
ML Case-study Interview Question: Scalable Multi-Label Video Classification Using Deep Visual Frame Aggregation


Browse all the ML Case-Studies here.
Case-Study question
You are given a large video-hosting platform that wants to expand its contextual advertising capabilities. They have millions of videos uploaded by thousands of content creators. Each video has minimal textual metadata (short title, brief description, or sometimes none at all). They also have a subset of videos with partial text labels in English and French, but they want to handle many other languages and obtain granular categories based on a known taxonomy with nearly 200 possible categories.
They want a multi-label classifier that uses visual content from the video frames. Your goal is to propose a design for a supervised learning system that classifies each video by these categories using video frames, possibly combined with metadata or textual signals. Your solution must scale for real-time classification of new uploads and also backfill classification for millions of existing videos.
Discuss the technology stack, the machine learning approach, and system architecture needed to solve this. State assumptions, data needs, potential trade-offs, and how to measure success. Provide a detailed plan for combining model outputs from text-based classifiers and a model that uses visual frames. Propose implementation details and how you would optimize performance over time.
Detailed solution
The platform faces a multi-label classification problem. Each video may belong to several categories. The plan relies on deep learning techniques and a carefully labeled dataset. The approach must handle minimal textual information and focus on video frames. It also needs a scalable pipeline.
First, define a subset of categories that depend on visual cues. Some categories are not visually identifiable (for instance, some musical genres or purely textual topics), so these may be excluded from the purely visual model. The textual classifier can remain active for categories that are not strongly visual.
Dataset and labeling
Data comes from: textual signals (title, description), visual signals (video frames), optional metadata (creator, upload category, language).
For training labels, the textual classifier predictions serve as ground truth to train the visual model. Textual predictions are not perfect, but they offer a large volume of labeled data. Train on a subset where textual model confidence is high. This ensures the visual model learns reliable categories.
Model architecture
An effective solution for video classification is to transform each frame into image descriptors and aggregate these over time. A known base image model (for instance, an Inception-type network) extracts frame-level features. Then a temporal aggregation layer combines these frame descriptors into a single video-level vector. One advanced approach is derived from the NeXtVLAD method.
The architecture has:
Pretrained image encoder applied to sampled frames from each video.
Aggregation layer (NeXtVLAD or similar) that compresses frame-level features into one fixed-size vector.
Metadata encoder appended to the aggregated vector.
Fully connected layers to produce final multi-label outputs.
Below is the core training objective for each label. Let y_i be the true label in {0,1}, and y_hat_i be the predicted probability for label i:
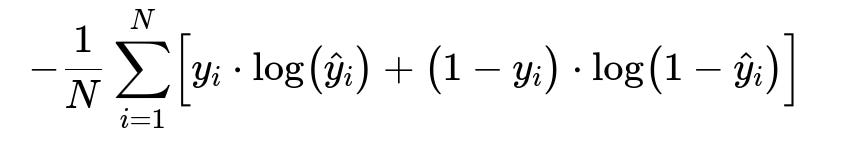
N is the number of training samples. y_i is 1 if the sample belongs to label i, 0 otherwise. y_hat_i is the predicted probability for label i.
This cross-entropy loss penalizes errors in predicting probabilities for each label. It is suitable for multi-label tasks, where each label is predicted independently.
Implementation pipeline
A robust data pipeline is needed to handle high throughput. Steps:
Download or read new uploaded video.
Extract frames at specific intervals (for example, 1 frame per second).
Pass each frame through the pretrained image encoder to generate embeddings.
Aggregate frame embeddings with the temporal module (NeXtVLAD).
Append metadata features and run the final network layers for multi-label classification.
Store predictions in the database.
To backfill the entire catalog, run the same pipeline but schedule it via a distributed processing system. Every step is parallelized to handle millions of videos. Some frameworks (such as a streaming data processing framework) can facilitate high-scale video ingestion and frame transformation.
Merging predictions
A textual classifier is already in place. Merging both classifiers can improve coverage. A union of their category predictions increases the number of assigned labels, but it may also introduce more false positives. A well-calibrated threshold is used for each classifier’s confidence. Simple union is easy to implement but can be naive. A more advanced approach merges predictions based on model confidence or uses a small meta-classifier that learns to combine textual and visual signals.
Performance measurement
Coverage is the fraction of videos given at least one relevant category. Number of categories per video is how many valid labels are identified. The f1 score or precision-coverage curves at various thresholds measure how well the classifier assigns relevant categories while keeping a low false positive rate. A practical business threshold is usually set around 80% precision.
Example code snippet (Python)
import tensorflow as tf
# Suppose 'frame_embeds' is a [batch_size, num_frames, embed_dim] tensor.
# Suppose we have a function nextvlad_aggregate(...) that implements the temporal aggregation.
frame_aggregated = nextvlad_aggregate(frame_embeds)
# Suppose we also have some metadata embedding 'meta_embed' of shape [batch_size, meta_dim].
# Concatenate the aggregated video features with metadata features.
combined_features = tf.concat([frame_aggregated, meta_embed], axis=1)
# Define a dense layer for classification
logits = tf.keras.layers.Dense(num_labels, activation=None)(combined_features)
y_hat = tf.nn.sigmoid(logits)
# For training, define the multi-label sigmoid cross-entropy loss
def multi_label_loss(y_true, logits):
return tf.nn.sigmoid_cross_entropy_with_logits(labels=y_true, logits=logits)
This snippet shows the essence of combining aggregated frame features with metadata to produce multi-label predictions.
Scaling considerations
Real-time classification triggers for every new upload. The system must handle concurrency. Parallel frame extraction and feature computation is key. GPU or accelerator clusters can batch multiple videos to maximize throughput. Offline backfill is similar, except done in large pipeline jobs, often with chunked partitioning over the entire video catalog.
Future improvements
Replacing the image encoder with a more modern network can yield better frame features. Adding audio inputs can boost accuracy for categories where sound is informative. A better ensemble approach for textual and visual predictions can refine final outputs. A specialized real-time indexing service can store final results for immediate ad targeting.
Follow-up Question 1
How do you ensure that labeling the visual model with predictions from the text-based model does not cause biased learning, especially if the textual model has systematic errors?
Answer and Explanation A textual model will introduce some noise. Limiting the dataset to high-confidence text predictions reduces error injection. Create a threshold on text classifier outputs or rely on a well-defined segment where textual signals are strong. Perform spot-checking on random samples to monitor discrepancy. If feasible, gather some human-labeled examples to correct systematic errors in textual model labels. Incorporate a small set of manually verified videos in the training set to anchor the visual model with ground truth. This mitigates bias introduced by the text model.
Follow-up Question 2
How do you decide which categories are “visual” enough for the frames to be predictive?
Answer and Explanation Examine each category’s semantic meaning. Categories that rely on visual cues like “Automotive,” “Cooking,” or “Pets” are identified as visual. Evaluate small reference videos for each category and see if humans can identify the topic solely from frames. If it is often impossible to detect the topic from visuals (for example, “Politics” or “Philosophy”), exclude it from the visual model. Adjust based on empirical performance. If the visual model systematically fails certain categories, you either exclude them or rely on a different modality (audio, text).
Follow-up Question 3
Why use a separate model for text-based classification instead of training a single unified approach that ingests video frames and text?
Answer and Explanation A separate text-based model is often simpler to train and deploy where textual data is sufficient. A single large model that handles both text and video frames would be heavier, might require more training data, and might not be necessary if only certain videos are missing text. A stand-alone text model is also easier to maintain. The visual approach complements coverage gaps where the text is too short or in an unsupported language. Combining the outputs post-hoc is simpler, though unifying them could eventually yield higher accuracy. The trade-off is complexity vs. incremental performance gain.
Follow-up Question 4
How do you scale the system for continuous real-time classification of new videos and also handle a massive backfill for millions of existing videos?
Answer and Explanation Separate the pipeline into two modes. In real-time mode, new uploads enter a distributed worker pool. Each worker extracts frames, runs the encoder, aggregates, and applies the classifier. Results are stored in a database for ad serving. For backfill, schedule the same pipeline but partition the existing catalog into manageable chunks. Spin up enough compute instances to process many videos in parallel. Use a streaming or batch-oriented data platform. Aim for minimal overhead in each stage. Maintain metrics to track throughput and errors.
Follow-up Question 5
How would you incorporate audio features if you wanted to enhance classification?
Answer and Explanation Similar to the frame-based approach, a pretrained audio feature extractor can transform audio clips into embeddings. Aggregate them with a similar method (for instance, a parallel NextVLAD or an attention-based approach). Concatenate these aggregated audio features with the final feature vector. Audio can reveal speech content, music type, or other sound cues. Must verify that audio signals do not conflict with user privacy policies. Use segment-level analysis or entire-track embeddings. Fine-tune hyperparameters to balance improvements in precision, recall, and system complexity.
Follow-up Question 6
What specific metrics and thresholds do you set to deploy this system in a production environment where advertisers demand high precision?
Answer and Explanation A typical threshold is 80% precision for each category. Decide this threshold based on trade-offs with coverage. For each label, measure precision and recall across a validation set. Plot precision-coverage curves. Pick the point yielding acceptable coverage while preserving advertiser trust at the chosen precision. Monitor post-deployment performance using real user data. Check if mislabeled videos lead to complaints or degrade click-through rates. Readjust thresholds per category if needed.
Follow-up Question 7
How do you validate that the union of textual and visual predictions is superior to using each model alone?
Answer and Explanation Evaluate on a test set with reliable ground truth or partial human annotations. Compare metrics for three configurations:
Text-only model.
Visual-only model.
Merged predictions. Measure coverage, average number of correct labels per video, and overall f1 score. If merging improves coverage without drastically hurting precision, then it is an improvement. Track key categories to see if merging yields more correct labels or if it increases false positives. Possibly run an online A/B test to measure lifts in click-through rates or other engagement signals.
Follow-up Question 8
If an advertiser complains that certain ads are shown with irrelevant categories, how would you troubleshoot and improve your classifier?
Answer and Explanation Investigate examples where the model assigned that category. Check whether the textual or visual model triggered it. Analyze the confidence scores and which frames or text words influenced the classification. If the text was ambiguous, refine text preprocessing or thresholds. If frames were misleading, see if your chosen sampling interval missed key parts of the video or if the aggregator overfit to certain backgrounds. Possibly exclude misleading categories from the final predictions or add better regularization. Retrain if you find systematic labeling errors or refine negative examples in your training set.