
ML Case-study Interview Question: Neural Networks & Sparse Embeddings for Large-Scale Personalized Feed Ranking


Case-Study question
You lead a data science team at a large-scale social platform where the homepage feed needs to surface highly relevant and personalized content for millions of users. The existing feed ranking system relies on standard regression-based or gradient-boosted decision tree models. You want to upgrade it to a massive neural network that can handle new large corpus sparse ID embeddings (such as user ID and hashtag ID). The dataset spans billions of training records with millions of unique IDs. The new model must train quickly on GPUs, serve online with minimal memory overhead, and avoid collisions in ID mapping. How would you design, train, and serve this model end-to-end?
Important details:
Use data sampling strategies or weighting to overcome exposure bias. Efficiently process multi-billion-row data in Spark-based pipelines. Scale the training with multi-GPU, exploit specialized libraries, optimize I/O, and manage memory constraints. Serve embeddings in memory to reduce feature latency. Ensure minimal collisions in ID lookups and stable performance at scale.
Detailed solution
Overview of the approach
Train a large neural network model that combines sparse ID embeddings (for users, items, and hashtags) with standard dense features. Use a multi-stage pipeline that processes all impressions and user interactions to capture the rich interactions among users, items, and hashtags. Build embeddings for each sparse ID in a lookup table, train them end-to-end with the rest of the network, and serve them online to deliver personalized recommendations.
Training data workflow
Process massive daily logs of billions of feed impressions. Ingest records of user actions, such as likes, comments, or reshares, to label training data. Convert string IDs for users and hashtags into integer indices. Use distributed data processing to manage high-volume transformations. Avoid repeated writes of giant intermediate data. Defer materialization of large transformations until the final training step.
Inverse propensity weighting
Use inverse propensity weighting to correct biases introduced by existing ranking models or by random sampling. Weight each training instance by a factor that compares the random sampling click-through-rate (CTR) to the ML-based or production-based CTR. Apply this weight to the cross-entropy loss so the model learns more balanced representations.
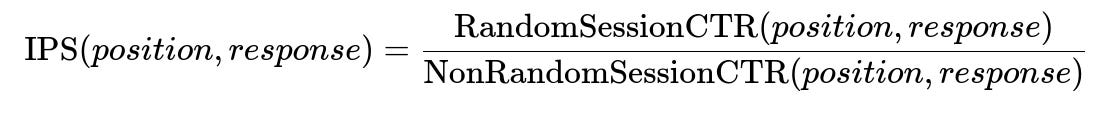
IPS(position, response) is the inverse propensity score. position is the rank of the item in the feed. response is whether the user clicked/liked/commented. RandomSessionCTR is the empirical CTR at that position in a random session. NonRandomSessionCTR is the empirical CTR at that position in a production session.
Model architecture
Use a feed ranking neural network that accepts dense features plus sparse ID embeddings. Merge them into a hidden Multilayer Perceptron (MLP). Introduce gating layers to focus or suppress certain signals. Use wide hidden layers to handle the high complexity from large embeddings. Gate Net logic helps reduce latency overhead while retaining performance gains. Increase the MLP width only within latency budgets.
Embeddings for personalization
Embed users, creators, hashtags, and other IDs to capture semantic relationships. Represent each user in part by the embeddings of the top IDs they have interacted with, aggregated by pooling. Interact these embeddings with relevant dense features. Capture both short-term and long-term user preferences. Retrain often or incrementally to adapt to new content and fresh user behaviors.
Scaling multi-GPU training
Use Horovod or a similar framework for data parallelism. Apply model parallelism to shard large embedding tables across GPUs. Avoid CPU-GPU transfers for repeated ops. Tune read buffer sizes and parallel file reading to handle billions of records. Accumulate gradients for multiple mini-batches before all-reduce to mitigate communication overhead. Optimize memory usage with partial table splits (table-wise, row-wise, column-wise). Exploit hardware concurrency fully without restricting the model to a fixed number of GPUs.
Serving large models in memory
Use specialized hardware with high memory capacity to hold big embedding tables in-memory. Precomputing embeddings offline adds latency and reduces flexibility, so serve them directly inside the main model where possible. Apply memory profiling and garbage collection optimizations. Use data representation techniques like minimal perfect hashing to minimize collisions and reduce memory usage for large ID vocabularies. Deploy final models on clusters of high-memory CPUs or GPU-based serving with minimal overhead.
Collision-free hashing
Generate integer IDs in a collision-free manner. Use minimal perfect hashing to map string IDs to integer slots without collisions. Maintain reasonable lookup time within the feed-ranking pipeline. Reduce memory by compressing the stored key-mapping structure. Keep enough headroom in your serving environment to handle multi-billion parameter models without performance degradation.
Future improvement paths
Keep training times short with incremental or online updates. Incorporate additional advanced layers like DCN (Deep & Cross Network) for more expressive interactions. Offload resource-intensive parts of inference to specialized hardware. Prune or quantize embeddings that are infrequently used. Explore gating or compositional embedding to manage dynamic ID spaces more efficiently.
Possible follow-up questions and exhaustive answers
1) How do you handle the cold start problem for new items or new users who lack interaction history?
Embed each new user or item by mapping them to a hashed ID slot. Rely on neighborhood patterns or partial user attributes for new users. Initialize those embeddings randomly or from an average embedding of similar users. Incorporate backfill data from user profile info or publicly available signals. Combine collaborative filtering signals once minimal data is available. Update the embeddings in subsequent daily or incremental training cycles.
2) Why not just expand the MLP instead of adding embeddings for these sparse IDs?
Dense MLP expansion alone cannot capture the discrete, high-cardinality nature of user or item IDs. Embeddings preserve fine-grained personalization patterns in a lower-dimensional continuous space. This approach scales to millions of distinct IDs. Large MLP layers for each ID would not be memory-feasible or capture item-level context well. Embeddings plus gating preserve relevant signals at scale.
3) How does gradient accumulation address communication bottlenecks when using Horovod?
Horovod synchronizes gradients across GPUs using collective operations like all-reduce. Frequent communication can slow training. Accumulating gradients for multiple mini-batches in a local buffer lowers the frequency of all-reduce calls. Batches are processed locally first. After a set number of batches (e.g., five), the aggregated gradient is synchronized. This batching of communication reduces overhead, accelerates overall throughput, and still converges reliably.
4) How would you ensure embedding table size does not explode with unlimited ID growth?
Prune IDs with extremely low usage. Set thresholds on minimum appearance frequency. Combine or approximate rarely used IDs with compositional or hashing-based embedding. Periodically retrain to remove stale IDs. Keep a limited capacity for each embedding table, and rely on hashing collisions for infrequent IDs while ensuring common IDs get collision-free assignment.
5) What is the rationale behind gating layers in hidden layers?
Use gating to control which feature interactions pass forward. Each gating layer outputs a learned gate factor between 0 and 1 per dimension of the hidden layer. Signals important to the target are passed on, and irrelevant signals are dampened. This allows deeper networks to focus on crucial patterns while ignoring noise. Gating can improve generalization and preserve model capacity without excessive latency.
6) How do you manage partial serving or rollback if something fails after deploying a huge model?
Maintain versioned model storage. Deploy new models to a subset of servers and run shadow traffic or A/B tests. Monitor metrics and ensure resource usage is stable. Fall back to the previous model if issues appear. Keep offline-prepared artifacts for the last working model. Use canary releases and phased rollouts to detect or isolate problematic deployments.
7) How do you approach large-scale memory optimization for online inference?
Use memory profiling tools to understand high-usage areas. Quantize embeddings or use smaller data types (e.g., float16). Apply minimal perfect hashing for ID mapping. Prune rarely used vocabulary entries or embed them in a shared representation. Offload some computations to GPUs or specialized hardware. Reuse memory buffers. Restrict concurrency in certain threads to avoid spikes in memory usage.
8) Why does minimal perfect hashing often trade off latency for memory savings?
Minimal perfect hashing typically requires more complex lookups than a simple array index. The hashing function might involve multiple table lookups or offset computations. This overhead is acceptable given the huge reduction in memory footprint. Collisions are avoided, so the result is still correct. The slight additional cost in lookup time is balanced by the benefits in memory usage and capacity.
9) What is the key advantage of training on “all session” data instead of only heavily engaged sessions?
Restricting to heavily engaged sessions can bias the model toward popular items or active users. The feed might then ignore important but less obvious content or new items. Training on all sessions ensures broad coverage of users and a variety of content. The inverse propensity weighting compensates for differences in how these sessions originated. The model learns more generalized patterns and stays fair to less frequent items.
10) Why is it critical to refresh these large models at a high cadence in production environments?
User interests and item popularity shift rapidly. Stale models fail to capture new hashtags, new popular topics, or emerging user behaviors. High-cadence retraining allows the feed to adapt quickly. Real-time or near-real-time updates handle trending topics and viral content effectively. Slow refresh cycles risk irrelevant recommendations and user dissatisfaction. Large-scale incremental learning or partial fine-tuning addresses these dynamic changes.