
ML Case-study Interview Question: Securing LLMs: Filtering Token Injection Attacks Using Repetition Ratios


Browse all the ML Case-Studies here.
Case-Study question
You are leading a Data Science team at a major technology company. Your team integrates a popular Large Language Model (LLM) to power advanced text generation features. Users can supply custom prompts, which then pass to the model for contextual responses. Soon you notice that prompts containing repeated sequences cause the model to ignore system instructions, produce nonsensical or disturbing outputs, and even leak memorized training data. You also see that these prompts can create excessively long-running model calls, impacting infrastructure costs.
How would you:
Detect and mitigate these repeated token injection attacks,
Prevent extraction of memorized training data,
Safely handle edge cases like partial repeats or truncated sequences,
And maintain overall system reliability and alignment with minimal impact on user experience?
Propose an end-to-end plan covering detection logic, prompt filtering, and risk mitigation. Consider short- and long-term strategies. Provide relevant code snippets, system architecture ideas, and specific performance trade-offs.
Detailed Solution
Security research shows that repeated token sequences in prompts can push an LLM to produce unexpected outputs. The LLM may revert to a low-level language model objective and leak training data fragments. This phenomenon can appear with single- or multi-token repeats.
Core Detection Logic
Many repeated token attacks share a common signature: an unusually high frequency of certain token patterns. One practical detection approach is to measure how many unique tokens appear relative to the total token count. If the ratio is too low, it suggests suspicious repetition.
Use a repetition ratio defined by:
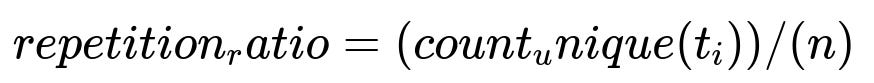
where:
count_unique(t_i)is the count of distinct tokens in the prompt.nis the total number of tokens in the prompt.
If repetition_ratio is below a threshold (for example, 0.7), reject or sanitize the prompt. Adjust this threshold based on real traffic patterns to minimize false positives.
Prompt Filtering
When the system receives a prompt:
Tokenize the prompt with the same tokenizer that the LLM uses.
Compute the repetition ratio (or a similar metric).
If the ratio is under the threshold, either block the request or truncate the repeated token segments before passing it to the LLM.
Example Python snippet for partial filtering:
import tiktoken
def filter_prompt(user_prompt, ratio_threshold=0.7, max_length=4000):
encoder = tiktoken.get_encoding("cl100k_base") # Example tokenizer
tokens = encoder.encode(user_prompt)
unique_tokens = set(tokens)
repetition_ratio = len(unique_tokens) / len(tokens) if tokens else 1
if repetition_ratio < ratio_threshold:
return "Request blocked: repeated token pattern detected."
# Also limit prompt length to avoid extreme usage
if len(tokens) > max_length:
tokens = tokens[:max_length]
return encoder.decode(tokens)
Training Data Extraction Concerns
Repeated token attacks can bypass top-level alignment safeguards and reveal memorized model text. Mitigation includes:
Prompt-based filtering (as above).
Rate-limiting for suspicious requests that appear to be forcing large outputs.
Defensive server-side timeouts to cut off indefinite loops.
Long-Running Requests
Requests that prompt the model to output huge volumes of text can create a denial of service vector or inflate costs. Limit max_tokens in the model call. Track suspicious query patterns and terminate them after a certain runtime.
Maintaining Alignment
Even with prompt filtering, attackers may try creative bypass strategies (e.g., multi-token repeats). Update your detection pipeline frequently. Use an iterative approach to identify new token patterns. Add dynamic checks for known suspicious token sequences (e.g., discovered phrases like jq_THREADS or /goto maiden).
Example Architecture Flow
Incoming request arrives with user prompt.
Tokenizer processes the prompt to identify tokens.
Repetition ratio check runs. If suspicious, return an error or partial acceptance with sanitized text.
Rate limiter and timeout layers apply extra controls for large or repeated requests.
LLM call proceeds with the filtered prompt if safe.
Post-processing scans the response for unexpected leaks (optional step, depending on risk tolerance).
Monitoring and Iteration
Continuously log suspicious prompts, evaluate false positives, and refine thresholds. Store truncated or filtered versions for debugging. This ensures rapid adaptation to new attack variants.
Follow-Up Question 1
How do you handle adversaries who distribute the repeated tokens across the prompt in smaller segments to evade a simple threshold check?
Answer and Explanation
They might insert repeated tokens in chunks to avoid an obvious ratio drop. One solution is to track local repetition patterns. Instead of only a global repetition ratio, apply a sliding window to measure local densities of identical or related tokens. If a particular token (or sequence of tokens) appears excessively within small windows, flag it as suspicious. Implement a second pass that detects partial or interleaved repeats. Adjust the threshold by analyzing genuine user prompts to reduce false positives.
Follow-Up Question 2
What if an attacker tries to force the LLM to output repeated tokens even if the prompt is normal?
Answer and Explanation
Attackers can instruct the model to "repeat the word X forever." The user input might look benign until the LLM is asked to output huge repeating segments. Mitigate by:
Enforcing a max_tokens limit in the model call, so large repeated outputs get truncated.
Stopping the generation if partial outputs already exceed a length limit.
Logging suspicious repeated outputs. If the LLM starts spamming the same token, terminate the response and report it.
Follow-Up Question 3
How would you prove that a suspicious output snippet is memorized training data rather than random text?
Answer and Explanation
Check if large contiguous sequences match known external text sources. For example, compare the snippet to reference corpora or repositories (e.g., a GitHub codebase). If there's a long exact match with improbable length and token alignment, the snippet is likely memorized. Statistical randomness tests help, but exact substring matches in large blocks are more conclusive.
Follow-Up Question 4
Would you consider substituting suspicious tokens rather than outright blocking them?
Answer and Explanation
Substitution is viable if partial user requests need preservation. For instance, if only 10% of the prompt is repeated tokens, replacing them with placeholders might preserve the rest of the prompt’s context. Ensure the substituted sections do not degrade overall user experience. Set up robust logging to keep track of these substitutions and watch for false positives.
Follow-Up Question 5
How do you optimize performance and cost when scanning large prompts?
Answer and Explanation
A fast tokenizer is crucial. For each incoming prompt, store token frequencies in a lightweight data structure (e.g., a hash map). Simple integer counters let you compute the repetition ratio in a single pass. For large prompts, stream the prompt text in batches to the tokenizer. If you detect an anomaly early, stop processing to save resources.
Follow-Up Question 6
How would you integrate these strategies into a production environment?
Answer and Explanation
Place the filtering layer before the LLM gateway:
Build a microservice or middleware that runs repetition checks, timeouts, and length validations.
Maintain configuration in an external data store so updates happen without redeploys.
Log final decisions. Track metrics like average tokens per prompt, ratio distributions, and block rates.
Continuously refine thresholds based on real usage. Use an A/B test with certain user groups if needed.
Be thorough with unit tests to validate detection logic. For critical paths, incorporate chaos experiments to ensure that blocking or substitution logic never disrupts normal prompts.