
ML Case-study Interview Question: Improving Marketplace Recommendations with Neural Embeddings and Real-Time Behavior


Browse all the ML Case-Studies here.
Case-Study question
A large marketplace platform faced challenges with its recommendation system. Users encountered irrelevant or outdated product suggestions, reducing conversions. The platform tested a new approach that used a combination of neural-network-based embeddings and real-time user behavioral signals to generate product recommendations. The goal was to improve the overall click-through rate and reduce bounce rate. You are asked to propose a complete solution plan, describe the needed data pipelines, outline the model architecture, detail the deployment strategy, and anticipate potential pitfalls.
Proposed Solution
A neural network model captured product and user behavioral embeddings. The system used sequence data from user actions. A real-time layer updated user embeddings whenever a user clicked, searched, or purchased. Historical features came from aggregated user events over various time windows. The final ranking combined scores from the model with business rules.
Architecture and Data Flow
A streaming system logged each user event and fed it into a real-time transformation module. The module updated the user embeddings in a low-latency key-value store. A scheduled batch process refreshed product embeddings using a neural network trained on aggregated events. A separate job generated historical features for each user. A single inference pipeline merged real-time user embeddings with batch features and produced final recommendations.
Key Mathematical Model
The main scoring function used a neural network architecture with a softmax output for product recommendations. For classification-based scoring, the probability of a user clicking on product p given user u was:
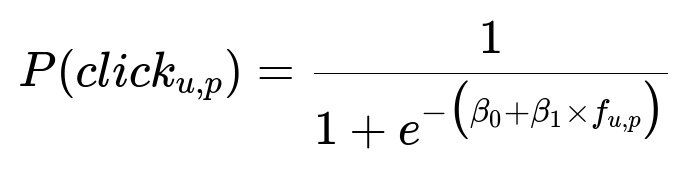
f_{u,p} is a learned representation of user u and product p based on embedding vectors. beta_0 and beta_1 are learned parameters. f_{u,p} was computed from neural layers that processed user and product embeddings. The model was trained with historical click data.
Code Snippet (Python)
import torch
import torch.nn as nn
import torch.optim as optim
class SimpleRecModel(nn.Module):
def __init__(self, user_dim, product_dim, hidden_dim):
super(SimpleRecModel, self).__init__()
self.layer1 = nn.Linear(user_dim + product_dim, hidden_dim)
self.layer2 = nn.Linear(hidden_dim, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, user_vec, product_vec):
x = torch.cat((user_vec, product_vec), dim=1)
x = self.layer1(x)
x = torch.relu(x)
x = self.layer2(x)
return self.sigmoid(x)
user_dim = 64
product_dim = 64
hidden_dim = 128
model = SimpleRecModel(user_dim, product_dim, hidden_dim)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Example training step
for epoch in range(10):
# user_batch and product_batch are hypothetical tensors
# labels are 0 or 1 for click or no-click
optimizer.zero_grad()
predictions = model(user_batch, product_batch)
loss = criterion(predictions, labels)
loss.backward()
optimizer.step()
This model combined user embeddings and product embeddings. The forward pass concatenated them. The hidden layer used ReLU activation. The final layer applied a sigmoid function. The training loop used binary cross-entropy loss.
Explanation of Training Process
The training dataset consisted of user events labeled with click or no-click. The batch training system sampled these events. The optimizer updated the neural network weights to minimize the binary cross-entropy loss. The final model learned to output a probability of a click. Once trained, a service loaded the model weights and performed real-time inference.
Deployment Strategy
A container-based microservice served the model. A high-throughput feature store kept user embeddings updated. The inference pipeline fetched user embeddings and product embeddings. It combined them in the model for final scoring. The result was a top-K product ranking.
Monitoring and Iteration
A separate metrics collector recorded click-through rate, bounce rate, and revenue per user segment. The pipeline periodically retrained the model to capture evolving user behavior and new products. The system used canary releases to test updated models.
Follow-up Question 1
How would you handle cold-start users with minimal activity?
Explanation
Cold-start users have limited historical data. A fallback strategy is mandatory. A popular-items model can suggest top-selling products. Another approach can rely on cluster-level embeddings from demographically similar users. User embedding updates become more personalized once real actions from that user are available.
Follow-up Question 2
What strategies maintain low-latency recommendations?
Explanation
A real-time data pipeline buffers user events. A fast key-value store retrieves embeddings. Model inference occurs in a low-latency service layer, possibly with GPU acceleration. Batching inference requests can reduce overhead. Fine-tuning the concurrency configurations and employing asynchronous I/O helps the system scale.
Follow-up Question 3
How do you ensure the model remains stable with a constant influx of new items?
Explanation
A batch job updates product embeddings at regular intervals. A real-time indexing module can place new items in a provisional bucket with default or approximate embeddings. The model sees these items in ongoing training data. A partial retraining step or incremental learning accommodates newly introduced products.
Follow-up Question 4
How would you address potential model drift?
Explanation
A model can drift when user interests shift. A schedule can retrain the model on recent data. A system for backtesting and monitoring distribution changes triggers retraining or hyperparameter tuning. A shadow evaluation environment can measure performance on new data before production deployment.
Follow-up Question 5
How do you approach hyperparameter tuning for the neural network?
Explanation
A systematic search over hidden layer sizes, learning rates, and regularization parameters is effective. A random search or Bayesian optimization approach can reduce search times. A hold-out validation set checks performance metrics like AUC or precision at top-K. Early stopping rules help avoid overfitting.
Follow-up Question 6
How do you mitigate the risk of over-recommending popular items to all users?
Explanation
The model can learn subtle user-product signals if embeddings capture unique user histories. A popularity bias can be balanced by an exploration mechanism. Diversifying final recommendations with a ranking re-order step can help. A penalty term on frequently shown items encourages more coverage across the product space.
Follow-up Question 7
How would you adapt this system for a mobile-first user base with limited network bandwidth?
Explanation
Client-side caching of basic recommendations saves bandwidth. A lightweight on-device model can rank a small candidate list when network connectivity is weak. A server can push minimal updates to embeddings. In offline or low-connectivity scenarios, the user sees cached results until a fresh ranking is fetched.