
ML Interview Q Series: Calculating Expected Loops in Random Noodle Tying via Probability Recurrence.

Browse all the Probability Interview Questions here.
Suppose you have 100 noodles in a bowl, where each noodle has two free ends. In each step, you randomly pick two of the available ends and tie them together. This process can produce loops. When all ends have been tied, on average, how many loops do you expect to form?



If you form a loop, the total noodle count does not strictly change, but effectively, you remove that noodle from contributing further loose ends. If you do not form a loop, you reduce the number of noodles from n to n−1 by tying two different noodles together into a single combined piece (thus there is one less “free piece” overall).

Putting these together:




Potential Implementation in Code
def expected_loops(num_noodles=100):
import math
# sum of reciprocals of odd denominators up to 2*num_noodles - 1
total = 0.0
for odd in range(1, 2*num_noodles, 2):
total += 1.0 / odd
return total
print(expected_loops(100)) # This should give a result around 3.3
Common Pitfalls and Edge Cases

Follow Up Question 1
How would the expected number of loops change if, instead of randomly selecting any two free ends, we always tried to avoid tying two ends of the same noodle unless forced?
If you purposely avoid forming loops until you have no choice (for instance, if you aim to choose ends from different noodles whenever possible), you would reduce the probability of creating loops early in the process. However, once there are only ends belonging to the same noodle left, you have no choice but to tie those. Despite this strategy, the tricky point is that the expected count of loops at the end cannot be lowered below the same expected value under purely random tying. This is a surprising phenomenon: the expected number of loops is actually invariant under any non-adaptive or adaptive strategy of end selection (in scenarios where all choices are equally available at each step). An intuitive explanation is that every tie effectively reduces the count of “pieces” by one, and each piece has a certain chance of eventually forming its own loop. Detailed proofs employ linearity of expectation and do not rely on random selection alone. In short, the expectation remains the same regardless of the strategy, so it would still be around 3.3 for 100 noodles.
Follow Up Question 2
What is the distribution (not just the expectation) of the number of loops formed?
The exact distribution is more involved than the expectation. One can analyze the number of loops by considering each tie as a random choice creating or not creating a loop, but outcomes are correlated across steps. Generally, a known result is that if you tie all ends in a purely random manner, the final number of loops has a distribution related to permutations with random cycles (there is a link to the concept of random matchings and their cycle structure). The probability that you end up with k loops is somewhat analogous to asking how many cycles a random permutation might have, although you would need a more rigorous combinatorial mapping. The distribution is not trivial, but the mean and variance can be studied via combinatorial arguments or generating functions. The key takeaway in interviews: the expected value is simpler to derive, while the full probability distribution requires deeper enumerations or advanced probabilistic arguments.

Follow Up Question 4
What is the intuition behind the sum of odd reciprocals?
One way to see this pattern is to notice that each time you tie ends, you reduce the number of “active pieces” by exactly one—whether you formed a loop or merged two noodles. In expectation, each such reduction carries a 1/(2n−1) chance of being a loop creation (when n is the current number of pieces). Summing these probabilities across all steps from n down to 1 leads to the sum of reciprocals. In other words, each step has a small chance to create a loop, and over many steps, the total expected loops is the sum of those small chances.
Follow Up Question 5
How can we verify this result empirically with a simulation?
You can simulate the tying process multiple times and track the number of loops formed:
import random
def simulate_tying(num_noodles=100, trials=10_000):
import math
results = []
for _ in range(trials):
# Represent each noodle's ends as distinct 'end IDs'
ends = list(range(2 * num_noodles))
random.shuffle(ends)
# A mapping from end ID to the noodle index it belongs to:
noodle_id = [i for i in range(num_noodles) for _ in range(2)]
loops_formed = 0
# We'll keep track of which 'merged noodle' each end belongs to
# so we can detect if two ends belong to the same piece
parent = list(range(2 * num_noodles)) # Union-Find or simple approach
def find(x):
while parent[x] != x:
parent[x] = parent[parent[x]]
x = parent[x]
return x
# Randomly tie pairs until no ends remain
free_ends = list(range(2*num_noodles))
random.shuffle(free_ends)
while len(free_ends) > 1:
# Pick two ends
e1 = free_ends.pop()
e2 = free_ends.pop()
# Check if they belong to the same piece
root1, root2 = find(e1), find(e2)
if root1 == root2:
# We formed a loop
loops_formed += 1
else:
# Merge the two pieces
parent[root2] = root1
results.append(loops_formed)
return sum(results) / len(results)
print(simulate_tying(100, 10000))
If you run this simulation, you should observe an average value close to 3.3, confirming the theoretical result.
Below are additional follow-up questions
1) How does this model behave if each tie operation happens in a continuous-time process, and we want the expected number of loops at some intermediate stage?
When transferring the discrete steps of picking ends and tying them into a continuous-time setting, one approach is to imagine a clock ticking and at each “tick” a random pair of ends is chosen to be tied (provided there are still free ends). If we pause at some intermediate time, some subset of the ties may be completed, and some ends remain free. In this partial-tying scenario, you effectively have a mixture of “fully tied components” and “still free ends.”

Subtlety: The exact stage at which you stop (and how many tie steps have been completed) matters. If, for example, you only complete m tie operations (out of the total 2n−1 possible merges), you can view the expected loops after m merges as a partial sum of the same series. Specifically, if m merges have occurred, the system has gone from n pieces to n−m pieces, so you sum the loop probabilities from n down to (n−m+1) in that stage-by-stage manner.
Potential Pitfall: It can be tempting to assume the expectation for a partially completed process is simply a scaled version of the final expectation (like “if we’re halfway done tying ends, we must have about half the loops”). This is not generally accurate because the probability of forming a loop is not constant per tie but depends on how many noodles remain.
2) What happens if noodles can break during the tying process, effectively increasing the number of free ends?
If a noodle breaks at some random point, that might split one noodle into two smaller “pieces,” each having its own ends.
Immediate Consequence: The total count of ends could increase beyond 2n. This introduces an additional random mechanism in which the number of pieces n could actually go up instead of monotonically decreasing.
Expected Loops Analysis: Once breaks are introduced, the straightforward recurrence no longer holds because n is no longer strictly decreasing with each tie. A break effectively adds an extra piece or more. If you treat breakage events as random, you’d need a modified recurrence or a stochastic differential equation approach (depending on how breakage is modeled).
Edge Cases: If breaks are very frequent, you might maintain a high number of pieces for a longer period, giving more opportunities for random pairs from the same piece to be selected. This can both raise or lower the expected loops, depending on how the broken pieces are distributed. A robust solution would likely involve simulating or deriving a new combinatorial model.



where γ is the Euler–Mascheroni constant. That means you can approximate the partial sum of odd reciprocals by re-expressing it in terms of harmonic numbers:
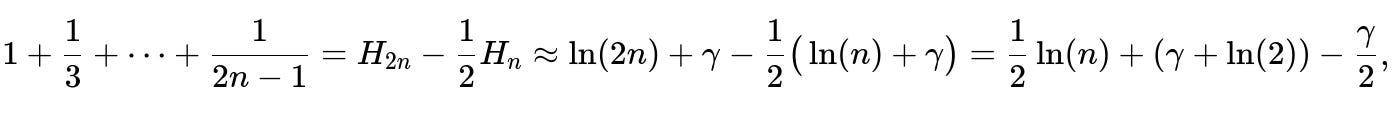

4) Could this process be optimized using more sophisticated data structures for tracking merges and detecting loops?
Yes, if you were to implement a simulation or an algorithmic model:

Pitfalls:
If you implement naive “merge by array indexing” or linked lists, merging might take O(n) time per operation, which could be costly in large simulations.
If you fail to track parent relationships carefully, you can incorrectly double-count loops or fail to detect them.
Real-World Issue: In a high-performance setting (e.g., large-scale random processes, multi-threaded simulation), concurrency and synchronization might complicate the union-find usage. One must carefully manage locks or use lock-free structures.
5) In an extended scenario where noodles can be inserted (i.e., new noodles arriving over time), how do we adjust the expected loop count?
If new noodles arrive over time:

Possible Approach:
Each time a new noodle arrives, consider it as n→n+1. You can track an incremental update to your expected loop formula. But you have to incorporate the fact that some fraction of ends might already be tied. A thoroughly correct approach would likely require a more advanced Markov chain or a simulation-based approach.
6) Could the tying process lead to any real-world ambiguities if the “ends” are not clearly distinguishable?
In real scenarios (e.g., with physical ropes or noodles), “ends” could get tangled or partially fused, blurring the lines of distinct end selection:
Ambiguity: If ends stick together or become effectively indistinguishable, the probability calculation of choosing two distinct ends from the same piece might be incorrect because the sample space changes. You might not be choosing uniformly among 2n separate ends if some ends are lumped.
Practical Example: Suppose you have actual cooked noodles in a pot and some ends get stuck to each other. You might randomly pull two “ends” that turn out to be part of the same elongated cluster, even though it’s not purely one single noodle.
Statistical Adjustment: You’d need to redefine how you treat “choosing two ends at random.” If the ends are not all equally likely or some are fused, the model changes drastically. A new probability distribution for picking ends must be introduced, and the standard 1/(2n−1) loop probability breaks down.
7) What if, after forming each loop, you do not remove that loop from the bowl, so it might still be selected in further tie steps?
In the classical problem statement, once two ends of the same noodle are tied, those ends are removed from the pool, effectively meaning that noodle no longer contributes free ends (even though it physically remains in the bowl). But suppose you literally leave the loop inside the bowl, and do not track or remove the “used” ends from the random selection:
Immediate Contradiction: If you do not remove used ends from the set of “available ends,” you’d be double-counting ties or picking “ends” that are already tied. The process becomes ill-defined, because you have to decide how to handle ends that are no longer free.
Possible Interpretation: If a loop is still in the bowl, but you treat the newly formed loop ends as “glued” or “merged,” you would still not treat them as free ends. Hence, from a modeling perspective, you must effectively remove them from the random selection pool. Otherwise, the question becomes ambiguous: Are you forcibly untying loops to retie them? Or are you doubling up ties on the same ends?
Pitfall: Overlooking the distinction between physically removing the noodle from the container and removing its ends from the random draw might lead to an incorrect probability analysis.
8) Could the length of each noodle or the geometry of how they lie in the bowl affect the probability of selecting ends?
Yes, if you relax the assumption of uniformly random selection of free ends and incorporate geometry or length constraints:

Complex Random Fields: If we assume random positions of each end in a 2D or 3D space, we might attempt to model the process as a function of those positions, leading to potentially complicated spatial statistics. Some ends might cluster together, changing the distribution for loop formation.
Pitfall: Failing to verify the assumption of uniform random selection in a real physical setting can invalidate the original theoretical approach.
9) Do we always end up with at most n loops, or can we get more?
An intuitive boundary is that you cannot end up with more loops than the number of noodles you started with. Each loop requires tying both ends of at least one original noodle. Since no noodle has more than two ends, forming a loop of a single noodle is the maximum usage of that noodle in terms of loop creation.
Upper Bound: Indeed, the maximum loops is n because each noodle could, in principle, form its own loop if each noodle’s ends were tied to itself.
Lower Bound: The minimal number of loops is 1, which happens if all noodles get chained one after another into a single long loop.
Edge Case: If there were different types of strings (some with more than two ends) the upper bound might change, but for two-end noodles, n loops is the clear maximum.
10) How sensitive is the result to the assumption that each tie is equally likely among all pairs of free ends?
The entire derivation hinges on the uniform random selection of pairs among the 2n free ends. If there is any bias, the probability of creating loops early could shift:
Potential Variation: Suppose you have a partial preference for certain noodles or certain ends, or you systematically avoid pairs from the same noodle unless it’s the only option (beyond the earlier question of “purposely avoiding loops”). Or perhaps the random choice depends on physically pulling out an end from a random location in the bowl.
Sensitivity: Because the expected value was derived from linearity of expectation with a uniform probability for each pair, introducing any structured bias might lead to changes in each step’s loop probability, thereby altering the recurrence relation and ultimately changing the expected loop count. In practice, you would have to re-derive or simulate with the updated probabilities.

