
ML Case-study Interview Question: Multi-Phase LSTM & Bias Control for Predicting New E-commerce Winners


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce retailer that partners with thousands of suppliers and offers millions of products faces a cold-start challenge for newly onboarded products. They add more than 200,000 new products each quarter and cannot invest equally in all. They want to design a system that identifies high-potential products at launch or even before (using only product attributes), and then updates those predictions based on emerging signals from early customer interactions. They need to avoid the risk of self-fulfilling bias from increased exposure. They also want a unified modeling approach that can handle diverse product classes and limited data in new classes. Propose a detailed machine learning solution, including how to integrate product images and descriptions, how to factor in time-series customer engagement signals, how to mitigate bias from increased exposure, and how to handle training objectives for different types of outcome variables. Explain all critical steps and discuss how you would measure and evaluate model performance and scalability.
Detailed Solution
One approach uses a multi-phase pipeline for early winner identification. Day Zero Model predicts long-term revenue potential without customer engagement signals. Embedding models process product images and text descriptions to extract visual and semantic characteristics, while numeric properties like wholesale cost act as additional features. A neural network uses these embeddings and numeric features to generate a first-pass score. Items with high Day Zero scores receive better initial sort placements.
Continuous Winners Model refines predictions once early engagement data arrives. The system collects signals like product page views, cart additions, and orders over time. These values form time series data. An LSTM neural network automatically learns short-term and long-term trends, including how different signals move together. Strong positive trends in orders and conversion rates indicate potentially high future sales. The model updates predictions in near-real-time. Products that clear a threshold receive more prominent placements, exclusive partnerships, or special treatment.
Sentinel is a continuous testing framework that isolates exposure-driven effects from genuine product potential. The system withholds or controls certain placements for a subset of products, preventing inflated engagement metrics. This data feeds back into the training pipeline, ensuring models learn intrinsic product attractiveness rather than confusing it with the extra investment effects.
Universal Model Architecture addresses sparse data in niche product classes. The network shares parameters across categories and captures patterns that generalize. Knowledge from richer product classes transfers to newer or smaller categories. The model partitions category-specific nuances at later layers, so fundamental properties of high-performing products remain consistent across categories.
Optimized Training Objectives match the underlying data distribution. Bernoulli or log-normal losses can be used for revenue-based targets. Negative binomial losses are used for count-based outcomes like orders. The next section shows a negative binomial likelihood function often used for order counts.
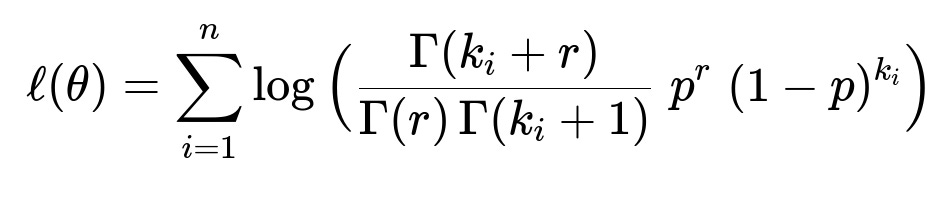
k_i is the observed count of orders for product i. r is a shape parameter capturing the number of failures (or success threshold). p is the success probability. gamma() is the gamma function. n is the number of training examples. theta represents learnable parameters of the model. This objective helps capture over-dispersion in order data, improving predictive accuracy and providing uncertainty estimates.
H4: Example LSTM snippet
import torch
import torch.nn as nn
class ContinuousWinnersLSTM(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, num_layers=1):
super(ContinuousWinnersLSTM, self).__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# x shape: (batch_size, seq_len, input_dim)
lstm_out, _ = self.lstm(x)
# Take last timestep's hidden state
last_hidden = lstm_out[:, -1, :]
out = self.fc(last_hidden)
return out
The network above processes time series of engagement signals (page views, add-to-carts, orders). The final linear layer predicts long-term revenue or order counts. The training loop uses the selected loss function (log-likelihood based on Bernoulli, log-normal, or negative binomial).
H4: Performance Measurement
Model performance is measured via held-out sets and live experiments. Metrics include rank correlation between predicted winners and actual long-term winners. Online A/B tests measure uplift in overall sales and alignment of predicted vs. actual bestsellers. Sentinel ensures exposure bias is controlled, so the system measures true product potential. Real-time inference must keep latency low to handle large catalogs efficiently.
H4: Scalability Considerations
Day Zero predictions rely primarily on offline training. Continuous updates require streaming architectures that feed new engagement data at scale. Parallelizing LSTM training with GPU clusters and sharding large product catalogs are standard strategies. A universal model design cuts down the need for separate models per class. Data pipelines must reliably deliver product embeddings, engagement signals, and experiment group assignments to the training system.
How would you handle missing or incomplete early engagement signals?
Missing signals are inevitable. Neural networks can treat missing entries as masked inputs, or use imputation. A simpler approach is to treat missing data as zeros, but that may reduce accuracy. LSTM-based architectures can incorporate a masking mechanism to ignore absent steps. Another option is to train an auxiliary imputation model that estimates engagement metrics for missing days, using known signals from other similar products. Regularization techniques and careful calibration checks maintain model stability.
How would you evaluate whether this system actually avoids self-fulfilling bias?
The system exposes selected products less or more, then tracks if these changes skew the training data. Sentinel manipulates exposure for random subsets of products. If identified winners continue to perform strongly in withheld subsets, the model likely captures true product potential rather than artificially inflated metrics. Offline analyses compare predicted potential across normal and restricted-exposure cohorts. Statistically insignificant differences in final performance distributions indicate minimal bias. If differences appear, the team refines the exposure randomization strategy or weighting in the training loss.
How do you approach new product classes with almost no training data?
The universal model structure shares learned representations across classes. Early layers capture general signals like product embeddings, pricing, and brand effects. A small portion of class-specific layers or parameters fine-tunes to the new class. Day Zero predictions rely on visual and text embeddings extracted from robust backbone networks. This method often requires transfer learning from established classes, plus small-scale labeled data from the new class for calibration. This ensures the model adapts and maintains performance in previously unseen product categories.
How would you mitigate the risk of overfitting with highly dimensional embeddings?
Deep networks with many parameters risk overfitting. Regularization keeps embeddings controlled. For product images, large pretrained convolutional backbones are often frozen or partially fine-tuned. Language embeddings from pretrained models are similarly handled. Bayesian dropout in the LSTM can help. Another strategy includes early stopping using validation metrics to prevent the model from memorizing noise. Strict monitoring of generalization error on holdout sets gives alerts on potential overfitting.
What is your approach for deciding if continuous winners should receive further investments?
Business teams define thresholds on predicted future sales or order volume. Once a product crosses that threshold with high confidence, it receives enhanced placements or marketing. Confidence intervals derived from the model’s probability distributions inform decisions. If uncertainty is high but potential is large, partial investment with further data monitoring is reasonable. Continual re-scoring every few days ensures quick adjustments to new information.