
ML Case-study Interview Question: Detecting Modified Fraudulent Images Using Siamese Networks and Triplet Loss.


Browse all the ML Case-Studies here.
Case-Study question
A global marketplace faces a surge in fraudulent listings. Criminals take original images from genuine listings, then make small modifications to bypass existing duplicate detection systems. Construct a machine learning solution that identifies these modified images at scale. Propose your end-to-end approach, including dataset preparation, model architecture, loss function choice, and infrastructure considerations for real-time image checks. Justify each step and address how you would optimize for speed, accuracy, and maintainability.
Detailed Solution
Background on the Fraud Detection Challenge
Criminals copy existing product or real-estate images, make slight edits, and repost them as new listings. Traditional hash-based systems struggle with minor alterations, leading to missed fraud. Manual checks do not scale well with large volumes.
Strategy
Start with a Siamese Network framework that transforms images into lower-dimensional embeddings. Use the Triplet Loss to ensure embeddings for near-duplicates are close and embeddings for unrelated images are far. Convert these embeddings into hash representations for fast nearest neighbor checks.
Siamese Network Architecture
A single base convolutional neural network processes all input images. Share weights across parallel branches to create comparable embeddings. Train it to produce similar embeddings for related (modified) images and distant embeddings for unrelated images.
Triplet Loss Formula
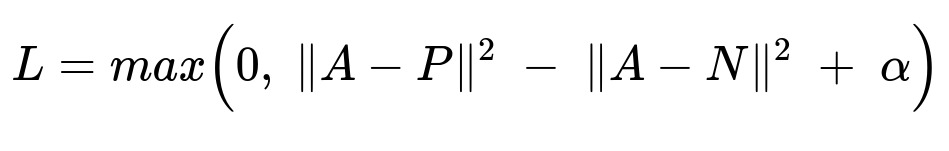
A is the embedding of the anchor image. P is the embedding of a similar (positive) image. N is the embedding of a dissimilar (negative) image. alpha is a margin that ensures separation. Minimizing this loss forces the distance between A and P to be smaller than the distance between A and N, plus the margin.
Training Data Preparation
Augment each anchor image by flipping, cropping, color-jittering, or other small edits. Treat these edited versions as positives. Select negatives from unrelated images. Semi-hard and hard negative examples accelerate learning by ensuring the model focuses on challenging samples.
Transfer Learning
Use a pre-trained backbone (for example, a popular convolutional neural network) to capture general image features. Freeze early layers if needed, or fine-tune the full network on the fraud detection dataset to adapt features to the specific domain.
Embedding Storage and Retrieval
Compute embeddings for all new images. Store them in a vector database or use a hashing scheme. For each new image, retrieve the nearest neighbors by distance. If the distance is below a threshold, classify as fraud. If above another threshold, accept as genuine. Use a moderation step for ambiguous cases.
Example Code Snippet in Python
import tensorflow as tf
base_model = tf.keras.applications.EfficientNetB0(include_top=False, pooling='avg')
# Example for creating a simple embedding model
input_layer = tf.keras.layers.Input(shape=(224,224,3))
x = base_model(input_layer)
x = tf.keras.layers.Dense(128, activation='linear')(x)
embedding_model = tf.keras.Model(inputs=input_layer, outputs=x)
# Triplet Loss (pseudo-code function)
def triplet_loss(a, p, n, alpha=0.2):
pos_dist = tf.reduce_sum(tf.square(a - p), axis=1)
neg_dist = tf.reduce_sum(tf.square(a - n), axis=1)
return tf.reduce_mean(tf.maximum(0.0, pos_dist - neg_dist + alpha))
Each image passes through embedding_model. The triplet loss is computed, and gradients are propagated back through the shared weights.
Practical Considerations
Monitor real-time performance, because calculating distances must happen at scale. Tune thresholds based on false-positive and false-negative rates. Use locality-sensitive hashing or approximate nearest neighbor methods to handle large volumes efficiently.
How would you handle partial duplicates where only a region of the image is modified?
A region-based approach can help. Segment the image or apply multiple overlapping patches. Generate embeddings for each patch and compare patch embeddings with stored patches. The presence of any significantly close match can raise an alert. This strategy is resource-intensive, so standard embeddings often suffice unless fraudsters consistently alter only specific small regions.
Why not rely solely on text-based duplicate detection?
Fraudsters often rewrite or slightly paraphrase text. The visual aspect is a more stable signal. Text-based checks help in parallel, but images are harder to disguise fully without losing essential detail, making them a strong fraud indicator.
How do you choose a threshold for marking an image as fraudulent?
Obtain a validation set of genuine and tampered images. Compute embeddings for all pairs. Evaluate the distance distribution for positive pairs (tampered vs. original) and negative pairs (unrelated images). Find an operating point that balances false positives (legitimate images flagged) and false negatives (undetected fraud).
How would you speed up nearest neighbor retrieval in production?
Index embeddings using approximate nearest neighbor libraries. Use hashing (for example, locality-sensitive hashing) to group similar embeddings. Pre-compute and store these hashed embeddings. This reduces comparison time significantly for large datasets.
If the system receives entirely new images not seen during training, how do you ensure generalization?
Use transfer learning from a broad-domain model. Include diverse examples during training. Encourage the network to learn robust low-level patterns. Maintain continuous retraining pipelines that incorporate newly confirmed fraud samples to keep embeddings current.
How do you mitigate the risk of false positives when images are very similar but genuine?
Set a conservative threshold and incorporate manual moderation for borderline cases. Add domain-specific context (product category, geolocation). If an image is very similar but has different metadata or location, the system can apply a lower suspicion score.
How would you handle adversarial attempts to fool the embedding?
Fraudsters may attempt more complex transformations or adversarial noise. Detect such patterns by periodically retraining on newly collected adversarial samples. Use data augmentation that includes random distortions during training to build a more robust embedding space.
How do you monitor and improve system performance post-deployment?
Track metrics on a rolling basis. Log distances and model decisions. Evaluate flagged images with a human-in-the-loop approach. Update thresholds if systematic drifts appear. Run regular offline experiments on fresh data. Store error cases for incremental retraining.
How does Transfer Learning improve outcomes in this scenario?
A pre-trained model already encodes general shapes, edges, and textures. Fine-tuning on this fraud dataset focuses those encodings on subtle modifications typical of fraud attempts. This accelerates convergence and often boosts final accuracy, even with limited labeled data.
Would you consider other losses or architectures?
Contrastive Loss or newer margin-based losses can also separate embeddings, but Triplet Loss often provides sharper margins for near-duplicates. Other architectures (for example, multi-task networks combining text and image) could help, depending on the data. The core idea remains the same: produce embeddings that cluster similar images together.
How do you measure the final success of this approach?
Monitor metrics including precision, recall, F1-score, and manual moderation overhead. Observe how many fraudulent listings slip through and how many legitimate listings get flagged. Align thresholds and re-check performance. Store these metrics historically to understand improvements or regressions.