
ML Interview Q Series: Accurate Home Price Prediction: Mitigating Target Skewness with Transformations

Browse all the Probability Interview Questions here.
Question: You're creating a model to predict home prices within a certain urban area, and upon examining the distribution of these prices, you observe a pronounced right skew. Should you address this skew, and if so, by what method? Additionally, consider a situation in which your target distribution is strongly left skewed—how would you handle it in that case?
Comprehensive Explanation
When dealing with home price prediction (or any other target variable) where the distribution displays significant skewness, it often implies that the values are not symmetrically distributed around a central location. Right skew means there is a long tail toward larger prices, whereas left skew means a longer tail toward lower prices. Since many regression models (for example, ordinary least squares linear regression) work optimally when their underlying error terms are approximately normally distributed and free of extreme outliers, substantial skew can hamper both model performance and the stability of learned parameters.
Why Skewness Matters
Influence on Linear Regression If the target distribution is heavily right skewed, a linear model may give undue weight to high-value data points. Models like linear regression assume (though not strictly required in theory for unbiasedness) that residuals are homoscedastic and somewhat normally distributed. Extreme skewness can produce heteroscedastic residuals, undermining some standard assumptions.
Impact on Error Metrics Large outliers in a right-skewed distribution can inflate metrics such as the mean squared error (MSE). Because MSE penalizes large errors more severely, the model might become less sensitive to the typical range of values and overly fixated on the rare high-priced homes.
Interpretation Difficulties Sometimes, in practical business settings, interpreting the model is easier if the target variable is roughly normally distributed.
Common Remedies for Right Skew
A popular approach to address right skew is to apply a log transform or a similar power transform (like a Box-Cox transform) to the target variable. Log transforms help compress large values and expand lower values, effectively reducing the imbalance of a long tail.
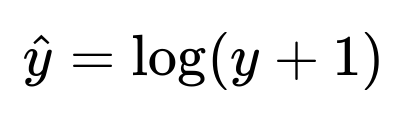
Where y is the original price, and we add 1 inside the log to avoid mathematical issues when y is zero or near zero. After applying this transform, the model is trained on log(y + 1) rather than on y itself. During prediction, you’d produce a prediction in log space and then exponentiate (and subtract the 1) to map it back to the original price space.
In detail:
y is the actual home price.
The constant 1 is used to prevent taking the log of zero or negative values.
Transforming via log compresses large y values more than small y values, which reduces skewness.
When you evaluate performance, you can compare predictions in the original price domain by exponentiating the model outputs and subtracting 1 to revert to the original scale.
Handling Left Skew
If the distribution is skewed to the left, you have a long tail toward lower prices. One approach is to reflect the distribution or use a power transform that can adapt to negative or left-skewed distributions (for example, the Box-Cox or Yeo-Johnson transform). In practice, the approach can be:
Reflect the Data In certain cases, you can transform the data by taking a negative of the values, effectively turning left skew into right skew, and then apply the same log transformation. However, this is usually done if the values are all positive and the left-skewed tail is not extremely close to zero.
Box-Cox / Yeo-Johnson These transformations can systematically reduce or increase skew in either direction. They have a parameter lambda that controls the nature of the transformation and can be learned from the data to optimize normality.
Practical Steps
Inspect Data and Residuals Verify whether skewness significantly affects your model. Sometimes you can get away without transformations if your model is flexible (e.g., tree-based methods like Gradient Boosted Decision Trees may handle skew reasonably well).
Apply a Transformation If you choose to reduce skew, apply transformations like log(y + 1) for right-skewed data or Box-Cox for any general skew (right or left).
Transform Predictions Back When predicting, remember to invert the transformation. For a log transform, you exponentiate. For Box-Cox or Yeo-Johnson, you apply their respective inverse transforms.
Evaluate Model Appropriately Use error metrics that are consistent with the transformed or untransformed scale. If your main business metric is about absolute price differences, you want to interpret predictions after mapping them back to the original domain.
Potential Pitfalls
Interpretability A model trained on log prices may predict well but can complicate direct interpretation of coefficients in linear methods. You must remember that coefficients now represent relationships in log-space rather than the original price space.
Zero and Negative Values If your data has zero or negative target values, you must shift or carefully handle them before applying a log transform.
Extrapolation Errors Extreme values outside the observed range might lead to odd extrapolations when you invert the transform, especially if the model sees an input well outside the training distribution.
Follow-Up Questions
How could you decide whether to log-transform or use a Box-Cox/Yeo-Johnson transform?
You can compare the goodness of fit and the distribution of residuals under each transformation. If log-transforming yields residuals that look more homoscedastic and normally distributed, it might suffice. For more complex skew patterns (like zeros, negative values, or strong left skew), Box-Cox or Yeo-Johnson may be a better fit because these transforms have parameters that can be optimized to reduce skewness in a more flexible way.
Could tree-based models handle skewed distributions without explicit transformation?
Tree-based models (Random Forests, Gradient Boosted Trees, etc.) do not rely on assumptions of linearity or normality in the residuals, making them more robust to skewness than ordinary least squares regression. However, heavily skewed targets can still lead to suboptimal performance if extreme values dominate the loss function. If the skew is very pronounced, it may still be beneficial to experiment with target transformations to see if the model’s performance improves.
What if my metric is not MSE but something like MAE or MAPE?
Mean Absolute Error (MAE) is less sensitive to large outliers than MSE. Right or left skew might not be as detrimental to MAE-based optimization.
Mean Absolute Percentage Error (MAPE) is heavily influenced by values close to zero. Extreme left skew (where many data points are small but nonzero) can cause extremely high or erratic percentage errors. A log transform can help because it stabilizes percentage changes in the original scale.
How to handle interpretability after transforming the target?
For linear or logistic-based models, the coefficients are now explaining variance in the transformed space. If interpretability in original price units is crucial, you must:
Convert predictions back to original scale for final interpretation.
Use partial dependence plots or other model-agnostic methods to interpret how features influence the log of the price, and then discuss approximate percentage changes (since a coefficient in log space approximately translates to a percentage change in the original domain).
Could transformations help with non-Gaussian error distributions besides skew?
Absolutely. Target transformations can sometimes correct issues like heavy tails or even out the variance across different ranges. Box-Cox and Yeo-Johnson transforms are widely used for making an outcome variable more Gaussian-like and for stabilizing variance, which can be helpful even beyond skewness.
How would you implement a simple log transform for training a regression model in Python?
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Suppose we have data X and prices y
X = ... # Feature matrix
y = ... # Price array
# Transform the target to log(y+1)
y_log = np.log(y + 1)
# Train a simple linear regression on the transformed target
model = LinearRegression()
model.fit(X, y_log)
# Predictions in log space
pred_log = model.predict(X)
# Convert predictions back to original price scale
pred_original = np.exp(pred_log) - 1
# Evaluate performance using MSE in original space
mse_original_scale = mean_squared_error(y, pred_original)
print("MSE in original space:", mse_original_scale)
This illustrates a straightforward way to apply and invert a log transform. In practice, you would also do train-test splits, cross-validation, or more sophisticated methods to assess performance.
All these considerations show that when you notice a skew in your target variable—whether right or left skew—you often need to think about transforming your data or using a modeling approach that naturally accounts for skewness.
Below are additional follow-up questions
What challenges arise when the target variable includes zero or negative values, and how can we address skew in such scenarios?
A major challenge is that common transformations, such as log(y+1), become invalid or awkward when y can be negative or zero. Even if y = 0 is allowed, the log transform depends on choosing a shift to avoid taking log(0). When y < 0, you cannot apply a standard log transform at all.
One approach is the Yeo-Johnson transform, which generalizes the Box-Cox transform to handle zero and negative values by splitting the transformation logic based on the sign of the data. Box-Cox itself typically requires strictly positive values. Alternatively, you can perform a constant shift (e.g., y + C) so that all values become positive before applying log, though it requires caution in selecting C to avoid compressing the data too much or distorting the distribution.
A pitfall is that if the dataset contains only a few negative values caused by data entry errors, you should investigate data quality rather than forcing a transformation to accommodate them. Another edge case: if y can be zero in large quantities (e.g., certain property listings that might be missing a correct price), you have a mass at zero and a continuous distribution for y > 0. Consider a two-part model that first predicts whether y is zero or not, then predicts the positive outcome, or use transformations specifically designed for “zero-inflated” distributions.
How should you handle a situation where the target distribution is extremely wide but not necessarily skewed?
A wide distribution means your home prices might span several orders of magnitude, from very low to extremely high. Even if this distribution is somewhat symmetrical, models can struggle to handle such breadth without specialized approaches.
One potential remedy is to still apply a log transform, not only for skewness but also to compress wide ranges into a more manageable scale. Another solution is standardization or min-max normalization of the target, but this typically does not solve the underlying issue of outliers at the extremes. If the distribution is genuinely wide yet relatively symmetrical, the model might handle it directly, especially if using robust regressors (e.g., models that minimize absolute errors). The pitfall: compressing a wide but approximately symmetric distribution with a log transform might introduce a slight skew where none existed before, so checking the residual distributions is crucial.
How do you approach the problem of modeling home prices when the dataset is small and contains outliers?
With a small dataset, each outlier can disproportionately affect your model. For instance, an extremely high-priced home or a distressed property sold at a very low price can heavily sway parameter estimates. In such scenarios:
Robust Regression: Techniques like Huber Regression or RANSAC can reduce the impact of outliers on the model parameters.
Cross-Validation: Apply thorough cross-validation to ensure that an outlier isn’t unduly influencing results in a single split.
Transformation: A log or Box-Cox transform can reduce outlier influence if the data is skewed or if outliers are on the right tail. However, if outliers stem from genuine special cases (e.g., a luxury penthouse), ask whether they should remain or if they should be modeled separately.
Pitfalls: Overfitting can arise if you treat outliers as typical data. Conversely, removing them might discard valid information about extreme properties.
What if the transformation fails to fix the skew or the residual distribution remains problematic?
It’s entirely possible that a single power-based transform doesn’t fully “normalize” the target or fix the skew. In such a case:
Try Different Transform Families: Sometimes a log transform is not enough. Box-Cox, Yeo-Johnson, or even more flexible transformations like spline-based methods might capture the data distribution more effectively.
Model Choice: Consider whether a parametric model (like linear regression) is too restrictive. Non-parametric or tree-based models (Random Forest, Gradient Boosting) could handle skewed or heavy-tailed distributions better without requiring perfect normality in residuals.
Residual Analysis: Evaluate if the residuals are systematically skewed or if only a few extreme points remain outliers. If the majority of the distribution is improved but a few data points remain outside, it might be acceptable.
Edge cases: If your data has multiple modes (e.g., one cluster of very cheap homes, another cluster of very expensive ones), no single power transform might remove the multi-modality, and you might need advanced techniques such as mixture models or segmenting your data by property type.
How do you handle extremely large or small predictions that go beyond your training range?
Extrapolation beyond the training range is always risky. When you apply transformations like log, large values in the original space get compressed in log space, so the model may not adequately learn how to handle prices much bigger than what it’s seen.
Conservative Clamping: Some practitioners clamp predictions at a reasonable minimum or maximum so that obviously implausible numbers are not returned.
Regularization and Tighter Bounds: Use domain knowledge (e.g., you know the maximum possible home price in the city). Adding constraints or penalty terms can reduce wild extrapolations.
Data Augmentation: If possible, gather more data, especially covering the extremes. If your training set lacks enough examples of ultra-high-priced homes, your model will be uncertain in that regime.
Pitfalls: Overly restricting the prediction range might bias the model if the extremes are legitimate. Also, forcibly clamping could hide the fact that the model is not generalizing well.
Should we consider normalizing or standardizing the target variable if it’s numeric but heavily skewed?
Normalization or standardization (subtract mean, divide by standard deviation) alone might not sufficiently handle strong skewness. These methods shift and scale the distribution but do not reshape it in a way that drastically reduces asymmetry. If you only want to ensure the target is on a comparable scale to your features (for example, in certain neural network frameworks), standardization might be enough. But for reducing skew, you usually need a non-linear transform (log, Box-Cox, etc.).
A subtlety is that you can combine standardization with a skew-oriented transform—first apply log to reduce skew, then standardize the log-transformed values if your modeling method benefits from data centered around zero. Remember to invert these transformations in the correct order when returning to the original scale.
How do changes in market trends over time affect the skewness of home prices?
Real estate markets often show trends such as gradual price appreciation or abrupt changes (e.g., market bubbles). If your data spans many years, the distribution of prices in earlier years may be significantly different from later years. This can lead to varying degrees of skew in different time windows.
Temporal Segmentation: Split the dataset by time and check if each segment has a similar distribution. If older segments exhibit a different skew or different median price range, you may need time-aware modeling, such as including time-based features or modeling each period separately.
Rolling Transform: In a time series context, you might apply local transformations or train separate models if distribution shifts are dramatic.
Edge Cases: Large macro-economic changes (e.g., financial crises) can abruptly alter both the mean and tail behavior of prices. A single global transform might be insufficient if the fundamental distribution changes. You might need to partition your data or incorporate macroeconomic features.
How to address multi-modal distributions in housing prices?
Sometimes the overall price distribution is not a single peak plus a tail but rather multiple peaks—for instance, an urban core with expensive properties and less expensive suburban properties. In such cases:
Segment the Data: Create separate models for each segment (e.g., apartments vs. single-family homes, urban vs. suburban). By focusing on more homogeneous groups, each sub-model might have a more manageable distribution with less skew.
Cluster-based Approaches: Use unsupervised clustering or domain knowledge to identify distinct subpopulations. Then transform each cluster’s target distribution accordingly if needed.
Pitfall: Over-segmentation can reduce data for each sub-model, leading to overfitting. Also, if there is overlap between segments (some suburban areas might have high-end properties comparable to urban homes), the boundary between sub-models might be ambiguous.
How do target transformations influence advanced interpretability tools such as SHAP or LIME?
When you transform the target variable (e.g., by taking log), SHAP or LIME are explaining the model’s behavior on the transformed scale, not the original. If the user is interested in how a feature affects the actual home price, you need to interpret the results carefully:
Re-Scale the Explanations: In the log space, an increase of a certain input feature might correspond to a multiplicative effect on price. For example, a feature that increases the log-price by 0.1 implies roughly a 10% increase in the original price.
Pitfall: Directly presenting SHAP values from the transformed model can confuse stakeholders who think in terms of actual price differences. You often need a post-processing step or an explanatory note clarifying the scale on which the predictions operate.
These considerations underscore how transformations can solve skew-related issues but bring their own complexities in real-world scenarios, including interpretability, data segmentation, time shifts, and advanced modeling techniques.