
ML Case-study Interview Question: Tracking Multilingual Healthcare Queries with NLP and TF-IDF Analysis


Browse all the ML Case-Studies here.
Case-Study question
A consumer healthcare company has four over-the-counter products. They receive customer queries via social media channels in multiple languages. They want to track emerging trends and patterns in these queries. The raw data includes customer questions, timestamps, languages, and other textual information. Some of the queries are in English, others in non-English languages. Personally identifiable information is removed. They want a system that processes this data, identifies top keywords for each product based on relevance, maps them to pre-defined categories, and displays the results in a dashboard. Propose an end-to-end machine learning solution. Outline your approach for data ingestion, handling multilingual text, extracting significant terms, categorizing these queries, and setting up a dashboard to monitor trends over time. Recommend relevant libraries or tools. Highlight privacy considerations. Suggest how you would handle data drift and out-of-vocabulary queries. Explain how you would ensure the system remains robust if new products or languages are added.
Provide a comprehensive plan that addresses these technical challenges and demonstrate how you would deliver value with this solution.
Detailed In-Depth Solution
Data Ingestion and Preprocessing
Data is ingested from social media via an internal pipeline. The dataset has multiple languages. Queries in non-English languages are converted into English through a translation library. Next, text is normalized by removing extra punctuation, stop words, and numeric tokens. All terms are lowercased, then lemmatized and stemmed.
Determining Relevant Keywords (TF-IDF)
To find top words driving consumer queries, TF-IDF is used to measure relevance. Each query is seen as a document. Each distinct term is scored. High-scoring terms are important for that query relative to the entire corpus.
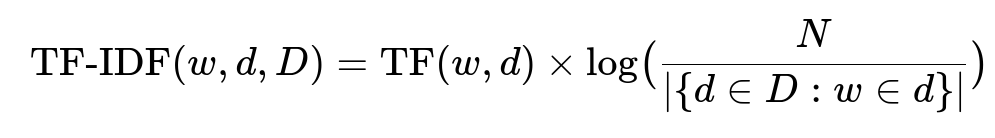
TF(w,d) is the frequency of term w in document d. N is the total number of documents. The denominator counts how many documents contain w. A large TF-IDF means the term appears often in a given document but rarely in the broader dataset. Sorting by TF-IDF helps identify top words for each product.
Categorizing Queries
Each query is assigned to a category by matching high-scoring words against a set of pre-defined textual descriptions. Fuzzy string matching can handle typos or partial matches. The outcome is a lookup structure that links each query to one or more relevant categories.
Dashboard
A dashboard aggregates the transformed data. It shows query counts and top words over time, sorted by product and geography. Stakeholders can see trends and quickly detect shifts in user concerns.
Implementation Example in Python
import pandas as pd
from googletrans import Translator
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer, PorterStemmer
from sklearn.feature_extraction.text import TfidfVectorizer
import fuzzywuzzy.process as fz
# Sample pipeline
df = pd.read_csv("queries.csv")
translator = Translator()
lemmatizer = WordNetLemmatizer()
stemmer = PorterStemmer()
def normalize_text(text):
# Translate if not English
# translator.detect() can be used if needed
translated = translator.translate(text, src='auto', dest='en').text
# Remove punctuation, stopwords
words = [w for w in translated.lower().split() if w not in stopwords.words('english')]
# Lemmatize and stem
final_words = [stemmer.stem(lemmatizer.lemmatize(w)) for w in words]
return " ".join(final_words)
df["processed_text"] = df["query"].apply(normalize_text)
tfidf_vectorizer = TfidfVectorizer(ngram_range=(1,2), max_features=250)
X = tfidf_vectorizer.fit_transform(df["processed_text"])
# Fuzzy matching
search_keywords = ["example_keyword_1", "example_keyword_2"] # etc.
def get_category(text):
best_match, score = fz.extractOne(text, search_keywords)
return best_match if score > 80 else "Uncategorized"
df["category"] = df["processed_text"].apply(get_category)
df.to_csv("transformed_output.csv", index=False)
Privacy Considerations
Data includes consumer text. All personal data is removed before any analysis. Only aggregate insights are stored in the final system. You ensure compliance with all relevant data protection regulations.
Handling Data Drift and Expanding Coverage
Data drift is inevitable. Shifts occur in language usage and trending topics. Retrain the TF-IDF model periodically on fresh data. Maintain an updated keyword list. For new products or languages, integrate them into the pipeline by extending the translation step and retraining the vectorizer with the expanded vocabulary.
Maintaining System Robustness
If text arrives in new languages, the translation step adapts. If new query types emerge, update the category lookup. The entire process must be re-run with incremental retraining so the system captures novel patterns.
How do you measure system performance during deployment?
Evaluate the system with manual verification of assigned categories. Measure accuracy by sampling queries and checking correct classification. Track how often queries remain “Uncategorized.” If that rate rises, update fuzzy matching thresholds or add new categories. Evaluate user satisfaction with the dashboard’s relevance. Confirm stability over multiple time frames.
Why are lemmatization and stemming both performed?
Both help normalize variants of a word. Lemmatization maps words to meaningful base forms while stemming removes suffixes. Combining them extracts the root more aggressively. This helps group semantically related terms. If lemmatization fails on certain terms, stemming can still unify them into a simpler root.
How would you handle polysemy in top keywords?
Polysemy arises when a single term has multiple meanings. If a term is ambiguous, check its context by reviewing surrounding words in the same query. One approach is to apply bigrams or short phrases rather than single words. Another approach is to train a more advanced embedding-based model that captures context.
What if users post queries with heavy misspellings or slang?
Fuzzy matching and partial string matching handle small typos. For severe spelling deviations or colloquial usage, you can maintain a dynamic dictionary or embed advanced language models that can learn slang patterns from large corpora. If certain slang is localized, incorporate region-specific text normalization modules.
How would you integrate advanced NLP models?
Replace TF-IDF with contextual embeddings from transformer-based models. For instance, encode queries using a pre-trained model, then cluster these embeddings or classify them with a fine-tuned transformer. Embeddings often capture richer semantic context, reducing the need for heavy text normalization steps.
How do you ensure explainability with advanced models?
Use methods like attention visualization or local interpretable model-agnostic explanations. For each classification decision, retrieve top contributing terms. Combine these insights with a simpler TF-IDF reference, so stakeholders see how each query maps to a final category.
What improvements might you propose after initial deployment?
Expand coverage to multiple data sources like chatbots or emails. Incorporate sentiment analysis to see how strongly consumers feel about each issue. Explore zero-shot classification techniques for rapidly adding new categories. Track real-time trends and alerts. Integrate automatic risk detection to flag safety concerns.