
ML Case-study Interview Question: Unifying Customer Records: Rule-Based & ML Entity Resolution Techniques


Browse all the ML Case-Studies here.
Case-Study question
A major retail organization aims to consolidate customer records from multiple internal systems into a unified profile. Each system stores unique identifiers (for example, PID, SID, TID), but data often contains missing IDs and inconsistent text fields (names, addresses). The team wants a robust entity resolution approach to match or merge records referring to the same customer. The data ranges from highly consistent identifiers (like phone, SSN) to inconsistent text entries (customer names, addresses). Propose an end-to-end solution that addresses the entity resolution challenge using both rule-based approaches and machine learning methods. Explain how you would handle data cleaning, record linking, fuzzy matching, model selection, and performance evaluation. Include reasoning about potential trade-offs, data quality issues, and how you would communicate results to business stakeholders.
Provide all relevant details, code snippets, and any mathematical formulas you might use for measuring similarity or distance.
Detailed Solution
Overview of the Approach
Focus on two main methods to unify records: rule-based processing and machine learning approaches. Rule-based methods can be faster when data has reliable identifiers. ML-based methods can capture patterns in text fields or partial matches. These methods often work best when combined with thorough data cleaning, strong feature engineering, and well-chosen similarity metrics.
Data Preprocessing
Parse raw data to ensure consistent formats. Standardize addresses using external APIs or libraries. Convert names to canonical forms by removing punctuation, lowercasing, and lemmatizing. Handle duplicates, nulls, and outliers. Split data into training and validation sets when building ML models.
Rule-Based Matching
Define logical sequences of checks on reliable fields. If a primary key field is present, use that. When the primary key is missing, rely on secondary identifiers. Fall back to generating a new ID if no match is found. This approach can be transparent to stakeholders and simple to maintain when the data has dependable identifiers.
Machine Learning Matching
Build a supervised model to classify pairs of records as match or non-match. Vectorize the text fields (names, addresses) by transforming them into embeddings or using specialized libraries. Train a classifier (Logistic Regression, Naive Bayes, or Transformer-based models) to predict whether two records represent the same entity. Leverage a feedback loop with domain experts to refine the model.
Core Distance Metric Example
Jaro-Winkler or Haversine distance are often used in entity resolution. One common approach for geographic data is Haversine to measure distance between lat-long pairs. Here is the Haversine formula in big font:
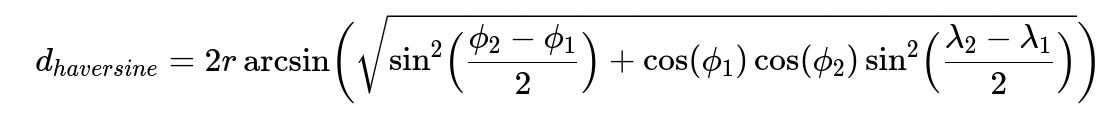
Where r is Earth’s radius, phi_1 and phi_2 are latitudes, and lambda_1 and lambda_2 are longitudes in radians.
Feature Engineering
Derive text-based features from names (phonetic encodings like metaphones). Compute distance-based features for addresses (Haversine between geocodes). Use string similarity functions on short text fields. Combine all features into a single feature vector for classification.
Model Training
Train the model on labeled pairs. Conduct hyperparameter tuning using cross-validation. Evaluate performance with precision, recall, and F1 score. Perform error analysis to see where the model fails. Consider interpretability techniques (for example, SHAP) to explain outcomes for business stakeholders.
Example Code Snippet (Python)
import recordlinkage
from recordlinkage import Compare
indexer = recordlinkage.Index()
indexer.block('metaphone_name')
candidate_links = indexer.index(dfA, dfB)
compare = Compare()
compare.string('name', 'name', method='jarowinkler', threshold=0.8, label='name_match')
compare.geo('lat', 'lon', 'lat', 'lon', radius=6371, method='haversine', label='geo_match')
features = compare.compute(candidate_links, dfA, dfB)
classifier = recordlinkage.LogisticRegressionClassifier()
classifier.fit(features, training_labels)
matches = classifier.predict(features)
Here, metaphone_name is a feature-engineered column for blocking. The logistic regression classifier scores candidate pairs as match or non-match. Real implementations might use more advanced models.
Model Deployment
Deploy the trained model or rule-based pipeline via an internal API or batch workflow. Expose endpoints where new records are scored in real time. Track logs and metrics to detect data drift or performance deterioration.
Monitoring and Maintenance
Monitor confidence scores and false positives or false negatives. Implement a feedback loop to retrain the model or fine-tune rules as new data arrives. Analyze mismatch patterns for continuous improvement.
Follow-up question 1
How would you handle label scarcity when training an ML-based entity resolution model?
A limited number of labeled matches can reduce the model’s reliability. Data augmentation strategies can expand labels. Semi-supervised or active learning methods can request human review only for uncertain pairs. Create synthetic matches by duplicating certain records with small modifications (like slight spelling changes). This helps the model learn typical variations in names, addresses, and other fields. Ensure representative coverage of all relevant data segments to prevent bias.
Follow-up question 2
How would you address interpretability concerns from regulatory teams?
A black-box model can hinder trust. Use methods like LIME or SHAP on classification outcomes. Provide a local explanation for each pair. For example, indicate that a match was primarily driven by name similarity and lat-long distance. Keep a metadata record of these explanations for audits. For simpler interpretability, maintain a rule-based subsystem as a fallback. Present quantitative proof of improvement in precision-recall to justify the ML method.
Follow-up question 3
How would you account for extreme data inconsistency or misspellings?
Use robust text similarity metrics or specialized libraries (like phonetic encoding). Train models on real-world noisy data so they learn typical transformations (like reversed name segments or missing punctuation). Incorporate external reference data for addresses or names to cross-check. Combine multiple text fields for redundancy. For instance, if city name is badly misspelled, rely on state or zip codes to guide the match. Maintain thresholds that reflect acceptable edit distances or partial matches.
Follow-up question 4
How would you incorporate structured and unstructured data, such as free-form notes or comments?
Convert unstructured data with natural language processing techniques. Extract meaningful tokens or embeddings that represent relevant keywords. Combine them with structured fields in a feature vector. For instance, a comment mentioning “moved from old address” can help label one record as outdated. Use topic modeling or entity extraction to identify crucial references in these notes. Periodically retrain or refine the NLP pipeline as vocabulary and product lines evolve.
Follow-up question 5
How would you manage performance at scale with millions of records?
Use blocking or indexing to reduce pairwise comparisons. Only compare records that have a high chance of belonging together (like similar zip codes or phonetic name keys). Parallelize steps in the pipeline with distributed frameworks (Spark, Dask). Use approximate nearest neighbor search for embedding-based methods. Profile your code and memory usage to optimize indexing, partitioning, and classification tasks. Precompute frequent transformations (like metaphone or partial string distances) to save time during repeated runs.
Follow-up question 6
What specific metrics would you track to communicate effectiveness to leadership?
Show precision, recall, and F1 score. Report confusion matrix results to identify mismatch patterns. Track how many duplicates were reduced or how many errors the system prevented. Highlight cost savings from avoiding manual merges. Present results by category (for example, unique IDs vs. fuzzy name matches). Convey confidence intervals for performance to manage expectations. Use a dashboard to display real-time metrics like daily match rates, false match counts, and new entity creation rates.