
ML Case-study Interview Question: Building a Generative AI Help Desk Chatbot with Retrieval-Augmented Generation


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a prototype system that uses generative AI to enhance a help desk chatbot. You have a large repository of publicly available support documentation, hosted on a third-party platform. The goal is to let users type any question in plain text and receive relevant, concise, and personalized answers immediately. The system must:
Index all existing documentation and handle updates automatically when new articles are added or existing ones are modified.
Retrieve and return the most relevant document chunks along with a synthesized answer from a Large Language Model (LLM).
Offer flexible integration with various AI model providers and vector store solutions to compare response speed, cost, security, and reliability.
How would you design and implement this system? Propose a step-by-step plan, describe how each component interacts, discuss how you would handle data updates, and ensure quality assurance for correctness and safety of AI-generated answers. Suggest how to handle unexpected user questions or abusive queries. Include any relevant insights on cost and speed tradeoffs.
Detailed solution
Gathering and storing support articles
Scrape public articles from the existing support documentation platform. Extract the title, body, and metadata (for example, tags or timestamps) to a standardized JSON structure. Keep these files in local storage or a cloud bucket. Store them in a database to enable easy updates when documentation changes. Run a webhook from the support platform to detect new or removed articles.
Splitting content into chunks
Break each article’s text into chunks based on HTML delimiters or paragraph boundaries. Use smaller chunks to let the retrieval step return only relevant portions. This helps the LLM focus on targeted information instead of entire documents.
Creating embeddings and building a vector store
Convert each chunk into an embedding vector representation using an embedding model. Index these vectors into a vector store. Any user query is transformed into its embedding, then compared against these stored vectors to find the closest matches. A common measure is cosine similarity:
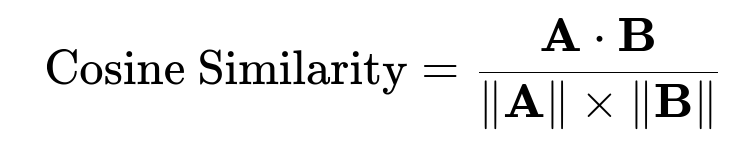
Where A and B are embedding vectors. A · B is the dot product of the vectors, and ||A|| and ||B|| are their magnitudes. High similarity values mean the query is closer in meaning to the chunk.
Synthesis with a Large Language Model
Send the user’s question and the top matching chunks to an LLM. Instruct the LLM to generate concise answers based on those chunks. Provide detailed instructions to refuse or flag any queries unrelated to the support content.
Quality assurance and filtering
Set temperature=0 for deterministic responses with minimal creativity. Instruct the model to return only valid, relevant answers. Include a safety or moderation API to flag questions about dangerous or abusive topics. If a question is not about the company’s support content, instruct the system to politely refuse to answer.
Switching model and vector store providers
Wrap the system logic so that swapping out AI model providers or vector store libraries is simple. This makes it easy to run performance, cost, or reliability tests. For example, you can test a local solution like HNSWLib or a managed vector store, and compare LLMs from different vendors.
Handling data updates
Use the support platform’s webhook to trigger re-scraping or re-ingesting articles when changes occur. Replace outdated embeddings in the vector store with updated ones. If articles are removed, remove their vector entries. Keep a version tag or last-modified timestamp in metadata to stay in sync.
Handling user queries
Keep a short chat history to let users ask followups. Generate a standalone question from the current and previous questions to reduce confusion. Embedding that standalone query ensures relevant chunks are fetched from the store, even if the user uses shorthand.
Implementation details (sample)
Use a framework like Langchain to manage prompts, chain steps, and connect to different AI endpoints. In a Node.js or Python backend, store the chat history in a database. Retrieve it when the user sends a message, then generate the final answer with LLM calls. Present the source URLs so the user can confirm the correctness.
Q1
How do you maintain a conversation’s context when a user’s next question is incomplete?
A followup query may be short or reference the previous question. Store the entire conversation in a database. On each new message, load the last few lines of context, ask the LLM to rewrite the user’s message into a standalone question, embed that standalone question, and retrieve relevant document chunks.
Q2
How would you ensure the system doesn’t produce fictitious or outdated URLs in its answers?
Collect metadata about each chunk when building the vector store, such as the real URL. Instruct the LLM to display that stored URL instead of generating its own. If the LLM tries to invent a link, override it with the metadata link. If the document is missing or outdated, no link is provided.
Q3
What steps would you take to secure the system when you switch AI providers?
If using Google Cloud, configure Workload Identity so containers are automatically authenticated. If using OpenAI or Azure OpenAI, securely store the API key in a key manager. Avoid exposing credentials in code or logs. If the vector store is local, guard file system access with proper user permissions.
Q4
How do you decide which model to use, given cost, speed, and accuracy concerns?
Measure each model’s average latency, cost per thousand tokens (or characters), and performance on a representative set of queries. Compare streaming response benefits to batch response speeds. If your workload is large, cost might dominate. If the queries are mission-critical, you might prioritize reliability and accuracy, even at higher cost.
Q5
Why is chunking important for retrieving relevant answers?
A large article can contain many unrelated sections. Chunking allows direct matching of question embeddings with specific sections. This improves the quality of the retrieved text. If you return the entire article, the LLM might wander or waste tokens summarizing irrelevant parts.
Q6
How would you test the system’s output for correctness?
Set temperature=0 for consistent results and create a suite of typical support questions. Check if the answers match the article’s official guidance. Record system logs to track the top retrieved chunks and final LLM responses. Update and refine prompt instructions or chunking strategy if answers appear incorrect.
Q7
How do you handle malicious queries or attempts to prompt the system into disclosing sensitive data?
Use a content moderation API to filter out keywords or categories that violate policy. Instruct the LLM to refuse revealing private information. If the user continues asking for disallowed content, the system halts. Keep strong logs and monitor for repeated suspicious queries.
Q8
What if the system starts returning incomplete or confusing answers after major documentation changes?
Look for indexing errors or old embeddings that did not update correctly. Confirm the latest article text is present. Try a manual re-index. Check for any major changes in the chunking logic. Examine your prompt instructions to ensure the new content is recognized. If problems persist, retrain or re-ingest everything from scratch.