentence prefixes?
A heuristic checks whether a prefix can be continued without errors. If the model can produce a valid full sentence from a prefix, that prefix is correct. If no valid completion exists, it is incorrect. The training data captures both outcomes, so the small model learns to correct partial text when needed.
Could you improve performance if you allowed partial offloading to the cloud?
That might help quality but would compromise privacy. The requirement is strict on-device correction, which keeps text local and eliminates network latency. This approach meets that constraint at acceptable performance levels.
Why is factorized embedding essential for large vocabularies?
It decouples the main hidden dimension from the size of the vocabulary projection. A non-factorized approach would scale parameter counts with the vocab size. Factorizing preserves a large subword vocabulary for coverage, while limiting total parameters to stay within memory limits.