
ML Case-study Interview Question: Building Secure Enterprise Summarization & Search with Private Cloud RAG


Browse all the ML Case-Studies here.
Case-Study question
A global enterprise sought to add an AI-driven summarization and improved internal search tool across its communication platform. They needed a highly secure, private solution that respects existing compliance rules and data governance standards. Retrieval Augmented Generation was considered, but they faced challenges with large context windows, the requirement to keep data within their Virtual Private Cloud, and the need to ensure secure integration with an off-the-shelf Large Language Model. Propose a full architecture and strategy that addresses these requirements. Explain how you would set up the solution end to end, specify how it handles data privacy, outline the role of Retrieval Augmented Generation, and detail how you would evaluate and tune the model. Suggest ways to integrate enterprise security features for compliance. Discuss how you would keep the system scalable. Provide technical details, including how to orchestrate the model in a cloud environment.
Proposed Solution
Overall Architecture
The plan uses an internal orchestration service to route requests from the communication platform to a hosted Large Language Model. This model is hosted in a private Virtual Private Cloud (VPC). The enterprise sets up an escrow arrangement so the foundational model remains closed-source to external parties, yet user data never leaves the enterprise’s VPC. This ensures compliance requirements such as FedRAMP remain intact. The pipeline has an internal microservice to retrieve user-permitted data. That microservice merges it into a prompt context that is passed to the model for summarization or search tasks.
Retrieval Augmented Generation
RAG takes user input and fetches relevant internal data chunks via specialized retrieval logic. The Large Language Model then processes that input plus retrieved data in a single forward pass, without retaining state between calls. The approach remains stateless. This prevents the model from training on or persisting any customer data.
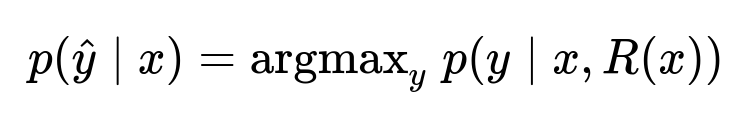
Here, p(\hat{y} | x) is the probability distribution over possible outputs given the original input x. R(x) is the retrieval function that selects documents or messages based on x. The model uses x plus R(x) to generate the final output y. The approach ensures no cross-user data mixing occurs inside the model. The user’s existing Access Control Lists filter data that is retrieved.
Model Hosting in a Cloud Environment
AWS SageMaker or a similar managed environment hosts the Large Language Model inside the enterprise’s trusted boundary. The enterprise obtains closed-source model binaries but never releases raw data to the model provider. The model processes each request in real time, returning the summarized or searched answer. The architecture ensures ephemeral usage of the user data: no logs of raw user data persist beyond the immediate inference call.
Compliance and Security
The system uses encryption in transit and at rest. Key Management Services handle encryption keys. Messages and derived outputs are invalidated if the original messages are removed or flagged by Data Loss Protection. The service reuses the existing permission model, ensuring that only a user who has permission to see certain messages can receive them in a summary or search result. This preserves privacy and granular access rules.
Model Evaluation and Tuning
Manual prompt engineering, sampling from user-like inputs, and measuring correctness are the first steps. Team members compile domain-relevant examples and systematically test them. The approach uses a combination of standard text similarity metrics and manual review. If certain summarization tasks are too large, the team refines chunking strategies or uses the best available LLM with a large context window. For final tuning, manual iteration adjusts the system’s prompt instructions. Traditional Machine Learning classifiers can run in parallel to reduce the burden on the LLM for tasks like ranking or spam detection, allowing the LLM to focus on summarization or search tasks only.
Scalability
Multiple model endpoints are deployed for parallel inference. Horizontal scaling with more endpoints handles surges of requests. Autoscaling logic spins up more instances as concurrency grows. A caching layer stores partial intermediate embeddings or retrieval results to reduce overhead. This helps achieve faster response times and consistent user experience under high load.
Follow-up Question 1
How would you handle potential spikes in usage for summarization requests when large channels with many messages need summarizing?
A common approach splits the channel history into smaller chunks. The orchestration service processes each chunk separately, then merges the partial outputs. Each chunk is sent asynchronously to model endpoints, which are autoscaled based on CPU and GPU metrics. A caching strategy for retrieval steps helps reuse partial embeddings if the channel is frequently summarized. Breaking up requests by chunking messages in the aggregator phase prevents model timeouts or memory issues.
Follow-up Question 2
What are the biggest risks in using an off-the-shelf Large Language Model in your own VPC, and how do you mitigate them?
Risks include performance unpredictability under stress, memory overhead for large models, and ensuring the model binaries remain secure. Mitigation uses thorough load testing, capacity planning, and continuous monitoring. For model security, the environment locks down outbound network paths to prevent data exfiltration. Routine patching and strict role-based access control limit who can modify or retrieve the model container. Detailed audits ensure compliance.
Follow-up Question 3
How would you prevent leaking private data across different workspaces or projects?
The retrieval function respects Access Control Lists. When a user triggers summarization or search, the retrieval step fetches only data they have permission to view. The final summary or search result is constructed from that permissible set. This ensures no user sees data from channels they cannot access. The model itself remains stateless, so it never retains user data across requests.
Follow-up Question 4
What techniques would you use to test your summarization feature for correctness, relevance, and security before launching?
A curated dataset of realistic channel messages, along with test inputs that push edge cases, forms the base. Synthetic data is generated for scale testing. The security aspect is tested by verifying that messages from restricted channels never appear in the summary output. Human reviewers rate the summaries for accuracy and completeness. Traditional text similarity scores measure closeness to a reference summary. Usability tests confirm that the summarization captures essential context. Logging is anonymized, and data sampling is limited to test environments to protect user privacy.
Follow-up Question 5
How would you integrate or combine multiple ML models for better efficiency and reliability?
A smaller classification model can pre-check user queries and filter them. For instance, it flags queries that are not best served by the LLM (e.g., short queries with no need for advanced reasoning) and routes them to a simpler search index. Another model can handle tasks like entity extraction or sentiment detection. These specialized models run quickly, and the more expensive LLM is only called when deeper summarization or generative abilities are needed. This layered approach improves speed and reduces system load.
Follow-up Question 6
How would you handle user data storage and logging given compliance considerations?
User messages are encrypted at rest, and the logs do not contain raw message data. Logs store only reference IDs and minimal metadata for debugging. Summaries are ephemeral if possible. If summaries must be stored (for instance, pinned to a channel), they remain subject to the same encryption and compliance rules as the original messages. If a message is purged via Data Loss Protection, the system invalidates any derived summaries. This ensures that all downstream artifacts obey the same lifecycle as the source data.
Follow-up Question 7
What would your Python service orchestration code look like for retrieving data and sending a request to the hosted LLM?
Example code:
import requests
def retrieve_data(user_id, channel_id):
# Query your existing access-checked database
# Return only messages user_id can see
messages = fetch_messages_for_user(user_id, channel_id)
context = "\n".join([m['text'] for m in messages])
return context
def summarize_context(context):
# Prepare the prompt for the LLM
prompt = f"Summarize the following content:\n{context}"
# Endpoint for the model
endpoint_url = "https://yourinternalvpc.llm.endpoint/summarize"
response = requests.post(endpoint_url, json={"prompt": prompt})
return response.json().get("summary", "")
def generate_summary(user_id, channel_id):
context = retrieve_data(user_id, channel_id)
if not context:
return "No data to summarize"
summary = summarize_context(context)
return summary
The retrieve_data function ensures that only messages accessible to the requesting user are fetched. summarize_context handles prompt creation and sends an HTTP POST to the private LLM endpoint. The system logs only reference IDs. This pattern preserves compliance while offering a high-level architecture for summarization.
Follow-up Question 8
How would you handle scaling if the model endpoint slows down when many users generate summaries at once?
Autoscaling rules monitor average latency and resource usage. When thresholds are exceeded, more model-serving instances launch. A load balancer spreads traffic. If usage spikes beyond capacity, requests queue in a short-lived buffer until an instance is free. Timeout policies return a graceful message if the queue is too long, preventing endless wait times. This ensures the platform remains responsive.
Follow-up Question 9
How would you address false information issues in AI-generated summaries?
A measure is to embed reference links into each section of the summary. The user can check the original messages from which the summary was generated. If the system produces errors, user feedback and continuous iteration on prompt instructions help improve outcomes. The enterprise may add simpler rule-based constraints to remove improbable statements. The RAG approach also reduces hallucinations by grounding the generation in a verified context.
Follow-up Question 10
How would you handle future expansions, such as turning these summaries into external knowledge base articles?
A pipeline can extract validated summaries and store them in an external knowledge base. The system tags these with appropriate metadata for retrieval. Only data that meets compliance checks would exit the ephemeral pipeline. Each external article references the original channel messages, with permission checks preserved. This helps maintain data lineage and ensures you can trace each summary to its source.