
ML Case-study Interview Question: Boosting Job Recommendation Relevance with CNN-Based User Activity Embeddings


Browse all the ML Case-Studies here.
Case-Study question
A large professional platform wants to improve the relevance of job recommendations for its users. They store each user’s recent activity (such as saving, applying, or dismissing jobs) along with job embeddings that encode each job’s content. They aim to transform a user’s sequence of activities into a single embedding that represents that user’s most recent preferences. They wonder which approach to use: a simple average-based embedding, a geometrically-decaying weighted embedding, or a learned embedding from a neural network aggregator.
They also worry about data imbalance (very few negative actions) and the fact that many users have short activity histories. The team suggests injecting random negative examples and using a sliding-window approach to handle long histories. They want you to outline a suitable modeling strategy, describe the training pipeline, and detail how to serve the embeddings in production. Explain how to handle multi-action types, how to tune the decay factor, and how to set up a machine-learned CNN aggregator with a classification loss. Propose an overall solution that reduces storage while boosting online metrics.
Detailed Solution
Baseline: Unweighted Average
Some users perform a certain action type (for example, APPLY) multiple times. The simplest baseline is to average all job embeddings for that action. Suppose a single user has n jobs associated with an APPLY action, each job having embedding e1, e2, …, en. The unweighted average embedding for that action is:
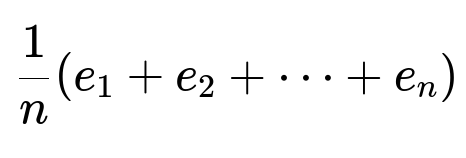
All embeddings are in the same dimension. This approach is easy but treats all jobs equally, regardless of how recently they were interacted with.
Geometrically-Decaying Average
A more refined approach introduces a decay factor r, giving more weight to recent actions. Sort the job embeddings e1, e2, …, en by ascending timestamp so that e1 is the oldest and en is the newest. The weighted average embedding is:
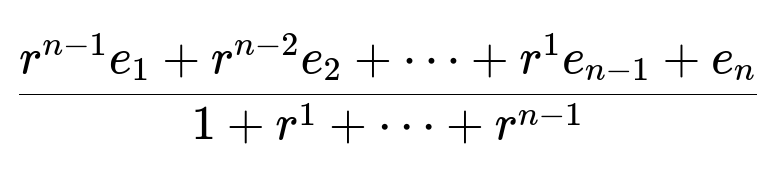
A grid search over r in (0,1) can find a value that gives the best performance. Each action type (APPLY, SAVE, DISMISS) can have its own embedding. This is a small jump in complexity but can improve results significantly because recent interactions matter more.
Machine-Learned Activity Embedding with CNN
A single embedding can be learned from the entire sequence of actions. Concatenate each job’s embedding with a one-hot vector of the action type (APPLY, SAVE, DISMISS). For a user’s activity sequence of length n, feed the first n-1 entries into a 1D convolutional neural network to produce a hidden-layer output. Use that output as the learned activity embedding. Then combine it (by a Hadamard product) with the nth job’s embedding to predict whether the nth action is positive or negative. Train by minimizing cross-entropy loss on this classification.
If the data is skewed (many positive actions, few negatives), random negative sampling can balance the ratio, labeling the synthetic negative examples with a weaker negative label. A sliding window approach can generate multiple training samples from users who have many more than 32 actions, instead of truncating them.
This model can capture nuanced patterns in sequences and reduce storage overhead to one embedding per user, rather than storing multiple embeddings per action type.
Pipeline and Serving
A daily or frequent batch job can:
Retrieve all users’ most recent activities (up to 32 or another limit).
Feed them into the CNN-based aggregator or the decaying average logic.
Export the user embeddings to a centralized feature store.
Downstream recommendation systems retrieve these embeddings to personalize job rankings. This pipeline can be iterated with new model architectures (like Transformers) without large engineering overhead.
Below is a simplified Python-like snippet for the CNN-based aggregator training (omitting parts for brevity):
import tensorflow as tf
class CNNActivityEmbedding(tf.keras.Model):
def __init__(self, embed_dim, num_filters, kernel_size):
super().__init__()
self.conv1d = tf.keras.layers.Conv1D(filters=num_filters,
kernel_size=kernel_size,
padding='same',
activation='relu')
self.global_pool = tf.keras.layers.GlobalMaxPooling1D()
self.final_dense = tf.keras.layers.Dense(embed_dim)
def call(self, input_seq):
# input_seq shape: (batch_size, seq_len, embed_dim + action_type_dim)
x = self.conv1d(input_seq) # (batch_size, seq_len, num_filters)
x = self.global_pool(x) # (batch_size, num_filters)
x = self.final_dense(x) # (batch_size, embed_dim)
return x
# usage
model = CNNActivityEmbedding(embed_dim=200, num_filters=64, kernel_size=3)
# training loop to predict next action's positivity or negativity
Possible Follow-Up Questions
How do you handle users with very few or zero activities?
Use the historical profile-based features in place of activity embeddings. For users with less than a minimum number of interactions, skip the CNN aggregator. A fallback embedding can be zeros or some default derived from typical user behavior. During training, filter out extremely sparse sequences or apply a small weighting for them.
Why is random negative sampling beneficial and how is it done?
Extremely imbalanced data reduces a model’s ability to learn meaningful patterns. Random negative sampling inserts artificial negative examples by pairing a user with a random job they did not interact with. Label it as a weaker negative class if the user never truly saw that job. This helps the classifier see more negative patterns. The sampling can be done by day or time bucket to keep the negative example somewhat realistic.
How do you pick the best decay factor for the weighted average?
Sort candidate values of r (for example, 0.6, 0.7, 0.8, 0.9). Compute embeddings using each decay value, then measure offline metrics (such as AUC or precision) in a validation set. Choose the r that maximizes the metric. Perform an A/B test online to confirm gains.
Why might a convolutional approach learn better than a simple decay formula?
A CNN can capture local patterns in a sequence, like a user who alternates between dismissing certain jobs and applying to others. A learned filter can assign different importance to each step. A fixed decay factor always imposes the same geometric weighting. The CNN’s flexibility can capture more intricate behaviors.
How often should the model refresh embeddings?
Daily or more often if user activity is frequent. If near-real-time updates are supported, they can reduce latency between a user’s new action and the new embedding generation. This might enhance relevance for time-sensitive job seekers.
How do you deal with storage constraints when computing so many embeddings?
Move from three separate embeddings (APPLY, SAVE, DISMISS) to one combined aggregator. Use lower-dimensional representations if needed. Prune older user histories or keep only the most recent 32 jobs. Compress final embeddings with techniques like quantization if space is critical.
What if some action types are strongly correlated or less frequent?
Include one-hot action type indicators in the CNN aggregator. A robust model will learn to down-weight less frequent actions if they carry limited predictive power. If an action type rarely occurs, the model’s filters often ignore it, or you can upsample those sequences if you believe they are critical.
How would you tackle large-scale serving?
Use a distributed data pipeline that processes user-event logs daily. Transform them into fixed-length sequences, run them through the aggregator in a batch job, store results in a feature store, and broadcast them to the serving layer. Employ Spark or Flink for scalable processing. Use a GPU-based system if training the CNN for millions of sequences.
How do you validate improvements beyond A/B tests?
Check offline metrics (precision, recall, ranking metrics). Then confirm an online A/B test with real user engagement. For a job recommendation system, track metrics like click-through rate, application starts, or hires. Also inspect user cohorts, for instance new grads vs. mid-career professionals, to ensure general improvements.