
ML Case-study Interview Question: Real-Time Next File Prediction with Neural Networks and Learning-to-Rank


Browse all the ML Case-Studies here.
Case-Study question
A growing platform wants to predict the next file a user is likely to open. They maintain massive file activity logs showing how users open, share, or edit files. They also track contextual factors such as device, time of day, and recent collaboration events. They want a system that surfaces the most relevant files on the user’s home page in real time. Design and optimize this system end-to-end, covering data ingestion, model training, deployment, and user-facing metrics.
In-depth solution
Starting with the data ingestion steps, gather recent file activity from each user. Limit the candidate list to a manageable number of files instead of scanning the entire collection, which could be extremely large. Retrieve metadata about each file’s access history, user collaboration history, and file-specific attributes (such as file type).
Build heuristics as an initial approach. Combine simple rules such as recency of file access and frequency of file usage. If a file is accessed repeatedly and also accessed recently, prioritize it. Include a threshold to avoid returning irrelevant files that only had automated or trivial activity, like virus scans.
Log how users interact with these heuristic suggestions. Use these logs to refine thresholds, measure precision (the fraction of shown files that get accessed soon afterward), and measure recall (the fraction of accessed files that were also shown to users). Clean up anomalies like programmatic file opens or short-lived clicks.
Switch to a machine learning model for improved scalability. Represent each file and user context as a vector of numerical features. For classification, generate positive samples from actual file opens and negative samples from similar but unused files. Store historical snapshots so the training data reflects file rankings at the time the user opened a file. Encode features (for example, recency rank or whether a collaborator accessed the file) to capture meaningful signals.
Use a simple linear classifier such as a Support Vector Machine for version 1. Train it with a standard classification objective, such as binary cross-entropy or hinge loss. Score each candidate file by predicting its probability of near-future access. Rank files by that score and present the top few suggestions.
Improve performance by adopting a neural network. This handles nonlinear interactions in the data, such as “on a phone in the morning, user often opens files of type PDF.” Feed discrete inputs (like user IDs or file IDs) into learned embeddings that produce continuous vector representations capturing hidden similarities. Experiment with a learning-to-rank (LTR) formulation that specifically orders positive file examples above negative ones, rather than treating them as independent binary outcomes.
Maintain an offline hit ratio metric. For each suggested file, log if the user opened it within a short time window, regardless of how they navigated. This metric avoids direct dependency on the user interface design. Track it alongside online metrics like click-through rate (CTR), because the user might open the right file another way if the user interface does not display enough context.
Handle edge cases such as newly created folders or newly saved screenshots. Log real-time changes so the system can surface them. If the pipeline cannot pick up those new events quickly enough, merge heuristic rules to fill short-term gaps.
Optimize the system’s latency by parallelizing the retrieval and scoring for each candidate file. Store user and file features in a fast-access data store. If scaling becomes costly, incorporate caching or more advanced data-partitioning approaches. Verify real-time permission checks to ensure only authorized files are displayed.
Continuously iterate. Inspect mislabeled training data such as accidental short clicks or automated file accesses. Explore new contextual signals, such as external collaborator actions. Balance between global models (one model for all users) and more specialized approaches (personalization per user or user cluster). Measure final impact by running controlled A/B tests, ensuring design changes do not confound the results.
Use strong logging and monitoring to capture feedback, track training data quality, and watch for regressions. If newly added signals reduce model performance, remove or revise them. Release carefully, and keep verifying that the system remains accurate and scalable as user behavior shifts.
What if you need to do binary classification?
One approach is to produce a probability that a user will open a file within the next time window. A standard logistic regression model can help. Represent the features of file i as vector x_i. Produce a score via w^T x_i + b and pass it through the logistic sigmoid function.
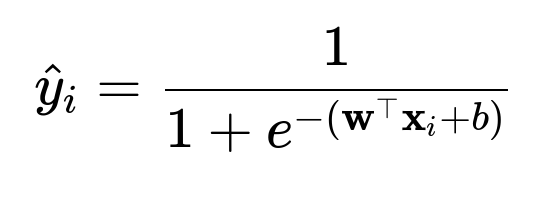
Here, w and x_i are weight and feature vectors in text form. The result is the probability that the user will open file i. Rank files based on that probability.
How do you incorporate a learning-to-rank approach?
Learning-to-rank focuses on ordering files so any opened file appears ahead of non-opened files. A pairwise ranking loss enforces a margin between the scores s_i and s_j of positive file i and negative file j.
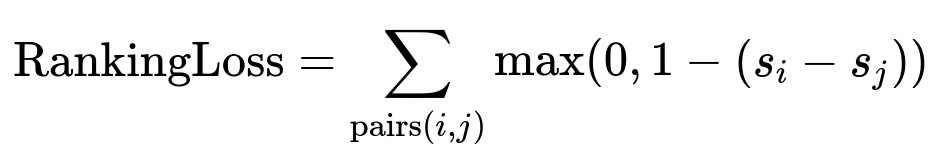
Here, s_i is the predicted score for file i, s_j is the predicted score for file j. If the margin is satisfied, the loss is zero. Otherwise, it penalizes the model until it ranks positive files higher.
Follow-up question: How do you address potential user interface influences on your ML evaluation?
Measure an offline hit ratio. After ranking files, check if the user accesses any of them later by a different route. That measure decouples UI design from model accuracy. Also consider longer windows (like hours rather than minutes) to capture any delayed file uses. Adjust the UI iteratively, but keep a stable hit ratio measure in the backend logs.
Follow-up question: How do you handle imbalance in training data?
Downsample negative samples. Balance the ratio of positive and negative examples so the classifier trains effectively. Restrict your negative set to the most recent or relevant files to match the actual prediction scenario. Keep enough negatives to reflect real-world distributions without overwhelming the positives.
Follow-up question: Why did you use embeddings?
Embeddings cluster items with similar usage patterns in a high-dimensional space. Files that share the same collaborators or exhibit similar open patterns end up close in this space. This captures hidden relationships that linear or raw one-hot encoded features might miss. Embeddings let the model learn from large, diverse user-file interactions.
Follow-up question: How do you ensure your system scales when users have millions of files?
Parallelize the candidate fetching. Distribute the feature generation pipeline so each file is processed independently. Cache or store partial results, such as recent user-file interactions, in a fast-access format. Only score the most recent and frequently accessed files, rather than the entire corpus. Monitor latency and scale hardware or parallelism as needed.
Follow-up question: How do you prevent overfitting to user-specific behavior?
Add regularization to the model, such as weight decay in neural networks or constraints in Support Vector Machines. If you train large embeddings, also regularize them to prevent over-specialization for certain users. Maintain a global perspective so the model can generalize user behavior patterns while still allowing subtle personalization.
Follow-up question: How do you handle newly created files that lack historical data?
Introduce a short-term heuristic. As soon as a user creates a folder or file, give it a default boosted rank. Update the rank once enough interactions appear. Also monitor signals such as user renaming or user’s immediate pattern after creation. This ensures new items do not get buried until they accumulate enough access history.
Follow-up question: Could you improve predictions using content-based signals?
Yes. Analyze file text or metadata to spot relevant keywords, file type usage, or topics. Build embeddings of file content or tags. Incorporate them as additional features. Ensure you address privacy constraints and do not expose sensitive data. Track if textual similarity helps users when they frequently open files on the same topic.
Follow-up question: How do you manage collisions when multiple candidate files have similar scores?
Sort them consistently or break ties by recent activity. Introduce small randomization to let the model learn from user actions when multiple files are scored nearly identically. Observe user clicks or non-clicks on tie-breaker items to refine final ordering strategies.
Follow-up question: How do you perform final validation before rolling out?
Run offline validation on a hold-out dataset. Confirm improvements in the hit ratio. Run an A/B test with a small fraction of real traffic. Compare click behavior and other engagement signals. If metrics improve significantly and no adverse effects appear, expand rollout gradually. Keep real-time logging to spot drift or anomalies post-launch.
This approach covers the architecture, training methodology, evaluation strategies, and follow-up questions to test a candidate’s mastery in real-world data science work.