
ML Case-study Interview Question: LLM Generation and Judging of ASTs for Natural Language Marketing Segmentation


Case-Study question
A global B2B company supports marketing teams who need to create advanced customer segments without manually navigating complex user interfaces. Their Data Science group leverages Large Language Models (LLMs) to interpret natural language prompts and automatically compile them into an internal Abstract Syntax Tree (AST) representation of audiences. They also apply an LLM-based “Judge” to evaluate generated ASTs against a reference “ground truth.” The objective is to ensure the AST generation is accurate and robust before deploying it to production pipelines. Design a comprehensive strategy to develop and deploy this system. Propose data collection, model selection, prompt engineering, multi-stage architecture, evaluation procedures, and any supporting tools or frameworks. Address how to handle edge cases and measure quality.
Provide your solution.
Below is a case-study with enough detail to consider the entire flow, including how to evaluate each component and ensure reliable performance.
Detailed Solution
Overview of the Core Approach
Their LLM-based pipeline includes two main tasks. First, a Prompt-to-AST step uses an LLM to parse user prompts into an AST describing audience logic. Second, an LLM-as-Judge step verifies and scores the generated AST against a reference AST, aiming to measure correctness. Developers measure alignment with human judgments and then iterate on prompts, model architectures, or retrieval components.
Data Collection and Reference Ground Truth
They gather ASTs created by real marketing teams as references. These ASTs form the labeled dataset. To generate training prompts, they build a Question Generator Agent that takes an AST and synthesizes a plausible user query. This yields pairs of (prompt, reference AST). In practice, they collect thousands of these pairs.
Model Selection and Prompt Engineering
They test multiple LLMs like GPT-4 and Claude to generate ASTs. They adopt system messages that outline consistent syntactic output. They refine prompts by specifying AST syntax details and the exact JSON-like structure. If the system yields parse errors or incomplete fields, they update prompts and add clarifying instructions.
Multi-Stage Architecture
They choose a multi-step method:
Question Generation: Derive user-like prompts from known AST references.
AST Generation: Produce ASTs from these prompts using the main LLM.
LLM-as-Judge: Compare generated ASTs with reference ASTs. If they match logically, the system returns a high score. If not, the system scores them lower and offers reasoning.
Evaluation and Scoring
They assess alignment between generated ASTs and the reference AST. They assign discrete scores to simplify LLM outputs (for example, 1 to 5). They discovered continuous scores can be unstable. They also incorporate a Chain of Thought (CoT) so the judge can produce detailed reasoning. This improves alignment with human judgments from about 89% to over 90%.
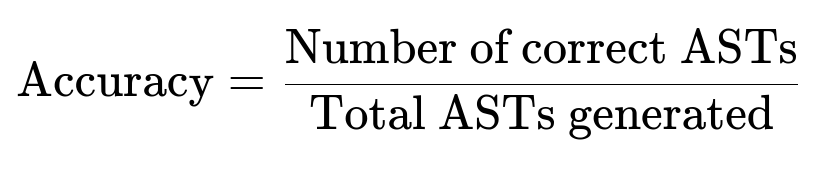
They track the fraction of generated ASTs that match or logically equate to the reference. They measure improvement using a test set of references. They also compute model performance on these test sets after each prompt update or model upgrade.
Parameters inside this expression:
Number of correct ASTs: total count of generated ASTs that pass the equivalence check by the judge.
Total ASTs generated: entire count of attempts from the generative model.
They also measure user-centric metrics like average time to first valid AST or fraction of first-attempt success. This reveals how well the system performs in real sessions.
Handling Edge Cases
They maintain a fallback path if the model fails repeatedly. For ambiguous or partially formed user prompts, they prompt the user for clarifications. They rely on reference rules to catch anomalous ASTs that the LLM might output.
Practical Implementation Details
They unify code in Python. They create separate modules for:
PromptBuilder: merges user instructions into the correct system and user messages for the AST generator.
JudgeModule: houses the judge LLM call and scoring logic.
ASTComparator: normalizes or canonicalizes ASTs to handle semantically equivalent forms.
Example pseudocode to illustrate the Judge process:
import json
import openai # or your chosen LLM library
def judge_ast(generated_ast_str, ground_truth_ast_str):
# Prepare a system message prompting the model to compare two ASTs
system_prompt = (
"You are a code-judge. Compare two JSON-based AST strings for logical equivalence. "
"Output a score from 1 to 5 and reasoning. 5 means perfect match."
)
user_prompt = (
f"GROUND_TRUTH:\n{ground_truth_ast_str}\n\n"
f"GENERATED:\n{generated_ast_str}"
)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
# The model returns a textual response. Parse out the final score.
return response["choices"][0]["message"]["content"]
They store the result and track the distribution of scores. They compare these scores to human-labeled evaluations to see if the judge is consistent.
Follow-up Questions
1) How do we handle equivalences in AST structures that look different yet represent the same logic?
Canonicalization. They parse ASTs and reorder or unify their internal nodes if they are logically the same. They define a normalization function that sorts or transforms sub-expressions to a canonical form. This reduces false differences.
2) How do we confirm that an LLM-based Judge is trustworthy?
They keep a test set with human-labeled pairs. They measure accuracy of the judge’s scoring. They also observe consistency across multiple random samples. If the judge diverges from human evaluations, they refine prompts or adopt a better model.
3) What if the LLM frequently fails to generate a fully valid AST?
They adopt a multi-pass approach. They instruct the model to output only well-formed JSON. If it fails, they either retry with a clarifying prompt or fallback to a stricter, rule-based AST generator. They log repeated failures for offline analysis.
4) How do we integrate external knowledge about events or attributes not seen during training?
They employ Retrieval Augmented Generation (RAG) with a vector database storing frequently updated attributes and events. They retrieve relevant data about user behaviors or events, then add that text context to the LLM prompt. This ensures the LLM sees the latest definitions and can produce the correct AST fields.
5) How do we decide if multi-stage processes are necessary versus a simpler single-stage approach?
They run A/B tests on real internal data. They measure success rates, user satisfaction, and AST correctness. If single-stage performance meets quality thresholds, they might skip multi-stage overhead. If single-stage approaches yield more errors, multi-stage steps remain the safer choice.
6) How do we tackle complex audience definitions that involve nested logic or aggregated metrics?
They incorporate specialized prompt templates or a function-calling approach. They instruct the LLM to handle nested syntax by specifying each node’s type. They might partition the AST building process into small subproblems. They confirm correctness via the judge module. They ensure consistent references to advanced metrics (like aggregator counts) by adding definitions in the prompt context.
7) How do we ensure reliability at scale for many concurrent LLM calls?
They spin up a service layer with concurrency controls and caching. They enforce rate limits. They batch calls if needed. They also measure GPU or token usage. They monitor latency to avoid timeouts. They implement partial circuit breakers so partial generation tasks do not disrupt the entire service.