
ML Case-study Interview Question: GNNs and Attention for Real-Time Sequential E-commerce Recommendations


Browse all the ML Case-Studies here.
Case-Study question
A leading retailer wants a real-time recommendation system that automatically suggests items based on the most recent items added to an online shopping cart, rather than relying on static single-item recommendation lookups. They plan to create an AI solution that processes a guest’s ordered sequence of cart items as a session, and outputs new suggestions every time an item is added. How would you design, implement, and evaluate such a system if you were a Senior Data Scientist at a high-scale tech company?
Detailed Solution
Data Ingestion and Processing
Raw transaction data is extracted from a data warehouse to form ordered item sequences. Each sequence represents a single user's session. Data pipelines rely on Hive or Spark for cleaning and structuring these item sequences. The system ensures each session’s items are chronological, preserving the order in which guests added items.
Model Architecture
The model uses a combination of Graph Neural Networks (GNN) and attention layers. GNN layers capture the short-range transitions between items in a session. Attention layers handle the long-range dependencies and give higher weight to recent items.
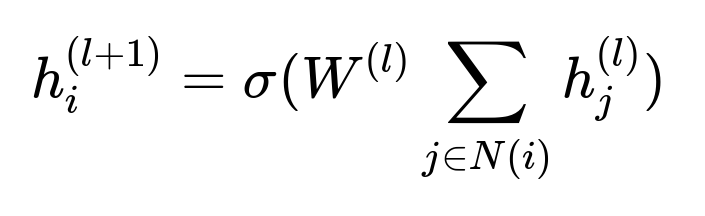
Where:
h_i^{(l)} is the embedding of node i in the l-th layer.
N(i) is the set of neighbor nodes of i in the graph (i.e., items that follow i in sessions).
W^{(l)} is a learned weight matrix for the l-th layer.
sigma is a nonlinear activation function.
Attention layers operate on a shortcut graph that includes edges linking earlier items to later items across the entire session, even if they are not adjacent. This approach ensures the model notes items that are far apart in the session timeline.
Gated Recurrent Unit (GRU) further refines item representations so that the final embeddings respect the temporal order of item additions.
Training
Sequences are split into training and validation sets. Negative sampling is introduced by pairing sessions with items not actually purchased, ensuring the model distinguishes relevant items from irrelevant ones. The system learns embeddings such that an item is closer in embedding space to sessions in which it co-occurs frequently.
Real-Time Inference
A Python-based microservice loads trained model weights. Whenever an item is added to the cart, the system updates the session embedding on the fly and computes the K nearest item embeddings. The top results become dynamic recommendations. This differs from the older approach that relied on precomputed lists for each item and could not combine multiple cart items in real time.
Metrics and Impact
Key metrics include click-through rate, conversion rate, and attributable demand (the overall revenue linked to recommendations). Gains in these metrics are measured through A/B tests where half the traffic receives the new model’s recommendations and half receives the baseline model.
Potential Follow-Up Questions
1) How do you handle the computational complexity of real-time inference for large catalogs?
In large catalogs with millions of items, naive nearest-neighbor searches can be slow. Approximate nearest neighbor (ANN) methods accelerate these searches. Libraries like Faiss or ScaNN can index embeddings. During inference, the system searches for items with minimal vector distance to the evolving session embedding.
The index is built offline and regularly refreshed with new embeddings. The microservice queries the index, returning top candidates in milliseconds. ANN indexes store item embeddings in memory, and the system uses distance metrics like cosine or dot-product similarity.
2) What steps ensure data quality and reliable session ordering?
Timestamps must be accurate to keep item order correct. Systems that aggregate transaction logs must handle late arrivals of events. Data quality checks confirm item codes are valid, product categories are labeled properly, and the user session is consistent. Spark or Hive logic filters out sessions with corrupted data. Strict ordering is then applied by sorting events by timestamp.
3) How does the GNN approach compare to simpler collaborative filtering methods?
Collaborative filtering (CF) typically operates on user-item interactions in a matrix form, often ignoring session sequence. GNN-based models incorporate adjacency relationships to capture how items transition in short order. Attention layers capture broader relationships across multiple items. This approach offers better context for sessions with multiple items, leading to more relevant suggestions.
CF can be faster to implement but might fail to adapt to rapidly evolving sessions, because CF’s computations are often done offline and do not account for recency as effectively.
4) How do you address cold-start items or categories?
For new items, the system relies on textual or categorical metadata embeddings. If a new item has minimal historical data, the model can fuse item description embeddings with known item embeddings. Category-level generalizations help bootstrap new items into the embedding space. Over time, more session data for that item refines its representation.
5) How do you ensure the model does not overfit on a few popular items?
Regularization techniques in model training control overfitting. Dropout in attention layers, weight decay in GNN parameters, and sampling less frequent items more often in the training process help distribute representation power more evenly. A diverse recommendation set is checked by tracking popularity metrics. If the top 10 suggestions are dominated by only high-selling items, hyperparameters or training sets are rebalanced.
6) How would you scale this approach to billions of sessions?
Distributed training is done on large clusters with frameworks like Spark, TensorFlow, or PyTorch. Embedding lookups and GNN computations split across multiple GPUs. The final model artifacts are saved to a distributed file system and served by containerized microservices behind a load balancer. Caching session embeddings for active users reduces repeated computations during high-traffic periods.
7) How would you tune hyperparameters for this model?
Grid or random search strategies test different learning rates, batch sizes, embedding dimensions, and attention heads. Automated methods like Bayesian optimization (e.g., using Hyperopt) reduce the manual workload. Offline validation metrics (precision at K, recall at K) guide candidate configurations. Promising settings are tested in small-scale A/B pilots before rolling out widely.
8) How can you improve categories where the model underperforms?
Retraining with more granular session data and rechecking those items for potential labeling or metadata issues is essential. Sometimes user behavior in certain categories differs from mainstream patterns. Creating specialized category modules or domain-specific embeddings can improve performance. Further training might incorporate user interactions such as search queries or reviews to enrich item vectors for niche categories.
9) How do you handle evolving customer behavior over time?
Online learning or periodic retraining ensures the model adapts to shifting purchase patterns. Instead of a static model, incremental updates incorporate recent sessions and store them in an event queue. The system retrains embeddings weekly or monthly. If real-time learning is required, streaming frameworks like Apache Kafka feed fresh data into incremental GNN updates, ensuring the model remains current.