
ML Case-study Interview Question: Neural Network Ranking & Bandits for Personalized Engagement & Cold-Start.


Browse all the ML Case-Studies here.
Case-Study question
You are leading a Data Science team at a large tech company. The platform hosts high volumes of user-generated content, and management wants to boost user engagement through personalized ranking. You have data on user behavior (views, clicks, and detailed engagement signals), content features (metadata, publication date, and textual properties), and contextual features (device type and time of day). The platform already has a baseline recommender, but it struggles with cold-start for new items and fails to adapt quickly to changing user trends. How would you design, build, and deploy an improved ranking solution to address these issues and achieve measurable impact on engagement metrics?
Detailed solution
The problem involves creating a new model that balances personalization, content cold-start mitigation, and dynamic adaptation to user trends. The approach:
Short sentences. No fluff.
Data collection and preprocessing Engineers gather user logs containing clicks, content impressions, watch durations, and contextual info. They merge them with content metadata. They ensure data cleanliness by removing incomplete rows and invalid records.
Feature engineering They create user embedding vectors using aggregated historical behavior such as average watch time or categories viewed. They develop content embedding vectors from textual properties using an embedding model. They include time-of-day or device type as contextual features.
Model selection They try neural networks with an embedding layer for user and item data, and a feed-forward network that incorporates contextual features. They choose a combination of classification and ranking objectives. They measure performance with offline metrics such as mean average precision (MAP) and normalized discounted cumulative gain (nDCG).
Training and loss function They set it up as a binary classification with a cross-entropy loss. They treat each content’s click behavior as a label. Probability of click is predicted. They use negative sampling to handle large data. Below is the core formula for the loss function:
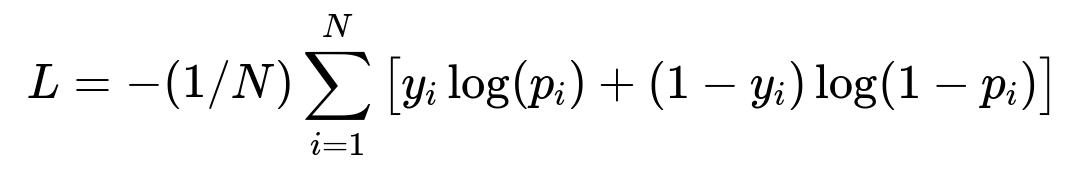
Where y_i is the actual label (0 or 1), p_i is the predicted probability, and N is the total number of samples.
Online architecture They design a pipeline where user and item features are retrieved in real-time. They embed these features, then run them through the trained neural net to get a predicted engagement probability. They serve top-ranked items to users.
Reinforcement learning for adaptation They incorporate a multi-armed bandit strategy on top of the ranking model. They explore new items to handle cold-start by temporarily boosting exploration. They refine the exploration-exploitation trade-off using user feedback signals, re-ranking content as more data arrives.
Model deployment They containerize the model with Docker. They use an orchestration system like Kubernetes to auto-scale in production. They adopt real-time logging for inference metrics.
Monitoring and A/B testing They measure the new system’s effect on user session time, clicks, likes, and watch percentage. They compare variant vs. control in an A/B test. The new model’s success requires a statistically significant lift.
Example code snippet
import torch
import torch.nn as nn
import torch.optim as optim
class RankingModel(nn.Module):
def __init__(self, user_dim, item_dim, context_dim, hidden_dim):
super(RankingModel, self).__init__()
self.user_emb = nn.Embedding(user_dim, hidden_dim)
self.item_emb = nn.Embedding(item_dim, hidden_dim)
self.context_fc = nn.Linear(context_dim, hidden_dim)
self.fc = nn.Sequential(
nn.Linear(hidden_dim * 3, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1),
nn.Sigmoid()
)
def forward(self, user_id, item_id, context):
user_vec = self.user_emb(user_id)
item_vec = self.item_emb(item_id)
context_vec = self.context_fc(context)
x = torch.cat([user_vec, item_vec, context_vec], dim=1)
return self.fc(x)
# Example training loop
def train_ranking_model(model, data_loader, epochs=5, lr=1e-3):
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
for batch_user, batch_item, batch_ctx, batch_label in data_loader:
optimizer.zero_grad()
prediction = model(batch_user, batch_item, batch_ctx)
loss = criterion(prediction.squeeze(), batch_label.float())
loss.backward()
optimizer.step()
The architecture can be more complex with attention layers or Transformers. But the idea is to combine user embedding, item embedding, and context features.
How do you handle very sparse data for new users?
They bootstrap new users by assigning default embeddings derived from user profiles with similar attributes or from global averages. They refine embeddings as new interactions appear.
How do you ensure scalability in real-time inference?
They use feature stores that quickly retrieve user features in memory or key-value databases. They compress embeddings to reduce memory usage. They adopt load balancers to split requests across multiple serving instances.
What if user behavior changes rapidly over time?
They frequently retrain or update the model with streaming data. They set up partial retraining or fine-tuning in near real-time. They incorporate bandit techniques that adjust ranking weights based on the latest user feedback signals.
Why do you combine A/B testing with offline metrics?
Offline metrics guide initial comparisons, but they do not capture real user behavior shifts. A/B tests reveal real-world engagement impact. They confirm improvements by measuring lifts in relevant metrics.
How would you improve cold-start for brand-new content with zero engagement?
They rely on content embeddings from textual or multimedia models to represent new items. They allocate an exploration phase that shows these items to a fraction of users. They refine ranking after collecting initial engagement feedback.
How do you measure success and iterate?
They focus on user-level metrics: clicks, watch duration, and watch completion rates. They watch platform-level metrics: session length and daily active users. They use a feedback loop of offline experiments and A/B tests. They iterate quickly to converge on an effective ranking policy.