
ML Case-study Interview Question: Fine-Tuning Latent Diffusion for Stylized E-commerce Background Inpainting


Browse all the ML Case-Studies here.
Case-Study question
You are given a large text-to-image foundation model trained on billions of filtered text-image pairs. It can generate images from textual prompts. Your team wants to extend it to produce photorealistic backgrounds for e-commerce products. You have product images with masks indicating where the product lies. You also have textual descriptions that describe desired backgrounds. How would you fine-tune this model to fill in missing backgrounds behind the product, ensure product fidelity, and optionally incorporate style guidance from another image? Propose a complete solution pipeline, outline your approach to data filtering and training, and discuss how you would evaluate quality at scale.
Additional details:
No modifications to product pixels are allowed. The core objective is to realistically fill the surrounding scene. You have access to a segmentation model that may not be perfect. You also have a proprietary visual embedding engine that captures fine-grained visual features. You are asked to deliver a robust system that can generate multiple styles per product.
Detailed solution
Model architecture and backbone
Use a latent diffusion model as the starting point. It operates in a lower-dimensional latent space to reduce computational costs. Map images into latent representations with a Variational Autoencoder (VAE). Then feed latents plus text embeddings from a pre-trained language encoder into a UNet-based diffusion backbone.
Base model training
Train on large-scale caption-image pairs. Filter out low-quality or unsafe images. Convert images to latents using the VAE encoder, add noise at random timesteps, and train the diffusion model to reconstruct the original latents conditioned on text embeddings.
Background inpainting approach
Adopt a two-stage fine-tuning process. First, adapt the base diffusion model to inpainting by randomly masking image regions and training it to fill in missing parts. Then switch to a product-centric dataset, where real product images have segmentation masks for the product silhouette. Provide these masks as additional inputs. Preserve product pixels exactly and only generate new backgrounds in empty regions.
Retrain the VAE to incorporate mask information. This eliminates blending artifacts around the product boundaries. When generating final outputs, decode the latents to the pixel space with no discontinuities. Generate multiple variations per product and select the best ones with a reward model that scores realism, aesthetics, and lack of defects.
Style conditioning
Incorporate an adapter network that processes a style image. Produce style embeddings with your proprietary visual embedding engine. Feed these embeddings into the diffusion UNet in parallel with text embeddings. Jointly fine-tune on the inpainting task plus style guidance to direct the background appearance.
Scaling and evaluation
Capture product diversity, textual descriptions, and style images. Evaluate with automated metrics (inception-like scores, aesthetic classifiers) and human judgments. Maintain guardrails by ensuring trust and safety guidelines. Integrate real-time feedback to further refine the model for new product categories or styles.
What if questions
How would you modify the forward diffusion formula for the inpainting process?
Noise is still added according to a diffusion schedule, but the product region remains untouched. One way is to keep product pixels fixed and only apply noise to masked areas. The main denoising target for masked regions is the correct latent, while product latents remain unchanged. A standard forward diffusion step for an image latent x_{t-1} to x_t with a noise variance beta_t might be expressed in plain text as:
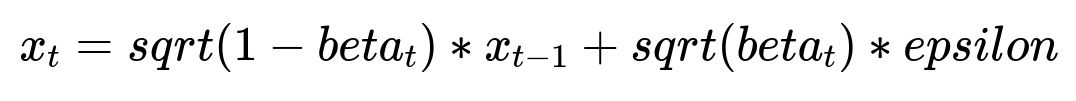
x_{t-1} is the latent at the previous timestep. beta_t is the noise variance. epsilon is a random sample from a normal distribution. For inpainting, skip adding noise to product latents. Only apply noise to background latents. This preserves the product region and ensures fidelity.
How would you handle segmentation errors from the product masks?
Retrain the model to handle borderline inaccuracies. Consider a softer mask approach if you want dynamic lighting or slight adjustments near the edges. Introduce an extra confidence map that marks uncertain edges, allowing partial updates within a narrow band. Validate that product shape is unaltered. Even if a small fraction of pixels is incorrectly masked, the model can correct it if it recognizes an obvious boundary mismatch.
How would you incorporate a personalization feature based on user boards or favorite product styles?
Embed those images with the proprietary visual embedding engine. Pass those embeddings into the diffusion model as additional conditioning. Fine-tune the model in a multi-condition setting: text for background description, product mask for shape constraints, and style embeddings for color palette and mood. Use a gating mechanism or attention layers within the UNet to blend style guidance with textual instructions.
How do you ensure user and brand trust?
Maintain a strict policy that product pixels remain intact. Build real-time checks for any hallucination that distorts product shape or color. Monitor outputs with a dedicated safety classifier that flags misalignment. Create a feedback loop with domain experts to review suspicious generations and refine the training or masking strategies.
How would you evaluate performance in an e-commerce context?
Measure click-through rate if these images are shown to users. Track user engagement and purchase intent. Build an internal tagging system for aesthetic quality and brand consistency. Run A/B experiments with small subsets to gauge conversion lifts. Combine these with human visual inspections for immediate regression checks when new training data is introduced.
How would you accelerate inference at scale for millions of product images?
Precompute style and text embeddings. Use quantized or pruned versions of the diffusion UNet. Deploy distributed inference clusters with model parallelism. Cache partial computations for the product region. Only run the diffusion steps for masked areas. When generating multiple proposals, shorten sampling with advanced schedulers or partially reuse noise samples to reduce repeated work.
How would you handle out-of-distribution prompts?
Build a text filter for unusual or harmful prompts. Restrict generation of scenes that might cause policy violations. Retrain the model with negative prompts or adversarial data to improve robustness. Include placeholders for unknown objects in the background. Incorporate few-shot adaptation steps if new product categories appear with insufficient training examples.
How would you tune hyperparameters for better visual detail?
Optimize noise schedule beta_t to balance coarse structure reconstruction and fine details. Increase the scale of VAE bottleneck dimensions. Fine-tune cross-attention blocks for sharper edges. Experiment with more UNet layers or switch to a Transformer-based diffusion backbone. Monitor FID-like scores on held-out sets and compare visual clarity with manual tests.
How would you mitigate repetition in generated backgrounds?
Deploy diversity prompting by adding randomization in the style or textual description. Sample multiple seeds to produce variations. Force certain cross-attention layers to attend more strongly to text or style embeddings if repeated patterns appear. Adjust the classifier-free guidance scale to encourage broader exploration. Filter out near-duplicate results with a similarity threshold.
How would you integrate a reinforcement learning approach?
Train a reward model on user engagement signals (clicks, dwell time). During sampling, rerank or adapt the diffusion steps to produce backgrounds that maximize the reward. Consider Reinforcement Learning from Human Feedback (RLHF) with pairwise comparisons. Combine it with standard diffusion training by mixing RL steps that guide background style or compositional creativity with stable reconstructions of the product.