
ML Interview Q Series: Assessing Content Reviewer Diligence Using Bayes' Theorem and Labeling Patterns.

Browse all the Probability Interview Questions here.
A social media platform employs a group of reviewers who each tag content as either spam or non-spam. Ninety percent of these reviewers are conscientious, labeling about 20% of items as spam and 80% as non-spam. The other ten percent are less attentive and mark all content as non-spam. If a given reviewer labels four consecutive pieces of content as non-spam, what is the probability that the reviewer belongs to the conscientious group?
Short Compact solution
We define two events. Let D be the event that a reviewer is diligent (90% chance), and let E be the event that the reviewer is not diligent (10% chance). Let 4N denote the event that the reviewer has assigned four pieces of content in a row as non-spam.

The probability that a non-diligent reviewer labels any piece of content as non-spam is 1, so for four consecutive pieces it remains 1.
Using Bayes’ Theorem:

Substituting:
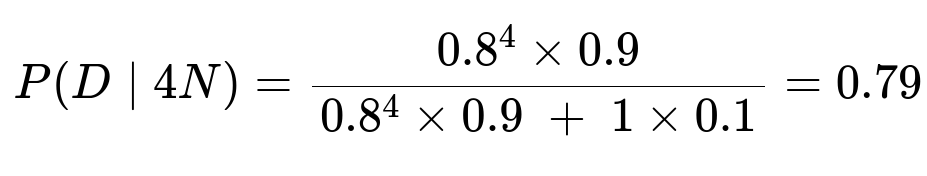
Hence, there is a 79% probability that the reviewer is diligent given that they have labeled four items consecutively as non-spam.
Comprehensive Explanation
Understanding the Scenario
In this problem, the platform relies on human reviewers. These reviewers each see pieces of content and classify them as spam or non-spam. The question states that a majority (90%) are diligent, meaning they are more accurate, while a smaller fraction (10%) are not. The diligent reviewers still sometimes tag content as spam (20% of the time), and the less attentive reviewers never tag anything as spam.
We observe that a reviewer has labeled four pieces of content as non-spam in a row. We want to figure out how likely it is that this reviewer belongs to the conscientious group.
Applying Bayes’ Theorem
Bayes’ Theorem is the foundation for updating our belief about whether the reviewer is diligent after seeing the evidence: the event that they labeled four consecutive items as non-spam.
We write:
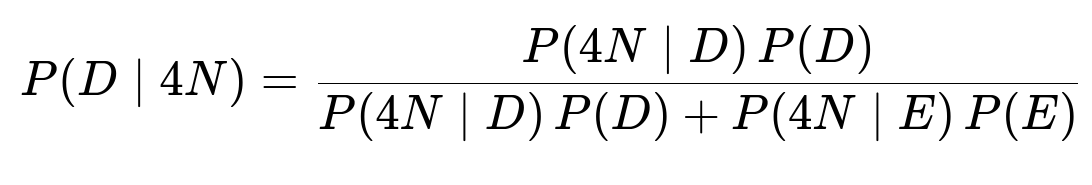
Prior Probabilities
P(D)=0.9 is the prior probability that a reviewer is diligent.
P(E)=0.1 is the prior probability that a reviewer is not diligent.
Likelihoods

P(4N∣E) is the probability that a non-diligent reviewer produces four non-spam labels. Because a non-diligent reviewer labels everything as non-spam (100%), the probability is 1 for all four pieces.
Normalizing the Posterior
Substituting the known values into Bayes’ formula, the denominator sums the probability that a diligent rater would produce four non-spam labels plus the probability that a non-diligent rater would do so, weighted by their respective prior probabilities.
As shown, the calculation yields 0.79, which is a 79% chance that the reviewer is diligent after observing four consecutive non-spam labels.
Intuitive Explanation
Although it might seem more likely that someone labeling four items as non-spam could be non-diligent (since they always choose non-spam), the key fact is that the vast majority (90%) of reviewers are diligent in the first place. Even though labeling four items consecutively as non-spam is more probable for the non-diligent reviewer, the large prior (0.9) for being diligent shifts the posterior probability strongly toward diligence.
Practical Considerations and Real-World Extensions
Large Number of Observations: If we observed more than four items, say 50 items in a row as non-spam, the probability might shift more dramatically toward the reviewer being non-diligent, unless the reviewer’s normal rate of marking spam changes.
Changing or Mixed Behaviors: Real human reviewers may not be strictly “always non-spam” or “20% spam.” There may be intermediate states or times when a diligent reviewer becomes fatigued and inadvertently marks everything one way.
Different Spam Distribution: In practice, not all content is equally likely to be spam. The prior beliefs about the fraction of spam on the platform might influence these probabilities.
Combining Multiple Signals: A typical system would combine this type of modeling with other signals (accuracy metrics, time taken to review, historical performance) to build a more comprehensive model of reviewer diligence.

Potential Follow-up Questions
How would the calculation change if the reviewer labeled three pieces as non-spam and one as spam?
When dealing with a slightly different scenario (e.g., three non-spam and one spam), we would modify our likelihood terms accordingly. For a diligent reviewer with an 80% chance of marking a given item as non-spam (and 20% spam), the probability of exactly three non-spam and one spam in any order, assuming independence, would be:

A non-diligent reviewer has a 100% chance for non-spam. So if they ever label one as spam, that scenario has probability 0. In that situation, P(4N∣E) is no longer relevant; we’d actually consider P(3N,1S∣E)=0. Then we’d apply Bayes’ Theorem with these updated likelihoods.
Could there be any bias if the true prevalence of spam in the content is different from the labeling rates assumed here?
Yes. In reality, if only 1% of content is spam but a diligent reviewer is marking 20% as spam, there may be a mismatch between the actual distribution of spam and the reviewer's internal threshold or instructions. This mismatch can create systematic biases in classification. Our calculation here treats the model’s parameters (20% for spam vs. 80% for non-spam) as given truths for a conscientious rater, but they could differ if the true data distribution shifts.
What if the system had more refined categories than just spam or non-spam?
In a more complex labeling system—e.g., spam, adult content, violence, misinformation, and so on—the probability of an entirely consistent labeling pattern would be computed across all categories. A diligent reviewer might have certain probabilities of selecting each category, whereas a non-diligent one might choose a simpler pattern (like ignoring some categories entirely). The same Bayesian approach would still apply but with more categories in the likelihood computation.
How can we monitor a reviewer’s diligence over many weeks or months of activity?
One approach is to maintain a running Bayesian update over time. Each new label from a reviewer updates our posterior about whether they are likely diligent or not. In practice, we might use more flexible distributions—like Beta distributions for Bernoulli labeling tasks—and continuously update the reviewer’s parameters. We can then set thresholds (e.g., if the posterior probability of being non-diligent becomes sufficiently high, we might remove or retrain that reviewer).
Would it make sense to consider partial compliance levels rather than a strict “always non-spam” for non-diligent reviewers?
Yes, real-world scenarios are usually more nuanced. A reviewer might be lazy (and thus close to 100% non-spam) but occasionally mark something as spam. One might model this with a Beta distribution around the spam probability for each reviewer, starting with some prior that non-diligent raters have a small spam probability (like 5%), whereas diligent raters have a higher but still plausible spam probability (like 20%). Over many judgments, these parameters would converge to best fit the observed labels.
Could this situation be handled with a hypothesis testing perspective instead of Bayesian?
Yes, it could be framed as a hypothesis test:

Example of a Simple Python Simulation
Below is an illustrative Python snippet showing how a simulation could estimate P(D∣4N) empirically:
import random
def simulate_rater_labels(num_trials=10_000_000):
# Probabilities
p_diligent = 0.9
p_spam_diligent = 0.2
# Counters
total_four_nonspam = 0
diligent_given_four_nonspam = 0
for _ in range(num_trials):
# Decide if the rater is diligent
is_diligent = (random.random() < p_diligent)
# Generate 4 labels
four_nonspam = True
for _ in range(4):
if is_diligent:
# Rater labels spam with prob p_spam_diligent
label_spam = (random.random() < p_spam_diligent)
else:
# Non-diligent always labels as non-spam in this model
label_spam = False
if label_spam:
four_nonspam = False
break
# Check outcomes
if four_nonspam:
total_four_nonspam += 1
if is_diligent:
diligent_given_four_nonspam += 1
return diligent_given_four_nonspam / total_four_nonspam if total_four_nonspam else 0
estimated_probability = simulate_rater_labels()
print("Estimated Probability of D being True given 4 Non-Spam:", estimated_probability)
When run, this simulation should produce a number close to 0.79, matching the analytical answer.
Below are additional follow-up questions
Is there a threshold for how many consecutive non-spam labels become strong evidence of non-diligence?
A straightforward question is whether observing more than four consecutive non-spam labels from a reviewer can greatly increase the likelihood they are non-diligent. Each additional piece of content labeled as non-spam without a single spam label will incrementally shift the posterior probability in favor of non-diligence (under a model that assumes non-diligent reviewers always label items as non-spam).
Reasoning Process

Edge Case
If a diligent reviewer has an unusually low probability of marking items as spam (perhaps 5%), that changes the likelihood factor considerably, affecting how quickly multiple non-spam labels push the posterior probability toward non-diligent.
In a real system, the threshold for flagging a reviewer as likely non-diligent might also depend on how harmful false negatives (spam labeled as non-spam) can be, and not purely on the Bayesian posterior.
How would a shift in the priors affect the outcome?
In the original scenario, 90% of the reviewers are conscientious. One might ask what happens if this prior probability changes. For instance, suppose only 60% are diligent instead of 90%.
Reasoning Process
In the original formula for P(D∣4N), the prior P(D)=0.9 appears in both the numerator and the denominator.
If you reduce P(D), the fraction P(D∣4N) tends to decrease because we initially believe fewer reviewers are diligent.
Conversely, if P(D) is higher (say 95%), then after seeing four non-spam labels, we would be even more certain the reviewer is diligent.
Edge Case
If the platform’s workforce composition changes rapidly (new hires, varied training), the prior might shift frequently. Adapting in real time to these new priors becomes essential for maintaining accurate estimates.
What if the inherent spam probability of content changes frequently?
In practice, the actual prevalence of spam on the platform may be dynamic. There could be events (bot attacks, spam campaigns) that drastically increase the fraction of true spam content for certain durations.
Reasoning Process
If suddenly most content is indeed spam, a diligent reviewer’s probability of labeling spam might rise above 20% (since they adapt to the true distribution).
Non-diligent reviewers might still mark everything as non-spam, making them more obviously incorrect.
The prior belief about how a “diligent” reviewer behaves has to be updated periodically to reflect the changing external conditions.
Edge Case
If the platform does not update the definition of “diligent,” you might incorrectly classify reviewers who adapt to the changing spam distribution as “non-diligent” or vice versa.
What ethical considerations arise if we misclassify a reviewer?
Beyond the purely statistical view, there are human and operational aspects. A reviewer who is actually diligent but just happened to see multiple non-spam items in a row might be wrongly flagged.
Reasoning Process
False positives in labeling a reviewer as non-diligent could harm morale, cause the platform to lose a good reviewer, or create a chilling effect.
False negatives (allowing a non-diligent reviewer to continue) might lead to large volumes of spam going unmarked, negatively impacting the user experience.
Edge Case
In high-stakes content moderation, a small miscalculation can have major consequences for user safety and platform reputation. Balancing these ethical concerns often requires a more cautious threshold or additional verification steps before finalizing a decision.
Could the system handle partial or uncertain decisions from reviewers?
Sometimes, reviewers might not give a simple binary spam/non-spam decision. They could provide additional metadata such as a confidence level, or a subcategory of spam (e.g., "phishing," "explicit content," etc.) that hints at the certainty of their labeling.
Reasoning Process
Instead of modeling the reviewer as always picking a single label with fixed probabilities, you would represent each reviewer’s decisions as a probability distribution over multiple labels or confidences.
A Bayesian approach could incorporate this richer information, updating the reviewer’s reliability more subtly than with a simple binary observation.
Edge Case
Reviewers might label “likely spam” vs. “definitely spam,” which adds complexity to how we compute P(4N∣D) or other sequences. The underlying probabilities would need refinement to incorporate such multi-level feedback accurately.
What if the 20% spam labeling rate for a diligent reviewer is really an average across different content categories?
In many real-world scenarios, "spam" can be a broad category comprising many sub-types. A reviewer might label suspicious ads as spam 40% of the time, but they label hateful content incorrectly only 10% of the time, etc. The overall 20% might be an aggregate figure across varied types of content.
Reasoning Process
If in one specific category the reviewer’s probability of calling it spam is much higher or lower, a sequence of four non-spam labels in that category might provide stronger or weaker evidence than we would gather by pooling all categories.
The correct model would handle separate probabilities for each category and combine the evidence across categories to obtain the overall posterior probability of reviewer diligence.
Edge Case
If the mixture of categories changes, then the interpretation of "20% spam labeling" also changes. Without acknowledging these category dynamics, you might incorrectly update your belief about the reviewer.
How does the cost of mislabeling spam versus non-spam factor into a final decision?
Often, classifying non-spam as spam might have different consequences (e.g., user annoyance, possible censorship) than failing to label actual spam (which can degrade platform quality).
Reasoning Process
A platform might not treat a 79% posterior probability the same as a 99% posterior probability. The cost or penalty of each misclassification type might lead to different thresholds for action.
Decision theory approaches can incorporate a cost matrix that weights the risk of either misclassifying a diligent reviewer as non-diligent or letting a truly non-diligent reviewer slip through.
Edge Case
If spam has a very high cost for the platform (e.g., regulatory fines, legal trouble), the system might set a lower threshold for suspecting a reviewer is non-diligent, leading to stricter monitoring. This can increase false positives, which might also be detrimental in other ways.
How might the system adapt automatically if reviewer behavior drifts over time?
Reviewers may change their labeling patterns gradually (fatigue, better training, changing personal views). A fixed approach based on a single calculation may become stale.
Reasoning Process
The model would ideally be updated over time with something like an online Bayesian update, where each new piece of labeling data re-adjusts the posterior probability of diligence.
One could employ a sliding window or exponential forgetting factor to ensure old data does not overshadow newer behavior.
Edge Case
If a reviewer starts out diligent and slowly transitions to less attentive, a system that lumps all data together might still classify them as diligent for too long because of their large initial track record of correct labels.
What if a non-diligent reviewer occasionally marks spam to avoid detection?
In reality, a lazy or malicious reviewer might sometimes deliberately mark a small fraction of items as spam just to appear random and avoid suspicion. This breaks the assumption that “non-diligent” equals “all non-spam.”
Reasoning Process
The model for non-diligent reviewers must then allow for a small probability of spam labeling. Perhaps set it at 5% or 2% — something notably lower than 20% but not zero.

Edge Case
A crafty reviewer might fluctuate their spam labeling rate randomly. The platform may need more advanced anomaly detection or time-series analysis of labeling patterns to catch subtle gaming behaviors.
Could external data or quality checks refine our estimate of a reviewer’s diligence?
Sometimes, a system might have “golden sets” of known spam or non-spam items used for testing. If a reviewer consistently labels these known items incorrectly, that’s strong evidence they are non-diligent.
Reasoning Process
Instead of passively observing the reviewer’s labels, the platform could introduce test items (like “honeypot” spam or verified non-spam) at intervals.
The reviewer’s performance on these test items updates the Bayesian model quickly and provides a controlled measure of diligence.
Edge Case
If test items do not reflect the variety of real content, a reviewer might pass these tests but still do poorly on more ambiguous live content. Careful curation of test items is crucial.
