
ML Case-study Interview Question: Scalable Personalized Recommendations: Building Real-Time Machine Learning Pipelines


Browse all the ML Case-Studies here.
Case-Study question
You are working at a large consumer-facing platform that experiences massive traffic. The company wants to build an advanced recommendation system to improve user engagement and revenue. They have extensive user-behavior data, browsing patterns, and transaction logs. They also have a real-time serving infrastructure that can handle large-scale requests. How would you, as a Senior Data Scientist, design and implement a scalable machine learning pipeline to deliver personalized recommendations? How would you ensure model reliability, robustness, and real-time performance at scale? Propose end-to-end solutions, including data ingestion, feature engineering, model training, model deployment, online inference, and experimentation. Justify your choices of algorithms, architectures, and infrastructure resources. Explain how you would measure success through both offline and online metrics. Address potential challenges such as cold-start users, data drift, bias detection, and system latency.
Proposed Detailed Solution
Building a personalized recommendation system at scale involves multiple layers of data processing, modeling, and deployment. The goal is to capture the context of individual users and predict the most relevant items in real time. The solution involves the following main stages.
Data Collection and Ingestion
Aggregate user interactions (page visits, searches, clicks), user demographics, and item metadata into a unified data warehouse. Store them in a distributed file system with partitioning strategies based on time and user segments. Pull daily or hourly snapshots to keep features fresh.
Feature Engineering
Generate features that capture temporal behaviors. Merge historical interactions (total clicks, purchase counts) with real-time context (session duration, immediate clickstream). Implement embedding techniques for item and user representations to capture latent relationships. Summarize item popularity with rolling windows to track time-sensitive trends.
Model Architecture
A deep neural network approach can learn complex nonlinear interactions between user features and item representations. A simpler logistic regression model can be a good baseline. A combined approach can be used for final deployment.
Below is a core formula for logistic regression prediction probability for user i:
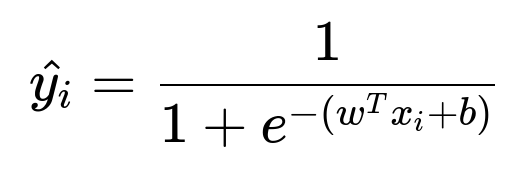
In this formula, w is the weight vector. x_i is the feature vector for user i, including user features and item features. b is the bias term. The output is the probability that the user will engage (click or purchase) when shown the item.
Training Workflow
Split data into training, validation, and testing sets. Perform hyperparameter tuning on the validation set. Use parallelized distributed training to accommodate large-scale data. Apply cross-validation to reduce overfitting. Use regularization methods (L2 penalty or dropout in deep nets).
Model Evaluation
Evaluate offline with AUC and precision-at-k metrics for ranking-based tasks. Measure log loss or cross-entropy if the model outputs probabilities. A higher AUC or precision-at-k indicates better ranking performance. Evaluate the distribution of model errors across various user segments to detect bias.
Model Deployment
Export the model to a serving-friendly format. Containerize and deploy it in a low-latency microservice. Optimize inference speed through hardware acceleration or caching. Update the model at regular intervals to incorporate recent trends.
Real-Time Inference
Expose a REST API or gRPC endpoint. Accept user ID, session context, or item ID. Generate real-time features (session length, current click patterns) on the fly. Retrieve user embeddings from a store. Run the model to score candidate items. Return the top-ranked items to the user interface.
Monitoring and Experimentation
Use A/B testing to measure the recommendation system’s impact on key metrics (click-through rate, user retention, revenue). Assign a fraction of traffic to the new model variant. Compare performance with a control group. Collect real-time logs of system latency, error rates, and user feedback. Monitor data drift. Retrain or recalibrate the model when performance drops below thresholds.
Example Python Snippet
import numpy as np
from sklearn.linear_model import LogisticRegression
# Dummy training data
X_train = np.array([[0.2, 1.5, 3.2],
[1.0, 2.0, 0.5],
[0.7, 1.1, 2.1],
[3.1, 0.1, 4.8]])
y_train = np.array([0, 1, 1, 0])
model = LogisticRegression()
model.fit(X_train, y_train)
# Prediction on new user-item feature vector
X_test = np.array([[0.6, 1.0, 2.5]])
prediction_prob = model.predict_proba(X_test)
print(prediction_prob)
This code trains a logistic regression on a toy dataset. In production, you would replace these placeholders with your large-scale feature vectors. Batch training would run on distributed frameworks, and the final model would be deployed behind a serving layer.
Handling Cold-Start Users
Capture items that do not rely on explicit user histories, such as top trending items overall or items popular among similar demographics. Gradually update user profiles as data accumulates.
Ensuring Robustness
Implement offline checks for each training run, including distributional checks on incoming data. Perform canary releases to guard against regressions. Alert on significant drifts or anomalies.
Achieving Low Latency
Build efficient retrieval of user embeddings. Minimize data lookups by pre-computing frequently requested features. Cache partial results and parallelize the scoring of candidate items if needed.
The solution is scalable, handles real-time interactions, and can be regularly iterated upon as new signals emerge.
Follow-Up Questions and Answers
1) How would you approach hyperparameter tuning and model selection?
Hyperparameter tuning includes grid-search or random-search. For large data, Bayesian optimization can reduce search rounds. In a streaming context, you can employ online learning methods to adapt hyperparameters incrementally. Split the data into training/validation segments. Compare performance on metrics like AUC or precision-at-k. Pick the best configuration, then confirm on a hold-out test set.
2) How do you address data drift over time?
Monitor incoming data distributions. Compare recent feature statistics with historical baselines. Track changes in user behavior or item popularity. If you see shifts, retrain or re-calibrate models. You may adapt thresholds for classification tasks or refresh item embeddings. Use a rolling training window that captures the latest user interactions.
3) How do you mitigate bias in recommendations?
Study performance across demographic segments. Investigate if the model unfairly amplifies certain types of items or user groups. Introduce constraints or reweight training examples to ensure balanced outcomes. Evaluate fairness metrics that check whether recommended items are equitably served. Consider business rules to limit harmful biases in item exposure.
4) How do you handle a spike in traffic while maintaining low latency?
Set up auto-scaling policies that spin up additional inference resources under high load. Cache results for repeated user requests. Optimize your model size or use quantization/pruning to reduce computational cost. Use approximate nearest-neighbor search for rapid item retrieval if your recommendation approach involves large item embeddings.
5) How would you validate the model online and measure success?
Use A/B testing. Split traffic between the current model (control) and the new model (treatment). Define key performance indicators like click-through rate and revenue per session. Compare results across a meaningful user base. Keep experiments running until results stabilize. Watch for potential confounders like seasonality or external events. Confirm that improvements are statistically significant before full rollout.
6) Could you explain how you would incorporate deep learning?
Use user embeddings, item embeddings, and context features as input to a multi-layer network. Dense layers capture interactions. The final output layer estimates the probability of a desired action. You can integrate attention mechanisms for session-based context. Train end-to-end in a distributed environment. This can significantly boost personalization if you have enough data.
7) How do you prevent overfitting in deep learning models with so much data?
Employ regularization methods like dropout in each hidden layer. Use batch normalization. Keep track of validation performance at each epoch. Stop early if performance degrades. Use large-scale data augmentation if appropriate. If the architecture is extremely large, ensure it aligns with the volume of data. Validate with multiple random seeds to check generalization stability.
8) Why might you still keep a simpler baseline model?
A baseline is a sanity check. A simple model like logistic regression is explainable and can highlight issues in your data pipelines. It is also fast to train and serves as a fallback when advanced models fail in production due to corner cases. This ensures you have a reliable reference for measuring progress.
These ideas mirror the end-to-end pipeline needed for a real-world, high-traffic recommendation system. The combination of robust data pipelines, flexible model architectures, and careful experimentation ensures reliable and impactful recommendations in production.