
ML Case-study Interview Question: Bayesian Time Series Anomaly Detection & FP-Growth for Automated Fraud Rules


Browse all the ML Case-Studies here.
Case-Study question
A large technology marketplace processes massive volumes of real-time monetary transactions each day. The business assumes all payment risks, so if a user exploits the system, the company absorbs the financial loss. Sometimes the platform sees sudden spikes in uncollected orders or disputed charges, which can mean fraudulent attacks. The risk analysts must investigate these suspicious transactions. They want an automated system that monitors real-time signals and flags fraud attacks early. They also want the system to propose a new blocking rule for each suspected fraud pattern. Human analysts review the proposed rule before final deployment. Design a system that accomplishes these goals. Include details about (1) how you detect abnormal fraud spikes early, (2) which data pipelines and time-series models you would use for anomaly detection, (3) how you transform these anomalies into automated rule generation, (4) which methods handle high-cardinality categorical data in the feature selection and associative pattern mining, (5) how you ensure that the system scales effectively without underutilizing cluster resources, and (6) how human feedback can be incorporated to avoid false positives.
Detailed Solution
A system for early fraud detection benefits from a two-part process: anomaly detection in time-series data and automated pattern-mining that produces blocking rules for suspicious transactions. The system uses a big data engine for large-scale processing and scheduling. Below is a step-by-step breakdown.
Time-Series Data Pipeline
Payment activity data streams into a Kafka-based pipeline. A streaming aggregation layer ingests risk-enriched information, storing it in a data warehouse such as Hive. A custom job running on a distributed engine (for example, Apache Spark) applies rolling-window functions to build hourly time-series segments. Each segment focuses on signals like uncollected orders or disputed charges. The pipeline retains two notions of time:
The order time indicates when the transaction was completed.
The settlement maturity time indicates the actual resolution of payment.
Analysts see immature signals that may not finalize for days or weeks, so the pipeline must forecast these partial losses and project them to a future date. This pipeline continuously generates updated hourly time series for each region, payment type, and other risk-related slices.
Anomaly Detection with a Bayesian Time-Series Model
The system employs a Bayesian time-series decomposition model. This model captures dynamic trends and seasonality in each univariate time series. The decomposition often takes a form:
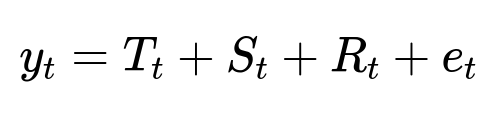
Where y_{t} is the observed hourly losses, T_{t} is the trend, S_{t} is the seasonality, R_{t} is the regression component for external factors, and e_{t} is the error term. The system forecasts future y_{t} values based on historical patterns. A spike is flagged if the observed metric significantly exceeds the model’s prediction interval. Each flagged spike is considered an anomalous fraud attack.
Severity Estimation and Ranking
A short-term anomaly does not necessarily imply a severe financial impact. The system uses projected full-maturity losses and compares them against a forecasted baseline. If the projected losses exceed a smart threshold, the anomaly is considered high priority. The system ranks these anomalies and raises tickets in an internal queue. Analysts handle the most urgent anomalies first. Each anomaly is logged, whether or not it is escalated to the team.
Feature Selection for Associative Pattern Mining
The next step automatically searches for suspicious transaction patterns that define potential blocking rules. The system aggregates all suspicious events over a short time horizon. The data has many categorical features with high cardinality (for example, user location, card bin, software version). Each feature-value pair is one-hot encoded. A custom minimal redundancy maximal relevance (MRMR) approach filters features:
Relevance checks whether a feature correlates strongly with the fraudulent outcome.
Redundancy checks whether multiple features overlap in information content. This step is computationally heavy. The system runs it on a single, vertically scaled machine or driver node instead of a large cluster. The specialized vertical scaling better handles the calculations for high-cardinality data.
Frequent-Pattern Mining for Rule Generation
The filtered features produce itemsets of key-value pairs. A frequent-pattern growth (FP-Growth) algorithm identifies common item subsets among fraudulent transactions. The result is a list of high-support item combinations that appear in suspicious events. The system then refines these patterns into candidate blocking rules by applying confidence thresholds and other quality checks.
A Spark-based FP-Growth job can run in parallel across many worker nodes. Once it outputs these candidate patterns, each pattern is tested against historical data to measure its true-positive rate. Only patterns that meet precision thresholds advance.
Here is a simple Python code snippet showing how Spark’s FP-Growth might be applied to a small DataFrame:
from pyspark.ml.fpm import FPGrowth
df = spark.createDataFrame([
(["id34","id60","id56","id90"], ),
(["id34","id60","id57","id90"], )
], ["items"])
fpGrowth = FPGrowth(itemsCol="items", minSupport=0.5, minConfidence=0.6)
model = fpGrowth.fit(df)
model.freqItemsets.show()
model.associationRules.show()
model.transform(df).show()
Rule Validation and Human Review
Each proposed blocking rule is tested on a sample dataset (using vertical scaling on the driver), then validated on the full dataset (using traditional distributed queries). Potential false positives are measured. Analysts then receive these candidates in a ticketing system. They examine the context and decide whether to approve or reject each rule. Once approved, rules go into a rule engine that applies them in real time.
Scaling Considerations
Different steps of the pipeline need different scaling approaches. Time-series computations with rolling windows benefit from horizontal scaling on a large cluster. Feature selection with high-cardinality data often performs better on a vertically scaled driver. The frequent-pattern mining job then returns to a horizontally scaled Spark environment. This cycle can produce idle resources at certain stages. The solution is to run multiple fraud-attack jobs in parallel, each with independent data segments, so the cluster remains fully utilized.
Human-in-the-Loop Feedback
Analyst validation is essential. Automated signals risk large-scale impacts if they are incorrect. A small mistake could wrongly block many legitimate users. Feedback from analysts after investigating anomalies or blocking rules retrains models and refines thresholds. This iterative loop ensures the system focuses on the most relevant signals and stays aligned with the latest fraud tactics.
How would you handle a sudden data pipeline delay when streaming new transactions?
Time series modeling relies on timely data updates. If streaming becomes delayed, the anomaly detection steps miss real-time signals. Re-architecting the pipeline with additional buffering or queueing can avoid losing data. The system can also backfill older data once the pipeline recovers, re-running the anomaly detection for the hours that were missed. Analysts should be alerted about pipeline stalls.
Why is a fully supervised classification model insufficient for early fraud detection?
Supervised models rely on labeled training data. New fraud attacks may have no prior label or differ from known past patterns. Anomaly detection does not assume known classes in order to flag novel spikes. A supervised approach is better at common or repeated fraud patterns. Early detection of new patterns needs an unsupervised or semi-supervised approach combined with human expertise.
How does the two-dimensional time concept help reduce noise?
The order-time dimension focuses on when the transaction happened. The settlement-maturity-time dimension focuses on the financial resolution. This distinction isolates partial payments or delayed chargebacks, preventing analysts from misreading normal settlement delays as fraud. The final anomalies factor in how a transaction’s actual payment eventually settled.
How are false positives mitigated when rules are generated automatically?
After the FP-Growth step finds frequent patterns in suspicious data, the system simulates each candidate rule on historical transactions to estimate precision and recall. A final threshold ensures only high-precision rules are forwarded to analysts. Analysts can still override or adjust rules before deployment. This multi-check approach prevents overblocking legitimate transactions.
Why does feature selection require a specialized approach?
Imbalanced data in fraud detection causes many rare feature-value occurrences. Classic feature selection frameworks struggle with very high-cardinality features. A custom approach eliminates redundant features and focuses on features that strongly differentiate fraudulent transactions from legitimate ones. This specialized method keeps the final input set small enough for pattern mining.
Why might you combine a vertical scaling approach with a horizontally scaled cluster?
Vertical scaling on the driver handles algorithms that do not partition cleanly, such as large mutual information matrices for feature selection. Horizontal scaling handles embarrassingly parallel tasks such as time-series window aggregations or large-scale frequent pattern mining. Alternating between these modes can lead to idle cluster resources, so parallelizing multiple streams of fraud detection jobs prevents wasteful underutilization.
How is human feedback incorporated to improve the system?
Analysts see system-generated anomalies and rule recommendations. They examine the underlying data context. They accept or reject rules, sometimes with adjustments. The system captures these decisions and uses them to refine thresholds, anomaly definitions, or feature selection parameters. This cyclical process addresses shifting fraud tactics and improves the overall precision of the automated pipeline.