
ML Case-study Interview Question: Scaling Travel Support with Generative Text: Recommendations & Real-Time Assistance


Case-Study question
You are working at a large online travel marketplace that connects property owners with travelers. The customer support team receives millions of requests each year. They want to reduce response times and improve quality for both guests and hosts. You have been asked to propose, architect, and implement text generation Machine Learning solutions to accomplish these goals. You are given three key areas of focus: (1) recommending relevant help articles and FAQs, (2) providing real-time message guidance for human agents, and (3) paraphrasing user queries to boost chatbot engagement. How would you design and deploy these solutions to handle large-scale customer support, reduce labeling costs, handle long-tail corner cases, and improve user satisfaction?
Detailed Solution
Text generation models are powerful for industrial-scale customer support. They encode domain knowledge through large-scale pre-training, handle tasks in an unsupervised or weakly supervised manner, and unify different tasks under a single generative framework. This yields higher relevance in recommendations, efficient real-time assistance, and better user engagement. Below is a step-by-step strategy.
Encoding Domain Knowledge
Train large transformer-based language models using past conversation data between agents and users. This creates a robust model that captures the subtle nuances of customer issues. The model learns to output relevant text directly instead of relying on brittle classification heads.
In generative language modeling, we often estimate the conditional probability of output tokens y given input tokens x. A simplified form of the generation objective is:
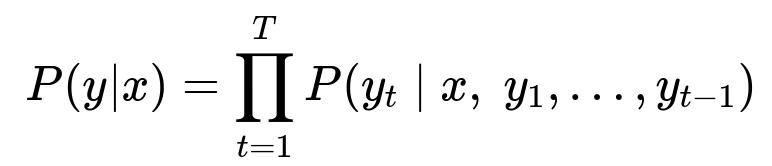
Here, x represents the input text (like a user request), and y is the generated text (for example, a recommendation or paraphrased answer). T is the length of the output text. This factorization means each generated token depends on the entire input plus all previously generated tokens.
Content Recommendation
Convert the ranking problem into a generative classification task. The model sees user issue text plus candidate content text, prepended by a prompt (like: “Is this document helpful? Answer Yes or No.”). It then outputs “Yes” or “No.” This approach avoids explicit labeled classification data for each document. You fine-tune on pairs of issue descriptions and help articles from historical logs, focusing on whether the user ultimately found that article helpful. This generative method captures more subtle semantic connections and outperforms pure discriminative classification.
Real-Time Agent Assistance
Provide agents with immediate insights in a chat interface. Use a generative Question-Answering (QA) model that checks the conversation text for clues about user intent. The system forms a prompt such as: “Is this user asking to cancel because of a medical emergency?” If the answer is “Yes,” the model then suggests relevant action templates. This QA approach is based on a single generative model that can answer many domain-specific questions, reducing the need to maintain multiple specialized classifiers.
Chatbot Paraphrasing
Users often test a bot’s intelligence before investing time. Generate a paraphrased restatement of their question. This builds user trust. You train a paraphrase model on agent-user chat transcripts. You extract segments where human agents rephrase a user’s question with patterns like “I understand that you….” By filtering out overly generic agent replies, you ensure the paraphrases capture specific details. T5-like encoder-decoder models often excel here. Removing training examples that are too vague significantly boosts your model’s ability to produce specific restatements.
Practical Implementation
Use a multi-GPU training framework such as DeepSpeed or distributed PyTorch. This lets you handle large generative models (like T5-XXL). Combine annotated data (high precision) and unlabeled or lightly labeled conversation data (broad coverage) to achieve best results. Tune hyperparameters with smaller data first to reduce training cycles. Then train on large corpora. Evaluate on real user flows in an A/B test to confirm improvements in metrics like click-through rate on help articles, user satisfaction surveys, or agent handle time.
Code Snippet (Conceptual T5 Example)
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
model_name = "t5-base"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
input_text = "prompt: Is this user asking for a cancellation? context: User message about missing flight."
input_ids = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(input_ids, max_length=10, num_beams=3, early_stopping=True)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)
This snippet demonstrates how to pass prompts with context into T5 and generate short answers (for classification or QA). In practice, you would fine-tune the model on carefully prepared domain-specific data.
Possible Follow-Up Questions
How do you handle hallucinations or incorrect text generation?
Text generation models may invent answers or produce irrelevant content. Minimize this risk by limiting the model’s scope, adding strict prompts, and incorporating domain constraints. For instance, you can run a lightweight validation layer after generation to ensure the final output complies with policies or references real data. Another option is to fine-tune on curated data that penalizes wrong statements. If the model must stick to factual references, retrieve relevant knowledge documents first, append them as context, and prompt the model to cite them. Any final output that contradicts known data is discarded or corrected.
How do you reduce the risk of generic, unhelpful replies in paraphrasing?
Filter out bland agent responses from the training set. Clustering or similarity-based methods can locate repeated, generic statements like “I understand you have an issue.” Remove those clusters. Also penalize the model when it generates low-information text. For example, you can train a secondary model or add a reranker to score outputs by specificity. If the paraphrase lacks details, you choose a more precise alternative.
Could you integrate few-shot prompting to avoid costly large-scale labeling?
Yes. You can prime the model with a few labeled examples in the prompt to guide the format of the output. This approach is especially useful for new tasks. You write a handful of demonstrations and let the large language model generalize. This lowers reliance on big labeled datasets. But for core tasks, you usually fine-tune using both unlabeled and smaller labeled sets to ensure stable performance across all corner cases.
How would you scale these systems for millions of daily user queries?
You deploy model inference in a cluster of GPU instances or in more optimized hardware like TPUs. Use techniques like model distillation or quantization to reduce latency and memory usage. You also adopt caching and partial offline computation for ranking tasks. For real-time tasks, you bucket high-frequency queries or batch them carefully. You monitor key metrics like response time, GPU utilization, or throughput, then expand capacity as needed.
How do you address data privacy and secure sensitive user information?
You anonymize user data before training. Any personal identifiers or payment data is removed or obfuscated. Production inferences must comply with internal policies that block the model from logging or exposing sensitive information. You also design the generative model’s prompts to limit personal data usage. A robust privacy review process ensures the system aligns with legal regulations.
How do you ensure maintenance over time?
Generative models drift if they see new language patterns or policy changes. You periodically retrain them on updated conversation logs. You monitor the quality metrics in real time. When you see performance degrade on certain issues, you collect samples and feed them back into the training pipeline. You also test regularly with synthetic edge cases to confirm that changes do not break older functionality.
How would you measure ROI in an A/B test?
Set up experiments in user-facing flows. For content recommendation, measure the click-through rate or how often the user does not escalate to a human agent. For real-time agent assistance, measure handle time or net promoter score. For chatbots, measure user engagement, containment rate (when the bot resolves the issue without human intervention), and post-conversation feedback. Compare these metrics between treatment (generative model) and control (existing baseline).
This completes the case-study question and its comprehensive solution.