
ML Case-study Interview Question: Scalable Personalized Ad Optimization with Contextual Bandits & Importance Weighted Regression.


Browse all the ML Case-Studies here.
Case-Study question
A major tech company manages a large-scale online retail platform and needs to optimize marketing decisions at the customer level for paid media channels. Each day, millions of user-level decisions must be made on whether to show an ad or not, how much to bid for the ad space, and how to adjust strategies based on real-time feedback. Propose a contextual bandit approach to make these decisions efficiently. Specifically, describe how you would set up the problem (defining context, actions, rewards), design the reward estimation process, address bias in observational data, and choose an exploration algorithm. How would you ensure that the system can operate at scale with continuous updates to the model?
Detailed Solution
Contextual bandits can optimize personalized marketing treatments by combining two components: a reward estimator and an exploration algorithm.
Explain the steps:
(1) Problem Setup Use a contextual bandit framework with:
Context x capturing user attributes such as browsing history and demographics.
Actions a representing whether to display an ad or not (or multiple ad variants).
Reward r representing profit or revenue generated if the user converts.
(2) Reward Estimation Model the conditional expected reward for each action. One way is to train a separate regressor per action, f(x, a). Another way is to combine x with action-dependent features x_a and learn a single model parameterized by theta. Naively fitting these regressors to minimize mean squared error can cause bias when certain actions are favored more frequently, reducing data coverage elsewhere.
(3) Correcting for Bias Importance Weighted Regression (IWR) is used to remove bias introduced by uneven propensities of actions in historical or ongoing data collection. The main formula for importance weighted mean squared error is:
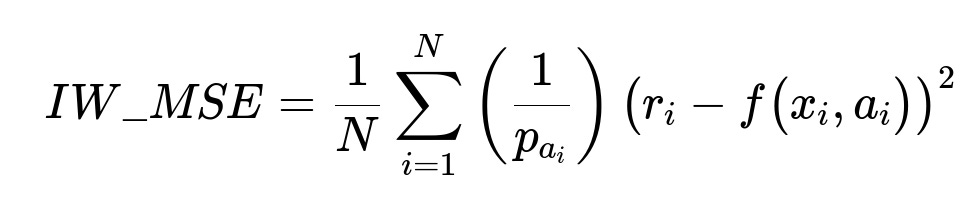
Here, p_{a_i} is the propensity of having chosen action a_i for context x_i. When p_{a_i} is small, the sample is given a higher weight.
(4) Exploration Algorithms An explorer uses the learned reward estimates to generate a probability distribution over actions. The simplest is epsilon-greedy, which picks the best action most of the time and randomly explores otherwise. More advanced methods like Softmax or SquareCB assign probabilities proportional to estimated rewards, balancing exploration and exploitation more fluidly.
(5) Scalability Implementing this approach at scale requires:
A fast data pipeline to collect new rewards.
Near real-time updates to the model parameters.
Efficient libraries (for example, an online active learning library) that handle large volumes of data with incremental training.
(6) Practical Deployment Maintain a feedback loop:
For each user context, produce action probabilities.
Stochastically choose an action based on these probabilities.
Observe the reward.
Update the model using importance weighted regression or cost-sensitive classification.
How would you handle multiple actions or creative variants?
A system with many possible ads or creative treatments can still follow the same procedure. Represent each ad variant with its own parameter set or expand the feature vector to include ad-specific attributes. Use the same approach of reward estimation with inverse propensity weighting and an exploration strategy that scales over large action sets.
How would you tackle delayed rewards?
Often users may convert hours or days after an ad impression. One approach is to build a separate model to forecast eventual conversion or profit. Feed the predicted reward into the contextual bandit model. Continuously update with real outcomes once they become known.
What about cold-start scenarios?
When there is little data for certain user segments or new ad treatments, the system can default to uniform exploration or a prior-based approach. Over time, data collection fills the gaps, and the bandit algorithm adjusts accordingly.
How do you ensure unbiased reward estimation in production?
Use inverse propensity scoring or doubly robust methods to reweight logged data. Log the propensities and actions to correct for any distributional shifts. Periodically audit the model's predictions and actual outcomes for signs of bias.
How would you manage hyperparameters or tuning?
Techniques include:
Using a hold-out set or offline evaluation with counterfactual estimators (IPS or doubly robust).
Tuning exploration parameters (epsilon, temperature in Softmax, or parameters in ensemble methods) by measuring cumulative reward or other internal metrics.
How would you evaluate this approach offline?
Use counterfactual policy evaluation:
Logged data has context x_i, action a_i, reward r_i, and logging probability p_{a_i}.
Estimate the policy's expected reward with an IPS estimator: E[R_policy] = (1/N) * sum( r_i / p_{a_i} ) for all i where the policy chooses action a_i. Compare multiple candidate policies or hyperparameters before online deployment.
How do you handle non-stationary environments?
Implement continuous exploration and frequent model updates. Methods like Softmax or ensemble-based explorers keep sampling different actions to detect changes. Adaptive discounting of older data can help if user behavior shifts over time.
How can you address cost or budget constraints?
Add cost factors into the reward definition. Instead of only tracking revenue, define reward = revenue - cost. The same contextual bandit techniques apply. If the cost is high, the model may learn to reduce expensive exposures that do not yield enough benefit.
How would you structure the engineering pipeline?
Store and stream user events in real time. Train or update the reward estimators with importance-weighted methods incrementally. Serve the model behind an API that returns action probabilities. Log chosen actions, probabilities, and rewards. Schedule periodic retraining or continuous online learning, depending on the tooling.
What if there are privacy concerns about storing user data?
Anonymize or hash identifiers. Aggregate sensitive features. Apply differential privacy or stricter security measures if needed. The bandit framework still works with high-level or obfuscated features.
How would you integrate contextual bandits with existing rules-based marketing?
Blend rules-based constraints (such as never serving certain ads to minors) into the action space or the reward function. The bandit model can then select from the remaining feasible actions. Alternatively, apply policy constraints that override or filter out invalid actions before sampling from the bandit.