
ML Case-study Interview Question: Hybrid Embeddings for Real-Time Forum Post Ranking Based on User Likes


Browse all the ML Case-Studies here.
Case-Study question
A fast-growing professional networking platform recently acquired an anonymous discussion forum. Each day thousands of new posts appear in various topic-based channels. Users can subscribe to channels and view new posts from them in a home feed. The goal is to personalize which posts appear at the top of each user’s feed. The platform has little explicit feedback data (no known “views” or “clicks” recorded), but there is data on which posts a user liked. Design a recommendation system that ranks incoming posts in real time to maximize user engagement and relevance.
Explain your approach in detail, including how you would handle the lack of explicit negative feedback, how to represent user and post embeddings, and how to serve real-time ranking results at scale. Include any steps to ensure new posts and new users are handled properly.
Detailed Solution
A typical approach without explicit negative feedback is to generate embeddings for users and posts that capture semantic and collaborative signals. We can embed posts based on their text, then derive user embeddings from posts that each user liked, and compute similarity scores to rank new posts. We can also embed users and posts via a graph-based approach. Combining both text-based embeddings and graph-based embeddings leads to a more robust hybrid system.
Text-Based Embeddings
Use a document embedding model to convert each post’s text into a dense vector. Doc2Vec is a common choice. It treats each post as a “document” and learns embeddings in an unsupervised manner by predicting contexts. Posts with similar text end up closer in the embedding space.
After training this model, each post has an embedding p_text. To assign a user embedding, average the embeddings of the posts that user liked:
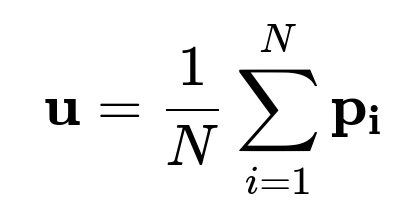
N is the total number of posts liked by the user, and p_i is the text-based embedding of the i-th liked post.
This text-based approach only captures semantic similarity. Users who like posts on certain workplace topics end up near posts that share that textual theme. But it does not leverage the fact that users often like posts from others in the same industry or domain. Hence, we also incorporate user-user or user-post co-occurrence patterns.
Graph-Based Embeddings
Represent the platform as a bipartite graph connecting users and posts. Draw an undirected edge between a user and a post if the user liked that post. Each user and each post is a vertex in the graph. You then learn embeddings for these vertices based on graph traversal.
One approach is similar to DeepWalk, which samples random walks from each vertex. Each random walk is treated like a “sentence.” A Word2Vec-style algorithm then learns embeddings that push vertices co-visited in these walks closer in the vector space. Another approach is to run Doc2Vec on BFS-sampled neighbors. Here, for each vertex, gather neighbor vertices via Breadth First Search and treat them as the “document.” By training Doc2Vec on this corpus of neighbor vertices, you learn embeddings that capture collaborative signals. If certain users often like the same posts, they cluster in the learned space.
Graph embeddings capture user-user similarities (collaborative filtering). The text embeddings capture semantic similarity (content filtering). Combining them often yields higher relevance.
Hybrid Embedding
Concatenate or combine the text-based embedding and the graph-based embedding to form a hybrid embedding for both users and posts. This yields a more complete representation of each user and each post.
For real-time ranking, compute the similarity between a user’s hybrid embedding and each candidate post’s hybrid embedding. In practice, a dot product or cosine similarity is fast to compute. Rank posts by highest similarity.
Handling New Posts and Users
Embedding models that rely on a fixed vocabulary of user IDs or post IDs can struggle with new data. Posts that are not seen during training have no learned ID embedding. Similarly, brand-new users also lack embeddings. One solution:
For new posts, generate text-based embeddings on the fly, since text-based models do not rely on a post ID.
For graph embeddings, incorporate embeddings derived from features like post text or user profile data.
Retrain the graph-based model on a set schedule or use online updates to capture new IDs.
For new users with minimal activity, rely more on text-based signals from the channels they subscribe to, or fallback to global popularity until they generate enough likes.
End-to-End Serving
Serve recommendations in real time by first filtering posts to only those from channels the user subscribed to. Then compute (user embedding) dot (post embedding) for each candidate post. Sort by descending similarity. Return the top K posts. If the serving environment requires sub-10ms latencies, use efficient approximate nearest neighbor libraries or GPU-based vector operations.
Consider logging user interactions carefully to gather better implicit feedback. Over time, incorporate these signals into the model to refine user embeddings and move toward a more supervised approach.
Follow-up question 1:
How would you ensure that your system does not show only textually similar posts to a user, but also captures the fact that users may like certain types of authors or content producers?
Answer: In addition to text-based embeddings, incorporate user-level signals with a graph-based embedding. This captures user-user and user-post relationships that are not entirely reflected in text. Users who frequently like posts from a particular company or industry cluster in the graph space. Merging these graph embeddings with text-based embeddings ensures the final user vector encodes both semantic interests and behavioral patterns. If a user consistently likes content from certain authors, the graph edges reveal those interactions, pulling the user node closer to those authors’ posts in the learned space.
Follow-up question 2:
How do you deal with the lack of negative labels in this system?
Answer: Observe that not liking a post does not necessarily mean the user disliked it. They may have missed it. So there is no reliable negative label. Instead, rely on positive interactions as a signal of similarity. The embedding model self-supervises by pushing liked items closer. The system remains somewhat unsupervised and leverages co-occurrence. Over time, partial negative feedback can be approximated if you track impressions (i.e., if the system knows which posts the user saw but never liked). This can transition the system into a semi-supervised or fully supervised model.
Follow-up question 3:
Why not directly use a simple supervised method predicting a user’s probability of liking a post?
Answer: That approach requires reliable negative labels. Without recorded impressions or clicks, training would treat “not liked” as negative, even if the user never saw the post. This leads to noisy training signals. A purely supervised model might produce biased probabilities. By first learning user and post embeddings in an unsupervised or weakly-supervised manner, the system builds a structured representation that can later be fine-tuned in a partially supervised scenario if more complete feedback data becomes available.
Follow-up question 4:
How would you further enhance performance using advanced language models like BERT or GloVe?
Answer: Transfer learning can yield better text embeddings. For example, load pre-trained BERT or GloVe vectors. Fine-tune them on the platform’s corpus. This captures richer semantic nuances of text that a smaller Doc2Vec model might miss. Then apply the same averaging or pooling strategy for user embeddings. This typically provides better coverage of vocabulary and context. Combine these richer text embeddings with graph-based embeddings for an even more robust hybrid.
Follow-up question 5:
How would you implement this system in code?
Answer: One option is Python with libraries like gensim for Doc2Vec or Word2Vec. For BFS-based embedding:
def build_bfs_documents(graph, max_length=100):
documents = {}
for vertex in graph:
visited = []
queue = [vertex]
while queue and len(visited) < max_length:
current = queue.pop(0)
visited.append(str(current)) # cast to string for doc2vec
neighbors = graph[current]
for neigh in neighbors:
if neigh not in visited:
queue.append(neigh)
documents[vertex] = visited
return documents
Then feed these documents into gensim’s Doc2Vec with each vertex as a unique document label. Save the trained model. For serving, load the model and generate embeddings by calling model.infer_vector for each BFS-based list. For post text embeddings, train a separate text-based model (Doc2Vec or pre-trained BERT-based). Concatenate both embeddings. Use a lightweight REST API or MLFlow for inference. Sort candidate posts by cosine similarity to the user embedding.
Follow-up question 6:
If you see new content each day, how often should you retrain or update the graph-based embeddings?
Answer: Frequent updates help capture recent user behavior, but full retraining can be expensive. A daily or weekly batch retrain might be sufficient for many use cases. For brand-new posts or users, rely on text embeddings or default vectors until the next batch. If real-time freshness is critical, adopt online embedding updates that incrementally adjust model weights for new edges. This is more complex but prevents stale representations.
Follow-up question 7:
How would you prevent bias or echo chambers in this system?
Answer: If users are only shown posts resembling what they previously liked, they may never see new perspectives. To mitigate this, add a small exploration factor that occasionally shows diverse content outside a user’s typical embedding cluster. Another approach is to re-rank top results by adding diversity constraints. For instance, you can randomize a small fraction of the feed or re-score with a penalty if posts are too similar. Monitor engagement metrics to track whether this helps prevent overly narrow recommendations.
Follow-up question 8:
What if the system is slow in production due to heavy embedding lookups?
Answer: Precompute embeddings for users or cache them. Then store post embeddings in a vector store or a key-value store. Retrieval can be done in O(1) for each post embedding plus a quick similarity calculation. If the user embedding is also cached, only a single vector operation is needed per candidate post. For large-scale user and post sets, adopt approximate nearest neighbor search or GPU-based vector calculations. Implement the pipeline with low-latency frameworks, and track performance metrics with each request.