
ML Interview Q Series: A/B Testing Payment Pages: Validating Conversion Differences with Bootstrap Sampling.

Browse all the Probability Interview Questions here.
Suppose you have two versions of a payment page, and you wish to figure out which version drives a higher conversion rate through an A/B test. How would you structure this experiment, analyze its outcome, and then leverage bootstrap sampling to build confidence intervals that solidify your findings?
Comprehensive Explanation
An A/B test is typically used to compare two variations (often called “A” and “B”) of a user-facing component—here, a payment processing page. The goal is to identify which variant yields a superior metric, such as conversion rate (the fraction of users who take a desired action, like completing a purchase).
Formulating the Hypothesis
The essential first step is to clearly define a null hypothesis and an alternative hypothesis:
Null Hypothesis (H0): Both versions produce the same conversion rate.
Alternative Hypothesis (H1): One version produces a higher (or lower) conversion rate compared to the other.
Planning the Experiment
It is crucial to plan the experiment to ensure that your results are meaningful and unbiased. This generally includes:
Ensuring random assignment of users to versions A and B.
Deciding on the sample size required, often computed using statistical power analysis. In practice, you estimate how big of an effect size you want to detect and how sure you want to be of detecting that difference (e.g., 80% power and 5% significance).
Selecting the duration of the test to gather enough data (i.e., enough user samples).
Deciding on the primary metric: in this context, the conversion rate.
Collecting Data
You run the experiment by assigning a portion of traffic to the A version and another portion to the B version. For instance, half of your users might see version A, and the other half see version B. Each user either converts (1) or does not convert (0), resulting in two sets of binary outcomes.
Analyzing Conversion Rates
After collecting sufficient data, you can compute the observed conversion rate in each group:
Let n1 be the number of users in group A, and n2 be the number of users in group B.
Let x1 be the number of conversions in group A, and x2 be the number of conversions in group B.
The estimated conversion rates are p1_hat = x1 / n1 for group A and p2_hat = x2 / n2 for group B.
One core quantity is the difference in observed conversion rates:
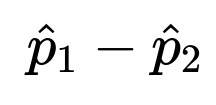
Here, p1_hat = (x1 / n1) is the conversion rate for group A, and p2_hat = (x2 / n2) is the conversion rate for group B. The difference (p1_hat - p2_hat) indicates how much higher (or lower) A’s conversion rate is compared to B’s.
Statistical Significance and Confidence Intervals
A more traditional frequentist approach might use a z-test for the difference in two proportions. The test statistic can be computed using the standard error derived from the observed rates. One way to form a confidence interval for the difference in proportions is:

In that expression, z_{alpha/2} is the z-value associated with your confidence level (for a 95% confidence interval, alpha=0.05, so alpha/2=0.025, which corresponds to about 1.96). The terms p1_hat and p2_hat are the observed conversion rates in groups A and B, respectively, and n1, n2 are the group sizes. This quantity is typically used in the margin of error around (p1_hat - p2_hat).
Bootstrap Sampling for Confidence Intervals
Bootstrapping is a resampling technique that avoids strong distributional assumptions. It works especially well if you are not certain about the shape of the underlying distribution or if the normal approximation is questionable. The steps to apply bootstrap sampling for A/B test results are:
Create many bootstrap samples for each variant by randomly sampling (with replacement) from the observed data in that variant. For each bootstrap sample, compute the conversion rate.
Calculate the difference in conversion rates between these bootstrap samples (i.e., difference in resampled conversion rates).
Repeat this process (often thousands of times) to build an empirical distribution of the difference in conversion rates.
Identify the desired confidence interval bounds from this empirical distribution (for instance, the 2.5th and 97.5th percentiles for a 95% confidence interval).
The resulting interval provides an estimate of the variability in the difference of conversion rates. If this interval does not include zero, it suggests a significant difference in conversion rates between variants A and B with your chosen confidence level.
Below is a simplified Python example demonstrating bootstrap sampling to get a confidence interval for the difference in conversion rates:
import numpy as np
def bootstrap_confidence_interval(data_A, data_B, n_bootstraps=10000, alpha=0.05):
# data_A and data_B are binary arrays: 1 for convert, 0 for not convert
diffs = []
# Observed difference
observed_diff = data_A.mean() - data_B.mean()
# Bootstrap resampling
for _ in range(n_bootstraps):
sample_A = np.random.choice(data_A, size=len(data_A), replace=True)
sample_B = np.random.choice(data_B, size=len(data_B), replace=True)
diff = sample_A.mean() - sample_B.mean()
diffs.append(diff)
diffs = np.array(diffs)
# Sort differences to find quantiles
lower_bound = np.percentile(diffs, 100 * alpha/2)
upper_bound = np.percentile(diffs, 100 * (1 - alpha/2))
return observed_diff, (lower_bound, upper_bound)
# Example usage:
if __name__ == '__main__':
# Suppose group A had conversions in a binary array data_A,
# and group B in data_B
data_A = np.array([1, 0, 1, 1, 0, 1, 0, 1, 1]) # Example
data_B = np.array([0, 1, 0, 0, 1, 0, 1, 0, 0]) # Example
diff, (lb, ub) = bootstrap_confidence_interval(data_A, data_B)
print(f"Observed difference: {diff:.3f}")
print(f"95% Bootstrap CI: [{lb:.3f}, {ub:.3f}]")
Potential Follow-Up Questions
How do you decide on a suitable sample size?
You typically carry out a sample-size calculation before running the experiment. For a two-proportion z-test, you might estimate it by specifying your desired Type I error rate (e.g., alpha = 0.05), your target statistical power (e.g., 0.8), and the minimum detectable effect you want to confidently observe. If your existing data suggests conversion rates around 5%, you can use conventional sample size formulae for difference in proportions or simulation-based approaches to figure out how many users you need.
What if you see a statistically significant difference early in the experiment?
It can be risky to stop an experiment as soon as you see a significant result because of the possibility of random fluctuations and early “wins.” Repeated significance testing inflates the Type I error (false positive) rate if not properly controlled. You either need to pre-define “stopping rules” using approaches such as group sequential methods (like Pocock or O’Brien-Fleming boundaries) or run the test for the full planned duration and sample size before making a decision.
Can you run multiple A/B tests simultaneously?
Yes, but you must be careful if these tests may overlap in traffic and influence one another. Running many tests in parallel can cause interactions between experiments, bias the results, and also inflate the likelihood of Type I errors due to multiple comparisons. Advanced statistical procedures (such as false discovery rate control) or carefully designed multi-armed bandit approaches might be required to handle these situations properly.
How would you handle a scenario where version B slightly improves conversion for mobile users but significantly worsens it for desktop users?
In that case, you may want to segment your data by device type to see if the difference in conversion is consistent across segments. A common pitfall is to pool data across very different user segments and overlook significant heterogeneity. By segmenting (e.g., mobile vs. desktop), you can identify if the effect is positive for certain subsets and negative for others. You might then decide to deploy different versions for different user segments or investigate whether further design changes can fix the negative effect on the other segment.
Are there limitations of bootstrap confidence intervals?
Bootstrapping assumes that your observed sample is representative of the population. If the sample size is very small or if it does not capture the variability of real-world data, the bootstrap intervals may be misleading. Similarly, if data points are extremely skewed or you have heavy-tailed distributions, ordinary bootstrap approaches may require adjustments or robustified methods (e.g., percentile-t, BCa intervals). However, in most typical A/B test scenarios dealing with large user volumes and binary outcomes (converted or not), bootstrapping is a practical and powerful technique for constructing confidence intervals with fewer assumptions.
Below are additional follow-up questions
What if site traffic fluctuates drastically during the experiment?
Large swings in traffic can introduce variability unrelated to the actual difference between the two page versions. For instance, marketing campaigns, holiday season spikes, or external events could cause surges or dips in user volume or user intent. These fluctuations pose a few issues:
Bias in user segments: If the site experiences an influx of a particular demographic during a surge, it can skew results. For example, if the spike is from a promotion targeted at price-sensitive shoppers, the conversion rates for both groups might be systematically altered.
Uneven exposure: Rapid changes in traffic might momentarily overload your system or cause unplanned reassignments of users to conditions if the experiment infrastructure is not robust. This can lead to a mismatch in the actual ratio of users assigned to A vs. B.
Possible seasonality or cyclical effects: If the test lasts long enough, you may inadvertently capture different user behaviors on weekends vs. weekdays or holiday vs. non-holiday periods.
Mitigation strategies include:
Stratified randomization: Split users into known segments (e.g., by region or time of day) to ensure each version receives a balanced share of each segment.
Monitoring user characteristics: Track user demographics or source of traffic to confirm that the distribution remains comparable between A and B throughout the experiment.
Segmented analysis: If you detect big traffic changes, segment the time periods or user groups that were impacted by the fluctuations and analyze them separately. If differences are consistent across these segments, the overall result is more reliable.
How do you handle a sample ratio mismatch (SRM)?
Sample Ratio Mismatch (SRM) occurs when the actual ratio of users in each test condition deviates significantly from the planned ratio. For example, you intended a 50/50 split, but you see 40% of the traffic in A and 60% in B.
Potential causes:
Bugs in the experiment assignment logic (like caching issues or user ID collisions).
Technical problems such as tracking scripts failing in certain browsers or geolocations.
Users dropping off or refreshing the page in a way that re-assigns them unexpectedly to a particular version.
Impact:
SRM can invalidate your assumptions about random assignment and hamper the interpretation of results. The group with fewer users may behave differently simply because of how or why they ended up in that group.
Mitigation and detection:
Chi-square test for random assignment: You can do a quick chi-square check on the number of assigned users vs. expected to see if the mismatch is statistically significant.
Monitor assignment logs: Make sure that the mechanism for assignment is indeed random and not failing under certain conditions (e.g., devices or network connectivity).
Adjust post-hoc weighting: In rare cases, you might weight the results if you strongly believe the mismatch is random. However, it’s usually better to fix the assignment problem and re-run the experiment rather than relying on post-hoc corrections.
What if the primary metric is not binary but a continuous measure (e.g., revenue or time on site)?
When your outcome of interest is continuous, analyzing a difference in means (or medians) often replaces analyzing a difference in proportions. The workflow changes as follows:
Choice of test: Instead of a two-proportion z-test, you might use a two-sample t-test (assuming roughly normal data and larger sample sizes). If normality is highly suspect, you can use a non-parametric alternative like the Mann-Whitney U test or rely on bootstrap methods for differences in means or medians.
Variance considerations: Continuous metrics can have large variance, especially in revenue data (some users might spend huge amounts while most spend little or nothing). This variance inflates standard errors and might require a larger sample size to detect an effect.
Bootstrap approach: You can still use bootstrapping. For each resample in A and B, you compute the mean (or another statistic of interest, like median or 90th percentile) and then examine the distribution of the difference.
How should you account for time-based correlation or repeated measures?
Sometimes the same users might revisit the site multiple times across the experiment period. Or there can be daily/weekly seasonality. This leads to correlated observations rather than purely independent ones:
Repeated visits by the same user: If your user is assigned to version A but visits repeatedly, those visits are not independent. You may need to cluster by user ID so that each user contributes only one consolidated outcome or track them as correlated measures and use hierarchical modeling.
Seasonality: If conversion differs systematically by time of day or day of week, short testing windows can capture incomplete cycles. This can bias the results if, for example, group A by chance sees more users at a high-converting period.
Methods to handle correlation:
Aggregated or cluster-based analysis: Summarize each user’s conversion outcome across the test duration, ensuring each user has a single record (converted at least once vs. never converted, or total times purchased).
Time-series approaches: If the test runs over a long period, you could segment data by day or week and examine how conversions shift over time. ARIMA or other time-series models might help detect changes beyond normal seasonal fluctuations.
How do you address outliers that may skew the results?
In payment or revenue-based metrics, a handful of extremely large purchases can distort averages:
Truncation or Winsorization: You might cap (truncate) or Winsorize (replace values beyond a certain percentile with that percentile’s value) to reduce the impact of extremely large observations.
Non-parametric approaches: Rely on rank-based tests (like Mann-Whitney U) or bootstrap medians that are less sensitive to huge outliers.
Log transformation: If the data is positive and heavily skewed (like revenue), applying a log transform can stabilize variance and reduce outlier impact, though interpretation of “differences in log-scale” requires caution when explaining results to stakeholders.
How do Bayesian approaches differ from frequentist approaches in A/B testing?
In a Bayesian framework, you update your belief about the conversion rate for each variant as data accumulates, producing a posterior distribution over the parameters. Unlike the typical p-value approach, you can directly answer questions like: “What is the probability that version A’s conversion rate is at least 1% higher than version B’s?”
Posterior distributions: Each version’s conversion rate is represented by a distribution that evolves with incoming data. You can then derive the probability that one version is better than the other.
Credible intervals: Instead of classical confidence intervals, you get Bayesian credible intervals that quantify where the parameter is likely to lie given the observed data and chosen priors.
Practical stopping: Bayesian methods often allow more intuitive stopping criteria (“stop if the probability that A is better than B is over 95%”), but one must be mindful of the chosen priors and how quickly or slowly the posterior updates.
How do you handle the “novelty effect” in an A/B test?
Users may be intrigued by any new design and explore or click through more frequently, inflating initial conversion rates artificially. Over time, user curiosity might wane. To address this:
Run the test long enough: Let the novelty effect wear off, and observe if the results stabilize. If you see a spike initially, check if it continues or fades.
Gradual rollouts: If possible, roll out changes to a small percentage of users, watch for short-term spikes or dips, and see if those persist when expanding the test population.
Monitor user engagement pattern over time: Plot daily or weekly conversion metrics to see if version B’s advantage is stable or simply ephemeral due to user curiosity.
How do you handle a “priming effect” or “user learning effect” in repeated visits?
Sometimes the second or third time a user sees a new page, they might be more comfortable with it, leading to higher conversion. On the other hand, if a page is more complicated, repeated visits may reduce conversion. Strategies:
Measure first-time vs. returning users separately: Segment conversions by the visit count or user’s recency. Compare if the new page helps or hurts repeated visitors.
Onboarding or tutorial: If the new design has a learning curve, consider including a brief tutorial or help text to mitigate negative impacts for first-time visits.
What are sequential testing procedures, and how do they help with continuous monitoring?
Sequential testing (e.g., SPRT, group sequential designs) allows you to analyze the data as it comes in and potentially stop the experiment early with controlled Type I and Type II error rates. This is valuable if you want real-time monitoring of your results:
Key advantage: You do not have to wait until the planned end of the experiment to detect a large effect. If one version is clearly winning early on, you can conclude faster.
Key risk: Naively peeking at the data multiple times inflates false positives. Sequential methods incorporate appropriate statistical corrections (like alpha-spending functions) so that you maintain an overall significance level.
Implementation detail: Tools exist for sequential A/B tests, but you have to pre-plan how often to check and precisely how to adjust your significance thresholds at each check.
How would you handle multi-armed bandit testing for more than two variants?
With more than two page versions, multi-armed bandit algorithms (e.g., Thompson sampling, Upper Confidence Bound) help automatically allocate more traffic to better-performing variants over time:
Dynamic allocation: Instead of a fixed 1/n traffic split, the bandit approach updates probabilities of assigning new users to each variant based on accumulated performance.
Speed to optimal: Bandits can reach a better overall conversion rate more quickly than a purely random A/B test because underperforming variants automatically receive fewer new users.
Caveats: You gain efficiency but lose some straightforwardness in analysis—your distribution of users is no longer uniform, so you must carefully account for the adaptive assignment when you interpret results. Traditional confidence interval formulas are not directly applicable. You can, however, use specialized Bayesian or frequentist techniques that incorporate the bandit’s adaptive nature.