
ML Case-study Interview Question: AI-Driven Ensemble Modeling Tackles Hidden Retail Stockouts for Accurate Inventory


Browse all the ML Case-Studies here.
Case-Study question
A major brick-and-mortar retailer faces large-scale unknown out-of-stock issues in its stores. Standard inventory systems frequently assume certain items are still on hand when they are not, causing missed sales because replenishment never triggers. The retailer has millions of products across thousands of locations, experiences significant data flow, and must handle inconsistent inventory signals coming from various sources (sales data, in-store movements, supply chain records, potential sensor or camera inputs). Design an AI-driven solution that automatically detects these hidden out-of-stocks and corrects the on-hand counts, thus triggering replenishment. Propose a robust end-to-end strategy that handles data ingestion, anomaly detection, ensemble modeling, measurement, and final reconciliation in the inventory ledger.
Explain how you would validate the solution, monitor it in production, handle seasonal or category-specific variations, and avoid degrading inventory accuracy further. Provide details on potential system architecture, data pipelines, and model ensemble approaches.
Detailed Solution
Overview of the Approach
Large retailers maintain complex supply chains and store systems. The primary obstacle involves identifying inventory inaccuracies when the system believes there is remaining quantity, but physical audits reveal zero stock. An AI-based solution can infer these hidden out-of-stocks by analyzing transaction data, sales patterns, and in-store movements. The approach involves building specialized models for each product category and then combining them in an ensemble.
Data Collection and Preparation
Teams aggregate transaction logs, sales data, replenishment records, store movements, and any sensor inputs into a unified data store. The system must track historical records for every product in every location, including intermediate states, because changes in on-hand quantity happen frequently and in large volumes. Domain knowledge helps sanitize data where holiday, seasonal, or promotion-driven effects can skew normal patterns.
Ensemble Modeling
Models focus on detecting patterns that suggest out-of-stocks are missed by the system. Some models specialize in specific categories (e.g., fresh foods, sporting goods), and others specialize in process signatures (e.g., items with high theft probability). Each model outputs a probability that an item is actually at zero stock despite the system’s on-hand quantity.
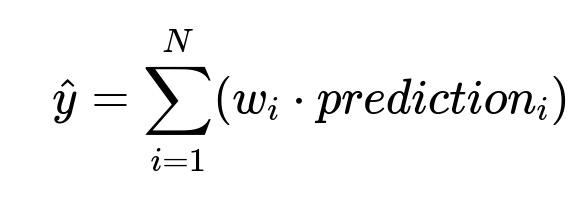
Where:
N is the number of specialized models in the ensemble.
w_{i} is a learned weight for each model i.
prediction_{i} is the out-of-stock probability according to model i.
If the combined probability crosses a threshold, the system infers that the on-hand quantity is likely inaccurate. The on-hand quantity is then adjusted to zero in the inventory ledger.
Inventory Ledger Integration
Once an ensemble model flags a product as out-of-stock, an adjustment event is pushed to the ledger. The ledger updates the item’s count to zero and triggers replenishment. This correction occurs once per item-store combination in a day to avoid unnecessary repeated changes before new stock arrives. The ledger logs every transaction with context, making it easy to reconstruct how the final on-hand count was reached.
Measurement and Arbitration
Multiple signal types (camera, weight sensors, or pure data models) might propose different corrections. An arbitration engine selects the correction with the highest confidence and finalizes it. An independent monitoring team measures the accuracy of these corrections. Measurement includes random sampling audits in stores and comparing “before” vs. “after” results on sales lift.
Practical Implementation Details
A central data pipeline orchestrates daily batch flows, taking the previous day’s ledger updates plus any current-day transactions. Machine learning jobs run with distributed systems that handle large volumes of training data. The solution might involve a specialized store team app for manual verification during the early stages. As confidence grows, automatic corrections reduce dependence on manual checks.
Example Code Snippet
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
# Suppose df_train has 'features' and 'label' columns
X_train = df_train[features]
y_train = df_train['label']
model = GradientBoostingClassifier(n_estimators=100, max_depth=5)
model.fit(X_train, y_train)
# Predict daily for each item-store pair
pred_probs = model.predict_proba(df_daily[features])[:, 1]
df_daily['pred_out_of_stock'] = pred_probs
df_daily['adjust_flag'] = (df_daily['pred_out_of_stock'] > threshold)
This code shows daily predictions for a single model. Real systems orchestrate many domain-specific models, combine results, then commit adjustments to the ledger.
Follow-Up Question 1
How would you handle big surges in data volume during holiday seasons without losing accuracy or slowing system performance?
Answer and Explanation Systems must be designed to process large transaction spikes. Event-driven microservices can scale horizontally to handle additional load. Databases such as Mongo or RocksDB must be sharded carefully. Implement fine-grained partitioning across store and product IDs to distribute load. Add ephemeral worker nodes during peaks to train or infer on incremental batches. Pre-train models on historical holiday data to avoid dropping accuracy when sales patterns differ.
Follow-Up Question 2
What if certain product categories exhibit extremely erratic demand, making them tough for the model to learn patterns?
Answer and Explanation Segment these categories and develop specialized models that only focus on the identified erratic patterns. Incorporate domain-specific features like temperature (for seasonal items) or local events (for sporting goods). If data remains too noisy for a purely predictive approach, use short-interval manual audits for those categories to supply extra ground-truth to the model. Consider increasing the threshold for automated intervention in those categories to avoid frequent incorrect adjustments.
Follow-Up Question 3
How do you ensure that automatic adjustments do not over-correct, incorrectly setting on-hand counts to zero and triggering needless replenishments?
Answer and Explanation Track precision-recall metrics closely for each model or signal. Use a data-driven method to tune the threshold that triggers zeroing out. If precision drops below a certain threshold, revert to partial manual checks. The arbitration engine ensures that only high-confidence corrections proceed. The ledger logs all adjustments so that any suspicious spike in automated zero adjustments triggers alerts. Store teams can override mistakes directly in the ledger if evidence proves them wrong.
Follow-Up Question 4
How do you validate that these ML-driven corrections actually translate to higher sales and guest satisfaction?
Answer and Explanation Compare matched control vs. treatment groups. Treatment stores receive daily automatic corrections, while control stores continue with standard processes. Track increases in sales or unit movement in the treatment group. If stockouts decrease and corresponding sales increase, the solution is validated. In-store audits or third-party inventory checks confirm that the recommended corrections align with physical stock. Track guest feedback metrics and re-purchase rates for further evidence.
Follow-Up Question 5
Why use an ensemble of specialized models instead of a single large model for everything?
Answer and Explanation A single monolithic model often underperforms when the data spans many domains with unique selling patterns. Ensembles allow each model to specialize in a narrower scope, achieving higher precision. Some models detect anomalies in beauty products, while others focus on seasonal sporting goods or high-shrink items. The ensemble approach then integrates these partial confidences to produce a single numeric result with higher overall accuracy.
Follow-Up Question 6
What would you do if upstream sensor or transaction feeds contain duplicates or misordered events?
Answer and Explanation An event-driven pipeline must handle out-of-order data. The ledger uses logical timestamps or sequence IDs to reorder events and detect duplicates. Each transaction is validated against recent states to see if it contradicts prior updates. If a duplicate is detected, the ledger discards it. If an event arrives out of sequence, the system replays events to ensure the final state is correct. This design prevents inflating or deflating on-hand counts.
Follow-Up Question 7
How do you maintain unbiased measurement of the solution’s performance?
Answer and Explanation Keep measurement responsibilities with a separate team that reviews inventory accuracy and sales outcomes. They frequently sample random products in random stores, physically verifying out-of-stock conditions vs. system records. This unbiased measurement group publishes weekly or monthly reports, ensuring no single modeling team can influence or filter negative results. The measurements drive thresholds for model refinement or re-training.