
ML Case-study Interview Question: AI Product Strategy Co-Pilot: LLMs, Vector Search, and Structured Idea Generation.


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a major technology firm. You have been tasked with building an AI co-pilot for product strategy and concept ideation. It must enable scenario building, generate structured ideas, handle real-time user interactions, embed external search data, support iterative feedback, and provide short-term memory to handle large contexts. It should return responses in structured formats (for example JSON), integrate with vector-based retrieval for external content, and show streaming progress in the interface. Describe how you would design this system’s architecture, outline the prompting strategies, explain how you would implement the real-time interaction and short-term memory, and propose a plan for measuring success at scale.
Proposed Detailed Solution
Overall Architecture
Use a web-based interface connected to a backend that orchestrates prompts to a Large-Language Model (LLM) via an API such as OpenAI’s GPT. Wrap those prompts with a library that supports chaining, for example LangChain. Maintain multiple tasks, each with a dedicated prompt template. Implement short-term memory using a vector database to store embeddings of user-selected content.
Templated Prompt
Create fixed text templates. Pass user input alongside additional contextual strings. Ask the LLM to adopt a specific persona. For example, to generate scenarios, instruct it to act as a futurist, set time horizons, and vary the optimism levels. Keep templates short, and define multiple templates if you need distinct logic per user action.
Structured Response
Instruct the LLM to return strictly formatted data, typically JSON. Show an example schema in the prompt. For deeper nesting, outline the structure with sample objects. Large responses remain parseable if you require the LLM to follow your schema precisely.
Real-Time Progress
Stream response tokens back to the interface. Use an asynchronous callback approach, for instance with OpenAI’s streaming parameter. Render partial text so users do not wait on a single long final answer. Add a stop button for immediate cancellation.
Select and Carry Context
Implement a front-end mechanism for selecting ideas. Pass that selection to subsequent prompts by injecting text of the chosen idea or scenario. Persist multiple ideas in short-term memory. Retrieve them on demand. Pass them back to the LLM in new prompts if the context is still short enough. Otherwise use embeddings to fetch relevant chunks.
Contextual Conversation
Enable a direct chat window but prefill it with relevant context. Let users refine ideas or ask clarifications. Place prior relevant text in the prompt. If context grows large, rely on vector-based retrieval. Send the user’s query as an embedding. Retrieve matching documents or conversation segments from the store. Include them in the next LLM request.
Out-Loud Thinking
Use chain-of-thought style prompting. Tell the LLM to first generate intermediate reasoning, then produce the final answer. Either show that reasoning to the user or hide it. Let them see partial questions or expansions so they can correct or refine.
Iterative Response
Offer ways to refine or correct previous outputs. Let them revise an idea or story prompt. Automatically incorporate user feedback into subsequent LLM calls. If images are generated, store the prompts. Let them adjust them to produce improved results with each iteration.
Embedded External Knowledge
Integrate a search API for live information. For each user query, fetch top documents or links. Chunk them and store them as embeddings. Retrieve relevant chunks based on text similarity. Pass them as context to the LLM. Return references to the user. Maintain an in-memory approach in development, but consider a scalable vector DB for production.
Short-Term Memory Implementation
Store user’s selected text or newly generated artifacts in a vector index. Compute an embedding for each chunk using something like OpenAIEmbeddings. Use a similarity measure like cosine similarity to query the index.
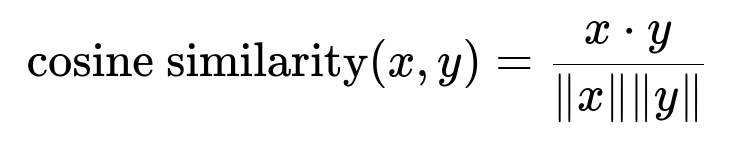
x and y are vector embeddings. x dot y is the dot product. norm x and norm y are the magnitudes of the vectors.
Example Python Snippet
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import HNSWLib
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import VectorDBQAChain
from langchain.llms import OpenAI
def store_and_answer(article_text, user_query):
splitter = RecursiveCharacterTextSplitter(chunk_size=1000)
docs = splitter.create_documents([article_text])
vector_store = HNSWLib.from_documents(docs, OpenAIEmbeddings())
chain = VectorDBQAChain.from_llm(OpenAI(temperature=0), vector_store)
result = chain.run(user_query)
return result
Data is chunked, stored, then queried using the user’s question.
Measuring Success
Track user satisfaction by capturing explicit feedback on generated ideas. Check iteration rates (how often user refines content). Monitor usage frequency, prompt latency, and success in retrieving relevant documents. Evaluate correctness by manually reviewing LLM responses. Reassess performance after introducing new features or prompt changes.
Follow-up question: How would you handle large context sizes exceeding the LLM’s window?
Use chunk-based embeddings and retrieval. Split text into pieces. Store them with a vector store that can perform semantic similarity search. Retrieve only relevant chunks at each step. Merge them into the prompt. Discard unnecessary content. Keep the final input below the maximum token limit.
Follow-up question: How would you ensure up-to-date information?
Call a web search API for queries that need fresh data. Retrieve top articles. Summarize them in smaller chunks. Convert those chunks into embeddings. Store them temporarily in the vector index. Query them for each relevant user prompt. Return the original sources with links to avoid hallucinations.
Follow-up question: Why must responses be in JSON for certain tasks?
Easier to parse, store, and display. A structured format ensures consistency and enables deeper logic. If the LLM always returns the same schema, the downstream code can reliably extract fields. This is useful for scenario generation, creative matrices, or user-specific suggestions.
Follow-up question: How would you handle user feedback loops?
Capture thumbs up or down signals, plus any textual corrections. Re-inject them into the prompt. Update the vector store with user critiques if needed. Summarize them in short text chunks. Retrieve them to adjust next responses. Train a reinforcement mechanism to rank improved outputs higher.
Follow-up question: Why is partial streaming important?
Speeds up perceived response time. Shows immediate output for longer queries. Allows the user to see if the system is generating something irrelevant. They can cancel prematurely. Improves usability and user trust.
Follow-up question: How would you handle scaling this system?
Use containerized services orchestrated by a platform such as Kubernetes. Auto-scale the number of backend workers based on load. For memory storage, adopt a hosted vector DB for large production usage. Cache frequent requests. Add an API gateway with rate-limiting. Monitor usage metrics to allocate resources as traffic grows.