
ML Case-study Interview Question: CNN, LSTM, YOLO Image Analysis via Flask API for Social Platform Engagement


Case-Study question
You are leading a Data Science team at a large social networking platform. The platform hosts millions of daily user-uploaded images. The company wants to assess if using deep learning to analyze these images can improve user engagement. You have access to powerful infrastructure, including GPU-enabled servers, and you are free to choose how to deploy your models. How would you build a proof-of-concept system to classify image features (for example, detecting if a user is smiling or wearing sunglasses), generate captions for images (using CNN and LSTM), and detect objects in images (using models like YOLO)? The leadership team wants you to demonstrate the feasibility and estimate potential business impact before fully investing engineering resources. Propose an end-to-end solution, from data preprocessing to model deployment, and discuss how you would handle scalability, model selection, cost constraints, and integration with existing applications.
Detailed Solution
Start by gathering and labeling a representative dataset. Organize the data so that you can rapidly train and evaluate multiple deep learning models. Split the dataset into training, validation, and test sets. The training set is used to learn model weights. The validation set helps tune hyperparameters. The test set is reserved for final performance estimation.
Use convolutional neural networks for feature extraction from images. For classification tasks (such as smiling vs. not smiling, sunglasses vs. no sunglasses), define a clear objective function. A common choice is binary cross-entropy when you have a single binary label. For more granular classification (for example, multiple categories at once), consider multi-class cross-entropy. A typical cross-entropy formula follows below:
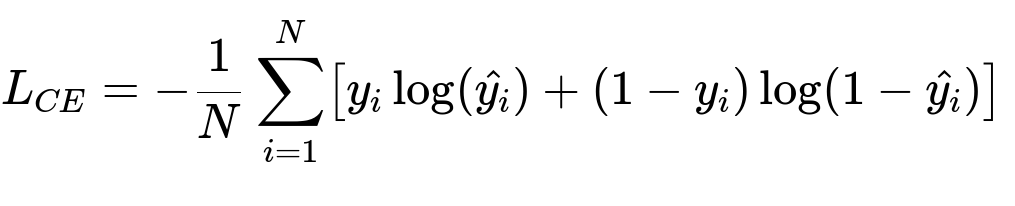
Here, N is the number of training examples, y_i is the true label for the i-th example (1 or 0), and hat{y_i} is the predicted probability for that example being 1.
For textual descriptions, use a CNN to extract image features and feed these features into an LSTM. The CNN encodes the visual content into a feature vector. The LSTM then decodes this feature vector into sequences of words, forming short sentences describing the image.
For object detection, use YOLO or any preferred detection architecture. Train or fine-tune a pre-trained YOLO model so it can detect objects that are important for your specific use cases.
Flask API Infrastructure
Develop a Flask application to wrap model inference logic. Load pre-trained models at startup so that requests can be handled without re-loading the models on every inference call. Below is a minimal Python snippet showing how you might define a RESTful endpoint in Flask:
from flask import Flask, request, jsonify
from flask_restful import Resource, Api
import os
import numpy as np
from keras.preprocessing import image
from keras.models import load_model
app = Flask(__name__)
api = Api(app)
# Load models at startup
smiling_model = load_model('models/smiling.h5')
sunglasses_model = load_model('models/sunglasses.h5')
UPLOAD_FOLDER = os.path.join(os.path.dirname(__file__), 'images')
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
class ImageFeatures(Resource):
def post(self):
img_file = request.files['file']
filepath = os.path.join(app.config['UPLOAD_FOLDER'], img_file.filename)
img_file.save(filepath)
# Predict using pre-loaded models
results = {}
results['prob_smiling'] = self.make_prediction(smiling_model, filepath)
results['prob_sunglasses'] = self.make_prediction(sunglasses_model, filepath)
return jsonify(results)
def make_prediction(self, model, path):
img_w, img_h = 224, 224
img_obj = image.load_img(path, target_size=(img_w, img_h))
img_arr = image.img_to_array(img_obj)
img_arr = np.expand_dims(img_arr, axis=0)
img_arr = img_arr / 255.0
prob = model.predict(img_arr)[0][1]
return float(prob)
api.add_resource(ImageFeatures, '/detect')
if __name__ == '__main__':
app.run(debug=True)
Placing this in a server.py file and running it with python server.py starts the service. An external process (for instance, a front-end or a data engineering pipeline) can then send images to http://localhost:5000/detect and receive inference results.
Scalability and Hosting
Deploy the Flask service on a GPU-enabled server to speed up inference. Pack this environment with Docker to ensure consistency between development and production. Containerizing the service involves creating a Docker image with your dependencies (Python, Flask, Keras, GPU drivers). Once you push the Docker image to a registry, you run a container on your target server:
docker run --gpus all -p 5000:5000 your_docker_image_name
This approach helps teams across the company access your models via a simple HTTP endpoint. It also simplifies horizontal scaling if you need multiple replicas.
Impact Analysis
Evaluate how many images you can feasibly process. If your approach proves valuable for user engagement, plan to integrate these models into the main product pipeline. Measure improvements by experimenting (for example, an A/B test comparing user interactions or likes before and after surfacing photo-quality tips). If cost constraints are tight, explore in-house GPU usage vs. third-party services and compare performance, latency, and storage requirements.
Conclusion
This system gives product teams a quick way to analyze images at scale. The approach uses CNN-based classification, CNN+LSTM for captions, YOLO for detection, and a Flask+Docker framework for deployment. If results show strong user engagement benefits, build a production pipeline that automates data retrieval, inference, and user feedback.
How would you handle potential follow-up questions?
Below are common follow-up questions a Senior Data Scientist candidate might face:
How do you ensure data quality before training?
Clean and filter the images, removing low-quality or irrelevant samples. Check for class imbalance and create synthetic examples (for instance, data augmentation) if certain labels have fewer samples. Ensure consistent resolution and color format so that the model receives uniform inputs. Track labeling accuracy to avoid noisy labels that can degrade model performance.
What optimization methods do you use to train your CNN?
Use stochastic gradient descent or adaptive methods like Adam. Start with a suitable learning rate. Use small batches (for example, 32 or 64) and schedule the learning rate to decay after a few epochs. Monitor training loss and validation loss to prevent overfitting. Early stopping helps if the validation loss stagnates or starts increasing.
How do you handle overfitting in your image classification models?
Add regularization approaches like dropout. Perform data augmentation by randomly flipping, rotating, or shifting images. Use a validation set for hyperparameter tuning. Implement early stopping when the validation performance declines. Sometimes reduce model complexity if you see a large gap between training and validation accuracy.
Why would you choose an in-house model deployment instead of using third-party APIs?
Maintain control over data privacy. Avoid sending user images to external vendors. Lower latency because inference is done locally rather than over external networks. Potentially lower costs at large scale because pay-per-use third-party solutions can get expensive. Easier to fine-tune or customize models for new features.
How do you integrate this service with a front-end application?
Give the front-end team your API endpoint. They only need to send HTTP requests with an image file or an image URL. The service responds with JSON containing model outputs. Keep the endpoint stable so that the front-end does not break when you upgrade your backend models.
How do you estimate the business value of this project?
Compare user engagement metrics, such as matches, likes, or time spent on the platform, for users who receive personalized suggestions vs. a control group that does not. Track improvements in conversion or retention. If the model identifies harmful or low-quality images, measure moderation efficiency gains or reduced user complaints.
How would you manage versioning and updates of your deployed models?
Version each new model release and log its performance metrics. Maintain a rollback strategy in case the new version underperforms. Label each Docker image by model version, such as cv_api:v2.0. Write release notes describing changes. Maintain consistent logs and monitoring so you can trace any issues back to specific versions.
How do you ensure the Flask API stays performant under high load?
Profile and optimize data preprocessing. Scale horizontally by running multiple containers, each with GPU support. Use a load balancer to distribute requests. Cache shared resources if needed. Monitor GPU utilization, memory usage, and request latency. Consider a dedicated inference service such as TensorFlow Serving or TorchServe if Flask overhead becomes significant.
How do you handle data drift and retraining?
Monitor incoming data distributions. If the user population changes or images differ from your original training set, your model may degrade. Re-collect labeled data that matches new patterns. Retrain or fine-tune the models periodically. Automate triggers for retraining if you detect significant performance changes.
These steps give a strong foundation for building and explaining a complex computer vision API service in an interview setting. The main goal is to show thorough end-to-end reasoning, from data preprocessing to final impact evaluation.