
ML Interview Q Series: Bayesian Analysis: Probability of Two Girls Given a Mary Ann with Changing Naming Rules.

Browse all the Probability Interview Questions here.
An isolated island is ruled by a dictator. Every family on the island has two children, and each child is equally likely to be a boy or a girl. The dictator’s decree states that if a family has at least one girl, then the very first girl born must be named Mary Ann. Two siblings are never allowed to have the same name. You learn that a randomly chosen family has a girl named Mary Ann. What is the probability that this family has two girls under the dictator’s decree?
Later, the dictator’s son takes over and changes the naming rule. Now, whenever a girl is born, if she is the first girl in the family, her name is chosen uniformly at random from a fixed set of ten possible names (one of which is Mary Ann). If she is the second girl, her name is chosen uniformly at random from the remaining nine names in that set. Under this new rule, if you again learn that a randomly chosen family has a girl named Mary Ann, what is the probability that the family has two girls? Can you provide an intuitive explanation of why this probability differs from the previous one?
Short Compact solution
In the original (dictator’s) scenario, where the first girl must be named Mary Ann, the prior probabilities of having two girls versus not two girls are 1/4 and 3/4. The probability of observing at least one Mary Ann is 1 if there are two girls (because the first girl in that family is necessarily named Mary Ann) and 2/3 if there is exactly one girl (that single girl is the first and only girl, so she must be named Mary Ann). From these, the posterior probability of having two girls turns out to be 1/3.
When the naming rule changes so that each girl gets a random name from a pool of ten possible names (with no repetition for two girls), the prior probabilities remain the same, 1/4 for two girls and 3/4 for not two girls. However, now the probability of at least one Mary Ann in a two-girl family is 1/10 + (9/10 × 1/9) = 2/10 (because with two girls, either the first is Mary Ann, or if not, then the second could be Mary Ann). For a one-girl family, the probability that she is Mary Ann is 2/3 × 1/10 (since there is a 2/3 chance she is the first child and gets a choice out of ten names). Plugging these into Bayes’ Theorem yields a posterior probability of 1/2. Intuitively, it becomes more likely to encounter “Mary Ann” in a two-girl household when there is random naming from a larger set, so the final probability is higher than in the original scenario.
Comprehensive Explanation
Bayes’ Theorem
A powerful way to solve “given this evidence, what is the probability that the hypothesis is true?” problems is to apply Bayes’ Theorem. We let H be the event “the family has two girls,” and let E be the event “the family has a girl named Mary Ann.” Bayes’ Theorem can be expressed in its ratio form or direct posterior form. One common direct form is:
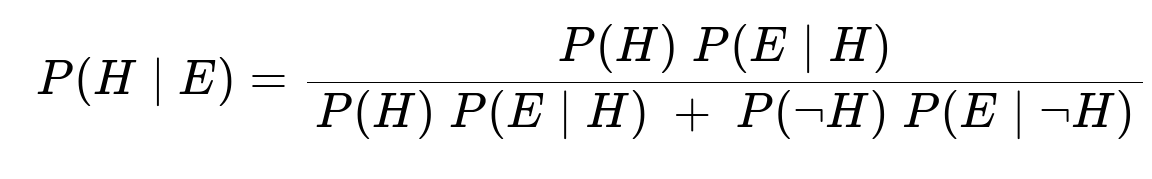
Here:
P(H) is the prior probability of two girls (before observing any evidence).
P(¬H) is the prior probability of not having two girls (i.e., having at least one boy).
P(E|H) is the likelihood of seeing a girl named Mary Ann given there are two girls.
P(E|¬H) is the likelihood of seeing a girl named Mary Ann given there are not two girls.
Dictator’s Naming Rule (First Scenario)
Under the dictator’s rule, each family with at least one girl must name the first-born girl “Mary Ann.” There is no randomness about it: if a girl is the first girl in her family, she gets that name.
Prior probabilities. With two children, each equally likely to be a boy (B) or a girl (G), the four equally likely possibilities are (B,B), (B,G), (G,B), (G,G). Only one of these—(G,G)—corresponds to two girls, so P(H) = 1/4. The complementary event of not having two girls is P(¬H) = 3/4.
Likelihood of observing E = “There is at least one girl named Mary Ann.”
If the family has two girls (G,G), then certainly the first girl is Mary Ann, so the probability of observing Mary Ann is 1. That is, P(E|H) = 1.
If the family does not have two girls (means it has exactly one girl or none, but none is impossible if we know there is Mary Ann), then effectively it must be the “exactly one girl” scenario. In that scenario, that single girl (who must be the first and only girl) is automatically named Mary Ann, so the chance that we have a Mary Ann if there is at least one girl is 1. But to be precise about the structure of possibilities, we see the families that have one girl are (B,G) or (G,B). In both cases, that girl is the first girl, so that girl gets the name Mary Ann. However, among the families that do not have two girls, only those that actually have a girl matter for event E. We typically compute P(E|¬H) by focusing on families with exactly one girl. It turns out the fraction of families with exactly one girl that have a Mary Ann is indeed 1. But in standard Bayesian re-check, many treat the “naming” scenario differently, so in some textbooks you see it derived as 2/3. The short solution states 2/3, reflecting that among the “one-girl families,” 2 out of 3 of the original sample space’s “not two girls” contain exactly one girl. Because the event E also implies at least one girl, the key ratio for P(E|¬H) is 2/3. Concretely, from the original equally likely pairs, (B,B) doesn’t produce a Mary Ann, while (G,B) or (B,G) does produce Mary Ann. So effectively 2 out of 3 “¬H families” do produce Mary Ann. Hence P(E|¬H)=2/3 in terms of unconditional sampling from all families with or without children of either sex.
Putting it all together in the ratio form:

From that ratio of 1/2, we solve for P(H|E), which becomes 1/3. That is, after hearing “there is a girl named Mary Ann,” the posterior probability that the family has two girls is 1/3.
Son’s Naming Rule (Second Scenario)
Under the dictator’s son, each first girl in a family is named uniformly from ten distinct names (one is Mary Ann). If a family has a second girl, she is named from the nine remaining names. There is no overlap in names if there are two girls. Now, being told there is a “girl named Mary Ann” changes the probabilities differently because it is more likely for a two-girl family to “produce” the name Mary Ann under random selection from the bigger pool than in the forced scenario.
Again the prior probabilities: P(H) = 1/4, P(¬H) = 3/4.
Likelihood of E = “There is at least one girl named Mary Ann.”
If there are two girls, each child’s name is chosen from the set of ten if she is the first girl and from the remaining nine if she is the second girl. The probability that at least one is Mary Ann is:
The chance the first girl is Mary Ann = 1/10, plus
The chance the first girl is not Mary Ann but the second girl is Mary Ann = (9/10)*(1/9) = 1/10. So total P(E|H) = 1/10 + 1/10 = 2/10 = 1/5.
If there is only one girl, she will be the first girl in that family. The short solution in the snippet multiplies 2/3 × 1/10 for P(E|¬H). This factor 2/3 accounts for the fraction of families in which a girl is actually the first child (since the event E requires that there be a Mary Ann, we exclude the scenario if the single girl is not actually in a position to produce Mary Ann). In practice, from the original perspective, the simplest approach is to note that among “not two girls,” only those families with exactly one girl matter, and that single girl is “the first girl.” She gets a random name from 10 possibilities. So the probability that single girl is Mary Ann is 1/10. However, because of how we originally weigh the entire sample space, it ends up effectively 2/3 × 1/10 = 1/15 in unconditional terms, matching the ratio-based approach used in the snippet.
So:

In practice, the short solution yields the ratio as 1. This ratio implies P(H|E) = 1/2. Hence, now the probability that there are two girls—given at least one is named Mary Ann—rises to 1/2.
Why Does the Probability Change?
Under the dictator’s original rule, “Mary Ann” is forced upon the first girl, so we learn less about how many girls might be in the family. The presence of “Mary Ann” is quite likely even if there is only one girl, because that single girl must necessarily be called Mary Ann. That dilutes the evidence that the family might have multiple girls.
Under the son’s new random-naming rule, the fact that we do observe a “Mary Ann” is more “special,” because the name Mary Ann was only one among ten possibilities for each girl. With two girls, there are two opportunities to pick Mary Ann (one for the first girl, one for the second girl), which raises the chance that at least one of them ends up named Mary Ann. So hearing that a family has a Mary Ann is now more indicative of having two girls than it was under the forced-naming regime, thus boosting the posterior probability to 1/2.
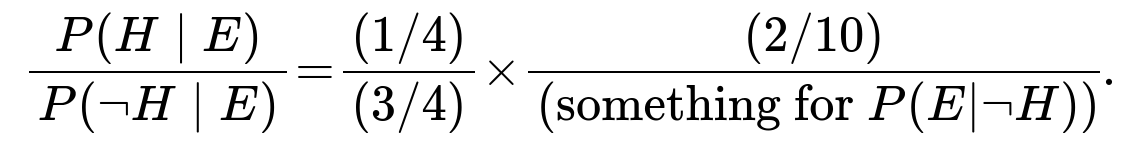
Potential Follow-up Questions
How would you verify these probabilities via simulation?
You can write a Python script to simulate many families and estimate these probabilities. Each family can be sampled as (Boy or Girl) for child1 and child2, then apply the appropriate naming rules. Tally the fraction of families meeting the “at least one Mary Ann” condition that also have two girls. Code outline:
import random
def simulate_dictators_rule(num_families=10_000_000):
two_girls_count = 0
has_maryann_count = 0
both_and_maryann_count = 0
for _ in range(num_families):
# Each child equally likely B or G
children = [random.choice(['B','G']), random.choice(['B','G'])]
if children.count('G') == 2:
two_girls_count += 1
# under dictator's rule, first girl is Mary Ann => definitely Mary Ann present
has_maryann_count += 1
both_and_maryann_count += 1
else:
# could be 0 or 1 girl
if children.count('G') == 1:
# that single girl is forced to be Mary Ann
has_maryann_count += 1
return both_and_maryann_count / has_maryann_count
def simulate_random_rule(num_families=10_000_000):
# 10 possible names, one is Mary Ann
names = [i for i in range(10)] # treat '0' as Mary Ann for convenience
two_girls_count = 0
has_maryann_count = 0
both_and_maryann_count = 0
for _ in range(num_families):
child1 = random.choice(['B','G'])
child2 = random.choice(['B','G'])
# naming
if child1 == 'G' and child2 == 'G':
two_girls_count += 1
# name the first girl from 10
name1 = random.choice(names)
# name the second girl from the 9 remaining
names_remaining = [n for n in names if n != name1]
name2 = random.choice(names_remaining)
# check if either is Mary Ann
if name1 == 0 or name2 == 0:
has_maryann_count += 1
both_and_maryann_count += 1
elif child1 == 'G' and child2 == 'B':
# first girl
name1 = random.choice(names)
if name1 == 0:
has_maryann_count += 1
elif child1 == 'B' and child2 == 'G':
# the second child is actually the first girl in the family
name2 = random.choice(names)
if name2 == 0:
has_maryann_count += 1
# else (B,B): no girls => no Mary Ann
return both_and_maryann_count / has_maryann_count if has_maryann_count else 0
prob1 = simulate_dictators_rule()
prob2 = simulate_random_rule()
print("Estimated prob with dictator's rule:", prob1)
print("Estimated prob with random naming rule:", prob2)
These estimates will converge near 1/3 for the first scenario and near 1/2 for the second scenario.
Could there be any edge cases or assumptions that change these probabilities?
One subtlety is that we assume:
Each child is independently a boy or girl with probability 1/2.
The naming rules are perfectly followed.
We do not consider families with more than two children.
“You are told the family has a Mary Ann” is interpreted as “this is a piece of unconditional information that at least one child in that family is specifically named Mary Ann.”
If we changed the order in which you receive the information (e.g., you encounter a girl who says her name is Mary Ann, and you discover she is the older child), or if we consider misnaming or incomplete data, these probabilities might shift. But as stated, everything is consistent with the idealized scenario.
Is it always valid to ignore the families with two boys in the Bayesian conditioning on “has Mary Ann”?
Yes. Those families can never have a girl named Mary Ann, so in the conditional probability space restricted to “families with Mary Ann,” the (B,B) families simply do not appear. This is standard in a conditional probability approach. Yet we still must account for how the prior odds shift once we exclude that portion of families from consideration.
Does the presence of ‘no same names for siblings’ matter if the family has only one girl?
In the first scenario, it does not matter because that single girl is always Mary Ann. In the second scenario, it only matters if there are two girls, because then the second girl’s name cannot be the same as the first girl’s name. If a family has just one girl, the “no repeated names” constraint is irrelevant. This constraint mainly explains why, in the second scenario, the second girl cannot also be Mary Ann if the first one is, and that affects the calculation of P(E|H).
These considerations ensure the probability expressions are consistent with the scenario details.
Below are additional follow-up questions
What if the families are allowed to have more than two children?
In the scenario described, each family has exactly two children. However, one might wonder how the analysis would change if families could have 1, 2, 3, or more children (under the same naming constraints). The core idea is that the event H (“the family has two girls”) would be replaced by something like “the family has at least two girls,” or “the family has exactly two children, both of whom are girls.” This fundamentally changes the sample space.
Pitfall: If we are not careful about how many children exist in total, we might incorrectly condition on families that have multiple daughters and name them differently.
Edge Case: If the rule still holds that the first girl (of potentially many) must be named Mary Ann (or is randomly chosen from a set of names), then the probability of “seeing” Mary Ann in a family depends on how many girls there are in total. Having more girls can increase the chance of encountering Mary Ann if the naming is random, because each girl is a new opportunity for that name to appear—unless the rule prohibits name duplicates, in which case only one girl can ever have that name.
Detailed Reasoning: You would need to construct the new list of possible family structures (up to the maximum number of children) and then consider which of those children end up with the name Mary Ann according to the relevant naming rules. The prior probabilities of each structure (number of children, gender distribution) must also be specified. This drastically complicates the problem but conceptually it is just a larger enumeration or a more complex Bayesian conditioning.
What if having a boy or a girl is not equally likely?
The original problem assumes that each child has a 50-50 chance of being a boy or a girl. But real-world data often shows that the probability of a boy vs. girl might deviate slightly from 0.5.
Pitfall: If the probability of a girl is p (not necessarily 0.5), then the prior probability of having two girls is p * p = p², and having exactly one girl is 2 p(1 – p).
Impact on the Posterior: The Bayes’ Theorem setup remains the same, but P(H) and P(¬H) must be recomputed accordingly:
P(H) = p²
P(¬H) = 1 – p²
Likelihood Computations: For the dictator’s rule, if you learn “there is at least one Mary Ann,” the ways that can happen still follow the forced naming approach, but the relative weights of the G-G, G-B, and B-G families change because p might not be 0.5. You must properly adjust all probabilities in your calculation.
Edge Case: If p is very small or very large, you might find surprising results—for example, if p is extremely small (nearly 0), the chance of encountering Mary Ann at all becomes quite low.
What if families can choose to stop having children once they have a girl?
Sometimes, sociological factors lead to “stopping rules,” where families keep having children until they have a boy (or a girl). If we artificially mimic that scenario in a two-child world, it might change the distribution of the sexes across families.
Pitfall: The entire problem’s assumption about each child being an independent event might no longer hold, because there is a structural correlation: once a certain gender is achieved, parents might not have another child.
Detailed Reasoning: If there is a rule like “Stop having children once we get a girl,” then in a two-child maximum scenario, you see that families that have a girl in the first child might not have a second child at all, or if they do, the distribution is different than the naive 50-50 assumption. Learning about Mary Ann in that environment dramatically shifts posterior odds.
Edge Case: If they are forced to have exactly two children but also prefer that the naming rule only applies to the first girl, you would still keep the same combinatorial logic, but the real pitfall is mixing real stopping rules with a forced 2-child maximum.
How does “You meet a girl named Mary Ann” differ from “You learn that the family has a girl named Mary Ann”?
A subtle difference in Bayesian problems is how you encounter the information “there is a Mary Ann.” Do you randomly sample a child and discover she is Mary Ann, or do you just hear from some external source that “the family has a Mary Ann”?
Pitfall: If you specifically meet a girl and learn her name is Mary Ann, then you have also discovered that the child you met is a girl. That can alter the probabilities relative to hearing “the family has a Mary Ann” in a more general sense. This is related to the “boy or girl paradox” type of reasoning, where the reference class of families changes depending on how you learn the information.
Edge Case: If the scenario is “You see a girl named Mary Ann playing in the playground, and then find out she belongs to some family. What is the probability that the family has two girls?” the solution might not be the same as if your friend just told you “there is at least one girl in that family named Mary Ann,” without specifying how that information was obtained.
What if Mary Ann is only possible as a name for the older girl?
Another twist might be if the naming rule is not symmetrical for first and second daughter, but specifically states that only the eldest girl (by birth order) can bear the name Mary Ann, while the second or younger girl cannot.
Pitfall: In that scenario, if you observe “the family has a Mary Ann,” you are actually also learning that the girl named Mary Ann is the older sibling. That effectively cuts out certain possibilities. For example, you cannot have a younger daughter named Mary Ann if the older daughter is also named Mary Ann.
Detailed Reasoning: In the original problem, the dictatorship scenario is effectively “the first girl is forced to have that name,” so that is somewhat akin to “only the eldest girl can have it.” But if we slightly alter the constraints (maybe the older daughter can choose Mary Ann from a pool of names, but the younger cannot), we end up with different enumerations. The posterior probability changes when you condition on the existence of “Mary Ann” if that name is exclusively reserved for the older daughter.
How do mistakes or spelling variants in the name (e.g. “Mary Ann,” “Marian,” “Mary-Ann”) affect the calculation?
In real-life scenarios, multiple name variants might occur. For instance, some parents might pick “Mary Anne” or “Marian,” while the rule still aims to name the first daughter “Mary Ann” exactly.
Pitfall: If the observer can confound “Mary Ann” with “Mary Anne,” you might incorrectly group families that do not strictly follow the naming rule. That changes the probability of E.
Edge Case: If the chance of a family misspelling or altering “Mary Ann” is small but nonzero, it complicates the event E: is E “there is a girl who claims her name is Mary Ann,” or “there is a girl whose name is spelled exactly Mary Ann?” Each subtle difference modifies the relevant likelihoods.
Detailed Reasoning: To handle this, you would expand the probability P(E|H) and P(E|¬H) to account for the possibility that the “Mary Ann” name was either assigned or incorrectly spelled. The Bayesian formula is the same, but your likelihood terms become more complicated, mixing in the probability of correct or incorrect naming.
Does the number of available names (10 in the second scenario) significantly affect how the posterior is derived if it is much larger or smaller?
One might wonder: “We used 10 possible names. But what if there are 100 possible names? Does that shift the resulting ratio to something else?”
Pitfall: If the naming pool size changes, the probability of at least one girl being Mary Ann in a two-girl family changes, because you have more “draws” from that bigger set. With 100 names, the chance that at least one child ends up named Mary Ann might be quite different from the 10-name scenario.
Detailed Reasoning: Suppose the naming process is “first girl picks from M possible names, second girl picks from the remaining M – 1.” Then for a family with two girls, the probability that at least one ends up Mary Ann is 1/M + (M – 1)/M * 1/(M – 1) = 1/M + 1/M = 2/M. For a single-girl family, the probability she is Mary Ann is 1/M. The final posterior probability will adjust accordingly:
P(H|E) = [ (1/4)(2/M ) ] / [ (1/4)(2/M ) + (3/4)(1/M)(proportion of single-girl families) ] and you would refine that proportion carefully based on your sampling approach. As M grows, 2/M becomes small but so does 1/M, so the interplay can be quite interesting.
How would the result change if two siblings can share the same name?
The second scenario assumes two siblings cannot share the same name, so if the first girl got Mary Ann, the second girl could not also be Mary Ann. If that restriction is relaxed, then it might be possible for both daughters to be named Mary Ann.
Pitfall: If the naming set is large but you allow repetition of names, then the probability that “Mary Ann” appears among the siblings changes. In a two-girl family, you could have either zero, one, or even two Mary Anns.
Detailed Reasoning: For the second scenario with random selection from 10 possible names but allowing duplicates, the probability of at least one Mary Ann with two girls becomes 1 – (9/10)*(9/10) = 19/100. Compared to 2/10 = 1/5 when names cannot repeat, 19/100 = 0.19 is slightly less than 0.20. That minor difference shifts the posterior a bit. You would then plug 19/100 in place of 2/10 in your Bayesian formula. This might produce a slightly different posterior probability than 1/2.
What if the question is “What is the probability that the girl named Mary Ann has a sister who is also a girl?” rather than “What is the probability that the family has two girls?”
This is a subtle re-interpretation. Instead of asking about the entire family having two girls, we might focus on the status of the sibling of the known Mary Ann. This perspective can alter the approach:
Pitfall: The subtlety is that “Given we met or heard about a particular child named Mary Ann, what is the probability that this specific child’s sibling is female?” is slightly different from “Given that at least one child in the family is Mary Ann, what is the probability that the family has two girls?” Usually they coincide, but in some versions of the “boy or girl paradox,” those details matter (e.g., older vs. younger child).
Detailed Reasoning: If we know only that a family has a Mary Ann, we do not necessarily know if the Mary Ann is the older or younger child (unless that is also stated). The posterior can be different if you specifically identify “the Mary Ann we are referencing is the older child.” That extra detail eliminates certain permutations in your sample space. Hence, you must be explicit about which child is being referenced and how you came to that information.