
ML Case-study Interview Question: CNN-LSTM for Automated E-commerce Product Taxonomy Classification


Browse all the ML Case-Studies here.
Case-Study question
You are given a rapidly expanding e-commerce platform that adds thousands of products daily. These products often land in default or incomplete categories and do not appear in relevant search results. The task is to design a deep learning solution to classify products into the correct product taxonomy hierarchy, so they can be more discoverable and better shelved. You have multiple product departments. Each department has its own hierarchy with multiple levels, such as Product Category (PC), Product Family (PF), and Product Type (PT). You must create a model that predicts PT for incoming products and derive PF and PC from existing mappings. Propose how you will build this pipeline from raw product attributes to final shelving. Outline data selection, preprocessing, model architecture, training, evaluation, and how you plan to integrate the model outputs into your final shelving rules.
Constraints:
You must handle varied product descriptions and names containing special characters or emojis. You have access to brand information and textual attributes. You will eventually need to do a manual validation step for high-confidence predictions. Prepare to discuss potential scalability challenges, performance metrics, and follow-up improvements.
Detailed Solution
Task Definition
The goal is to classify incoming products into a multi-level hierarchy. The primary classification target is the Product Type label for each department. Once a Product Type is identified, the Product Family and Product Category are derived from a predefined mapping.
Data Preprocessing
Products with partial or default labels are selected for training. Each product has textual attributes like product name and description. Remove special characters, emojis, and extra spaces. Tokenize the cleaned text using a tokenizer utility from Keras or similar libraries to create input embeddings. Organize department-wise data for separate training sets to handle unique Product Types in each department.
Model Architecture
A CNN-LSTM multi-class classification model can capture both local semantic patterns (via convolution layers) and longer contextual dependencies (via LSTM layers). Each department’s model is trained to predict the Product Type from text embeddings.
Training Procedure
Split the training data into 70% for training and 30% for validation. Each label has multiple examples to allow sufficient learning. Use early stopping to prevent overfitting and checkpointing to save the best weights. Evaluate model performance on the validation set.
Multi-Class Cross-Entropy
Use multi-class cross-entropy as the loss function:
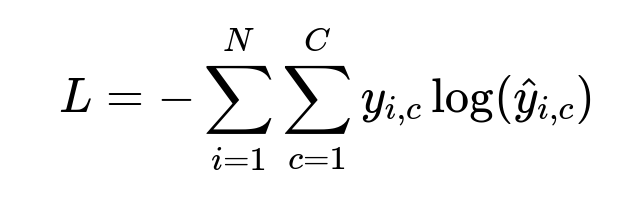
N is the number of training examples. C is the total number of Product Types. y_{i,c} is 1 if the i-th example belongs to Product Type c, otherwise 0. hat{y}_{i,c} is the predicted probability that example i belongs to class c.
Model Inference and Thresholds
Use the saved model to generate Product Type probabilities. Choose a cutoff threshold to filter out low-confidence predictions. Assign Product Type to products above that threshold. The new Product Type is mapped to the correct Product Family and Product Category.
Shelving with New Labels
Push the updated labels into the catalog. A separate shelving process runs rules that place products in relevant site locations. Validate a subset manually. If the newly predicted labels are correct, those items appear in search results for the appropriate shelves.
Example Walkthrough
A product description like: “Beginner Classical Ukulele Guitar Educational Musical Instrument Toy for Kids.” The model predicts “Toy Musical Instruments,” which maps to “Kids Musical Instruments” for final shelving. This ensures better discoverability.
Implementation Notes
Code can be structured with Python and libraries such as Keras or PyTorch. Train department-specific CNN-LSTM models. Store preprocessed embeddings in memory or on disk. Use model checkpoints for reliability. Keep a manual review process to confirm predictions on a fraction of items.
Resulting Impact
Accurate taxonomy labels place products on correct shelves, driving higher search relevance. Future scaling involves merging department-specific models or building a unified multi-department classifier.
How to Answer Tough Follow-Up Questions
What if certain products fit multiple departments?
A single classification approach may incorrectly confine items to one department. A flexible multi-department labeling strategy can be built by expanding the final layer to predict possible department-probabilities first, then selecting the top department. Another approach is a unified multi-label classification system that predicts all viable classes. In practice, start with a simpler approach of department-based models. Later, gather mislabeled examples and retrain with multi-department coverage.
How do you manage rare or unseen Product Types?
When the training distribution is skewed, data augmentation and sampling techniques help. Separate long-tail Product Types and apply targeted oversampling or synthetic examples. Another approach is to combine rarely used Product Types into an “other” bucket, then refine them once sufficient data arrives.
How do you ensure that product text with misspellings or incomplete descriptions is correctly handled?
Expand text preprocessing. Use methods like subword tokenization or character-level embeddings to handle misspellings. Enrich partial descriptions with brand or category keywords from external references if available. Continually retrain or fine-tune the embedding layer using real-time data.
Why choose CNN-LSTM over simpler architectures?
CNN captures local features like n-grams. LSTM tracks broader context across the sequence. This combination frequently outperforms simpler models. CNN-LSTM can learn complex language patterns and generalize better than basic feed-forward networks.
How would you deploy this model to production?
Containerize the model with Docker. Load tokenization and model weights at startup. Expose a REST endpoint for classification. Monitor input data distributions and track confidence scores. Retrain periodically if the data distribution shifts or new Product Types appear.
How do you handle extremely large catalogs and new data in real time?
Maintain streaming pipelines with tools like Kafka to feed new product data. Use incremental or partial retraining. Employ microservices that receive product attributes, preprocess them, and pass them to the model asynchronously. Cache frequent lookups. Scale horizontally with GPU clusters.
How do you validate performance beyond accuracy?
Use precision and recall per Product Type. For search relevance, test if predicted categories improve user engagement metrics like click-through rates or conversions. Conduct A/B tests on real traffic to measure improvements in discoverability. Track label drift over time, especially for trending products.
How do you update the shelf assignment if the model misclassifies?
Establish a feedback loop. If a product is found in the wrong category, correct the label in your master data store. Schedule frequent re-shelving runs. Incorporate such corrections into model retraining. This active learning cycle keeps the taxonomy fresh and accurate.