
ML Case-study Interview Question: Clustering Linked Fraudulent Accounts at Scale Using GBDT Similarity Scoring.


Browse all the ML Case-Studies here.
Case-Study question
A large-scale payment platform faces persistent challenges from malicious actors who create fraudulent merchant accounts. They try to mask their identities by fabricating data or reusing compromised resources, hoping to process stolen credit cards or scam customers before detection. The platform has a massive user base and needs to automatically identify and cluster suspicious accounts to shut them down quickly. How would you design, implement, and iterate on a fraud-detection system that identifies linked fraudulent accounts at scale based on similarity in account attributes, bank data, IP addresses, or other subtle signals?
Detailed solution
Overview of the core problem
Teams need to block malicious merchant accounts to minimize fraudulent transactions and chargebacks. Fraudsters create accounts using either stolen identities or fake details. They often reuse the same or partially similar attributes across multiple accounts. This similarity can be exploited to cluster such accounts and take bulk actions.
Supervised approach to similarity
A supervised model for similarity learning becomes feasible when large amounts of labeled data are available. Each pair of accounts can be labeled “same cluster” or “different cluster.” Training data arises naturally from known groups of fraudulent accounts discovered through investigations. This data helps the model learn which shared attributes most strongly indicate that two accounts belong to the same fraud ring.
Feature engineering for account pairs
Creating pairwise features involves extracting signals such as overlapping email domains, identical or related personal data, reusage of the same bank or card numbers, or suspicious text similarities. More advanced signals include partial string matches in addresses and device fingerprint overlaps.
Model choice: Gradient-Boosted Decision Trees (GBDTs)
Gradient-boosted decision trees handle diverse tabular features well. They interpret continuous and categorical data efficiently and maintain strong performance even when signals vary widely in magnitude or type. One standard approach uses an XGBoost model trained on known positives (pairs of accounts from the same fraudulent group) and negatives (pairs from different groups).
Key formula for iterative boosting
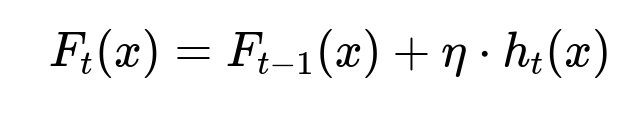
Where F_{t}(x) is the model at iteration t, F_{t-1}(x) is the previous iteration’s model, eta is the learning rate, and h_{t}(x) is the new weak learner added at iteration t.
This iterative method fits a new weak learner on the pseudo-residuals of the loss function at each stage. Summing these learners yields a robust predictor of the pairwise similarity score.
Implementation pipeline
The pipeline receives newly created merchant accounts and forms candidate edges between them and existing accounts that share certain attributes. The model scores each edge with a similarity probability. Edges exceeding a threshold become links in a graph. Connected components in this graph represent clusters of accounts deemed highly similar. Analysts or downstream automated systems can review or block these clusters.
Example Python snippet
import xgboost as xgb
import pandas as pd
# pairs_df has columns: [feature1, feature2, ..., label]
data = pd.read_csv("training_pairs.csv")
X = data.drop("label", axis=1)
y = data["label"]
dtrain = xgb.DMatrix(X, label=y)
params = {
"objective": "binary:logistic",
"max_depth": 6,
"eta": 0.1,
"eval_metric": "auc"
}
model = xgb.train(params, dtrain, num_boost_round=100)
# model can now be used to score pairwise edges
This model then serves in production to generate similarity scores in real time.
Adaptive retraining
Retraining the model periodically incorporates the newest fraud patterns. Feedback loops from blocked accounts refine the labels (same cluster vs. different cluster). The system evolves with changes in fraudster behavior.
Practical considerations
Regular system audits ensure that the clustering logic does not overreach and falsely group legitimate users. Thresholds for linking accounts must be tuned to minimize false positives. Risk analysts need transparent tools that show exactly which attributes prompted the system to cluster accounts together.
Possible follow-up questions
How do you handle scalability when there are billions of potential account pairs?
A large-scale pipeline cannot compute or score all possible pairs. Filtering reduces candidate edges. The system first checks if accounts share at least one suspicious attribute or partial overlap (e.g., same bank details, same device fingerprint). Only those pairs proceed to the GBDT similarity scoring step. Graph-based data structures then manage connected components efficiently. Systems like Spark or distributed frameworks partition these computations. Hardware acceleration and cluster computing platforms optimize performance further.
How do you choose threshold scores for linking accounts in the cluster graph?
A separate validation set with known fraudulent clusters guides threshold selection. Pick thresholds that maximize precision and recall balance. Evaluate how different cutoffs affect the true-positive rate of linking accounts in the same fraud ring vs. false positives. Calibrate the threshold to maintain low false positives. Fine-tune it based on business tolerance for missed fraud vs. false blocks. Analytical methods like precision-recall curves or cost-based analyses help finalize the chosen threshold.
What if a fraud ring uses randomized attribute data to avoid detection?
Fraudsters rarely randomize everything perfectly. Some signals like bank accounts are harder to randomize. Device fingerprints or IP addresses often reappear. Sophisticated text similarity features or partial matches pick up subtle connections. The model continues to learn from these real-world patterns because the supervised training set updates as soon as new fraud rings are flagged. Shifting to more robust or new data sources (e.g., cross-referencing external identity providers) can bolster resilience.
How do you evaluate model performance beyond standard metrics?
Analysis includes how often the system successfully identifies entire fraud rings with minimal misses. Review the size of each detected cluster and whether subsequent follow-up reveals more fraudulent activity. Track cost savings in chargebacks avoided and reduced analyst workload. Evaluate the system’s long-term impact on fraudster behavior, such as forcing them to invest in more costly resources that eventually become impractical.
How would you detect emerging fraud patterns that are not yet in historical data?
Monitor out-of-distribution signals or anomaly detection systems that flag new, unseen account behaviors. Expand features to capture new signals. Incorporate active learning loops to quickly retrain on fresh examples. Employ analysts to review suspicious but unexplained accounts and label them promptly. Hybrid approaches with unsupervised clustering can discover novel patterns that do not yet appear in labeled data.
What techniques prevent the system from incorrectly banning legitimate businesses?
Human review can intervene before final account takedowns. The model’s decisions require interpretability so analysts understand why two accounts are linked. Set thresholds conservatively. Gradually tighten them if there is strong evidence of malicious activity. Separate risk segments or traffic types (e.g., new industries or geographies) where the model’s confidence might differ. Track false positives regularly and adjust the system accordingly.