
ML Interview Q Series: Calculating CNN Output Shape: Understanding Kernel Size, Strides, and Padding Effects.

📚 Browse the full ML Interview series here.
15. Suppose I have an image of shape (28, 28, 4) and apply a convolutional layer with 64 filters of kernel size (2, 3), strides = (1, 2). What is the output shape?
When given a 2D convolutional layer, we usually interpret the shape (28, 28, 4) as:
Height = 28
Width = 28
Channels = 4
The convolutional layer has 64 filters (sometimes also called output channels), each with a kernel size (2, 3). Strides = (1, 2) means the stride along the height is 1 and the stride along the width is 2. By default, if no padding is specified, many interview settings assume "valid" padding (i.e., no padding). The standard formula for the spatial output size for each dimension in a "valid" convolution is

Below is a step-by-step explanation of how to compute the height and width of the output:
Height Dimension
Input height = 28
Kernel height = 2
Stride in height = 1
No padding assumed
Applying the formula:
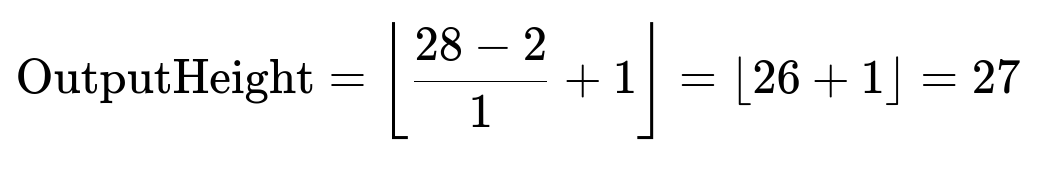
Width Dimension
Input width = 28
Kernel width = 3
Stride in width = 2
No padding assumed
Applying the formula:

Channels
The number of output channels is given by the number of filters in the convolutional layer, which is 64.
Hence, the final output feature map shape is:
Height = 27
Width = 13
Channels = 64
So the output shape is (27, 13, 64).
Follow-up: How do we verify this using an example implementation in Python?
We can demonstrate this in TensorFlow or PyTorch with a quick code snippet. For instance, in TensorFlow using a Conv2D layer:
import tensorflow as tf
# Create a random input tensor with shape (batch_size=1, height=28, width=28, channels=4)
# We'll use batch size = 1 for demonstration
x = tf.random.normal((1, 28, 28, 4))
# Define a Conv2D layer
conv_layer = tf.keras.layers.Conv2D(
filters=64,
kernel_size=(2, 3),
strides=(1, 2),
padding='valid'
)
# Pass the input through the layer
output = conv_layer(x)
print(output.shape) # Expected: (1, 27, 13, 64)
When you run this, output.shape would indeed show (1, 27, 13, 64), matching the shape analysis we did above (the batch dimension here is 1, which is often omitted when we just talk about the spatial and channel dimensions).
Follow-up: What if we used padding='same'?
If we changed the padding to 'same' in a framework like TensorFlow, the formula changes to:
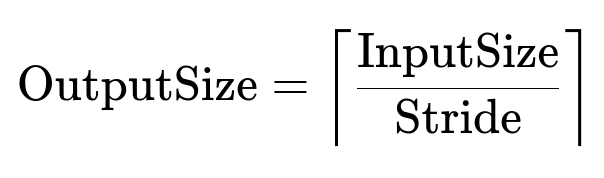
For stride = (1, 2) and kernel size = (2, 3), 'same' padding ensures that the output height and width remain scaled primarily by the stride rather than dropping by the kernel size. Specifically:
Height dimension: For stride 1 and input height 28, the output height remains 28 (or potentially 28 if the kernel size is 2, the framework might pad accordingly).
Width dimension: For stride 2 and input width 28, the output width is approximately the ceiling of 28/2 = 14. You might see 14 or a similar integer depending on exact rounding in the library implementation.
Thus, you would end up with (28, 14, 64) ignoring the batch dimension, if 'same' padding is used in TensorFlow with these settings. But the exact shape can also depend on how the framework specifically implements same-padding with even/odd shapes.
Follow-up: How does the input channel (4) factor into the calculation?
The input channel count (4) must match the expected input channels for each filter. In typical implementations of 2D convolution (e.g., TensorFlow Conv2D, PyTorch nn.Conv2d), the number of input channels must match the "in_channels" parameter in that convolution layer. For example, if you define a PyTorch convolution:
import torch
import torch.nn as nn
# Suppose we define a convolution layer with in_channels=4 and out_channels=64:
conv = nn.Conv2d(
in_channels=4,
out_channels=64,
kernel_size=(2, 3),
stride=(1, 2),
padding=0 # "valid"
)
# Create a random input (batch_size=1, in_channels=4, height=28, width=28)
x = torch.randn(1, 4, 28, 28)
out = conv(x)
print(out.shape)
Here, out.shape would be [1, 64, 27, 13] in PyTorch's channels-first convention (batch_size=1, out_channels=64, out_height=27, out_width=13). In frameworks with channels-last (like default TensorFlow), the input is (28, 28, 4). In PyTorch, you typically reorder the input to (4, 28, 28).
Follow-up: How do you handle edge cases if the output dimension is not an integer?
If the convolution formula gives a non-integer result, we take the floor for "valid" padding. As soon as the kernel no longer fits, we stop and ignore that partial region at the boundary. In frameworks like TensorFlow or PyTorch, if your stride does not divide the difference nicely, the floor operation effectively discards incomplete strides at the edge. This might slightly alter the final shape if your input dimension is not a clean multiple of the stride + kernel size.
For instance, if you had an input width of 29 (instead of 28), and you still used kernel width 3 and stride 2 with valid padding, the width calculation would be:

This is an example of how a single extra pixel in the input can produce a different output width.
Follow-up: What if we wanted to preserve the spatial resolution exactly?
To preserve the exact spatial resolution, you typically set your stride to 1 and use 'same' padding. In that case, the output dimension is the same as the input dimension for height and width (barring any rounding nuances with odd/even dimensions). This is a common practice in fully convolutional networks, or for certain layers in segmentation tasks to ensure the output feature map has the same spatial size as the input.
Follow-up: What would happen if we used a transposed convolution instead?
Transposed convolutions (sometimes called "deconvolutions" in certain contexts) invert the forward shape calculation of a standard convolution, effectively performing upsampling based on filter size and stride. Instead of shrinking the spatial dimension, transposed convolutions can expand it. The mathematics for the output size in a transposed convolution is slightly different (and includes considerations for output padding). In PyTorch, for instance, the output size for a transposed convolution can be computed by:
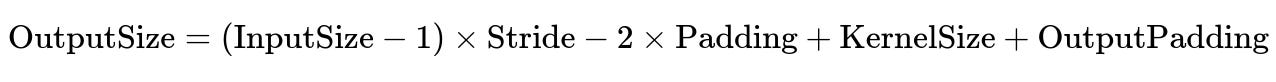
But that is a completely different scenario from the original question. It’s just important to remember that a "transposed convolution" is not exactly the inverse of a normal convolution, especially with partial strides and boundary effects—it just uses a similar operation with the geometry arranged to produce larger feature maps.
Follow-up: Are there any practical performance considerations with these hyperparameters?
Yes, several:
Stride > 1 along the width can reduce the computational cost by quickly downsampling the spatial dimension. On the other hand, it also discards information, so it might affect the representational capacity for tasks that require fine-grained detail.
Kernel size (2, 3) is smaller in one dimension than the other, which might be used if one dimension has different structure, such as in certain images or time-series data (e.g., a small 2D kernel for one dimension and a slightly larger kernel for another dimension).
Number of filters (64) can significantly impact memory usage and compute time, especially with larger input batches or bigger spatial dimensions. 64 is fairly standard in many baseline convolutional networks, but for bigger networks, you can see much larger numbers of filters.
Follow-up: Summary of the core reasoning
The input shape is (28, 28, 4).
A convolution with (kernel_height=2, kernel_width=3) and (stride_height=1, stride_width=2) with no padding leads to a new height of 27 and a new width of 13.
The number of output channels becomes 64, dictated by the number of filters.
So, the output shape is (27, 13, 64).
Below are additional follow-up questions
What if the kernel size is larger than one of the input dimensions?
When the kernel size exceeds the available dimension of the input (height or width), certain frameworks may return a feature map of size zero along that dimension if no valid configuration of strides and pads can accommodate at least one valid application of the kernel. In a "valid" padding scenario with no added pad, the kernel cannot slide along an axis if it doesn't fit even once. Depending on the specific framework and settings, this leads to:
Output height or width becoming zero if the kernel cannot fit along that dimension.
Potentially an error or a warning if the kernel size is so large that no valid convolution can be computed.
For instance, if we have an input with height 28, but our kernel’s height is 30, and we keep stride = 1, valid padding (no pad) means:

Frameworks typically interpret a negative or zero dimension as invalid, resulting in an output shape of zero in that dimension or raising an error. In practice, you usually choose kernel sizes significantly smaller than the input dimension (or use adequate padding) to avoid such issues.
Pitfall to watch out for:
If you accidentally set a kernel size bigger than your input dimension (e.g., in an automated hyperparameter search), your network might fail to train or skip entire layers.
How many learnable parameters are in this convolution layer?
In a typical 2D convolution with "in_channels" = 4 and "out_channels" (number of filters) = 64, each filter has the shape (kernel_height, kernel_width, in_channels). Mathematically, the total number of learnable weights for the kernels is:

Here, kernel_height = 2, kernel_width = 3, in_channels = 4, out_channels = 64. So:
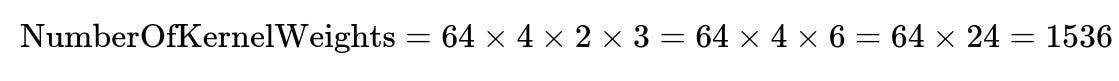
Additionally, each of the 64 filters has a bias parameter, so you add 64 more parameters:
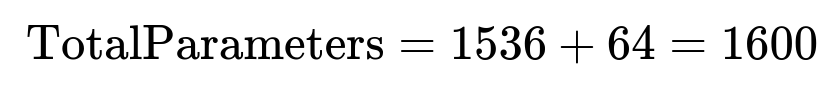
Hence, the total number of parameters in this convolutional layer is 1600.
Pitfall to watch out for:
Forgetting to account for the bias parameters when calculating total parameters. While some networks do not include biases (e.g., if you always follow with batch normalization), many standard layers do by default.
How does the layer handle an input with an odd spatial dimension, such as (29, 29, 4)?
When the input dimensions are odd, the convolution still follows the same formula for output shape. For "valid" padding, each spatial dimension in the output is computed using:

So for an input width of 29, a kernel width of 3, and a stride of 2:
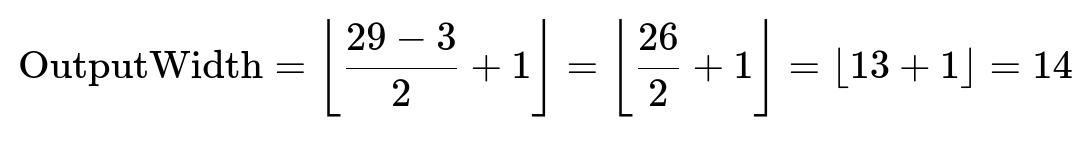
And for an input height of 29, a kernel height of 2, and a stride of 1:

So the resulting shape (ignoring the batch dimension) would be (28, 14, 64).
Pitfall to watch out for:
Off-by-one errors in the calculation, especially if your code or framework automatically adds padding or has different defaults than expected.
What about using dilated convolutions (atrous convolutions) with this layer?
Dilated convolutions increase the effective receptive field without increasing the kernel size, by introducing a spacing between kernel elements. The formula for the output shape often includes a factor for dilation. In many frameworks, a "dilation" parameter > 1 modifies how the kernel travels across the input. Instead of moving the kernel sequentially by stride steps, the kernel’s sampling points within each window are spaced out. For a given dimension:
If you let "d" be the dilation rate, then effectively your kernel size along that dimension is:

Then you plug this effective kernel size back into the standard formula. For example, if dilation = 2, and kernel_width = 3, the effective kernel width is:
3+(3−1)×(2−1)=3+2=5
Hence, you'd effectively be convolving with a width of 5. The rest of the shape calculation proceeds as normal, but you have to keep in mind that the convolution is sampling spaced-out locations. This can significantly increase the receptive field, which might be beneficial in tasks like semantic segmentation.
Pitfall to watch out for:
If you combine large dilation with large strides, you may skip too many pixel locations, leading to patchy coverage and potential information loss.
Some frameworks do not allow dilation in conjunction with certain paddings or strides without fallback to slower implementations.
How would the output shape be affected if the convolution was depthwise instead of standard convolution?
In a depthwise convolution, each input channel is convolved separately with its own filter, rather than mixing channels as in a standard convolution. If you do purely depthwise convolution (no pointwise convolution after), the number of output channels equals the number of input channels multiplied by any channel multiplier factor if specified. For example:
If the layer is a pure depthwise convolution with a depth multiplier = 1, the output channels stay at 4, not 64.
If there is a pointwise layer after the depthwise stage (as in a depthwise-separable convolution), you can then project from 4 to 64 channels.
Pitfall to watch out for:
Mistaking a standard "Conv2D(filters=64)" for a depthwise convolution. They are not the same. Depthwise convolution drastically reduces the number of parameters, but also changes how channels are processed.
How do batch size and hardware constraints influence the practical implementation?
Although batch size does not change the computed output shape (it just prepends a batch dimension), it affects:
Memory usage on the GPU or TPU. Higher batch sizes require more memory to hold intermediate activations.
Speed of training and inference. Large batch sizes leverage parallel processing better, but can lead to memory constraints.
Convergence behaviors. Extremely large batch sizes sometimes lead to different training dynamics and may need hyperparameter tuning for stable convergence.
Pitfall to watch out for:
If your GPU runs out of memory due to large batch sizes and a network with many 64-channel layers, you might have to reduce the batch size or reduce the number of filters or switch to mixed-precision training.
How do different activation functions impact the output shape?
Typically, activation functions (ReLU, Sigmoid, Tanh, etc.) do not alter the spatial or channel dimensions; they apply element-wise transformations. So whether you use ReLU or another activation, the shape (27, 13, 64) remains the same. However, the distribution of values in the output might be drastically different depending on the activation function.
Pitfall to watch out for:
Sometimes confusion arises about “layer shape” vs. “layer activation.” The shape is determined by the convolution parameters (kernel size, stride, padding, etc.), not by the activation function.
What if the input has alpha channel data (e.g., RGBA with 4 channels) and we only want RGB?
When an image has 4 channels, typically the fourth channel is the alpha channel. If a model expects only 3 channels (RGB), you might do one of the following:
Discard or ignore the alpha channel prior to feeding the input to the model, effectively switching your input to shape (28, 28, 3).
Incorporate the alpha channel as an additional input feature if you want the network to learn from alpha transparency information.
Pitfall to watch out for:
Mismatch between the channel dimension in the model and the data can cause runtime errors. For instance, if your model’s first convolution expects in_channels=3 but you feed in 4 channels, you get a shape mismatch error.
How does channels-first (NCHW) vs channels-last (NHWC) ordering impact the shape interpretation?
In channels-first (often used by PyTorch), the shape is (batch_size, channels, height, width). So an input might be (N, 4, 28, 28), and a convolution’s output might be (N, 64, 27, 13).
In channels-last (common in TensorFlow), the shape is (batch_size, height, width, channels), so an input might be (N, 28, 28, 4), and the output might be (N, 27, 13, 64).
Pitfall to watch out for:
Mixing these conventions inadvertently. If you feed an array with shape (28, 28, 4) into a PyTorch layer that expects (channels, height, width), you’ll see incorrect shapes or dimension mismatch errors.
What if we want the convolution to operate on each of the 4 channels independently like separate grayscale images?
That would be akin to a depthwise convolution with no channel mixing. If you did a standard convolution with out_channels=64, you get a mix of weights across all 4 input channels. If the requirement is "operate each channel as separate input," you’d typically set groups=4 in PyTorch (grouped convolution) or use a depthwise convolution approach:
import torch
import torch.nn as nn
# 4 input channels, 4 groups => each channel is treated as a separate group
conv_depthwise = nn.Conv2d(
in_channels=4,
out_channels=4,
kernel_size=(2,3),
stride=(1,2),
groups=4,
bias=True
)
Then each output channel corresponds to exactly one input channel’s convolution. If you want 64 total output channels but keep the grouping idea, you can set out_channels=4*g. For instance, with groups=4, you can produce 64 output channels only if 64 is divisible by 4, meaning each input channel expands to 16 filters. The shape still would be (27, 13, 64), but how those 64 channels are computed changes drastically.
Pitfall to watch out for:
Not understanding that grouped or depthwise convolution changes how parameters are shared or not shared across channels, leading to drastically different modeling capacities.
Could the convolution’s output ever become negative in size if the stride is too large?
Yes. If you have a small input dimension, a large kernel size, large stride, and no padding, you can end up with:

This usually indicates that the kernel can’t slide even once. Some frameworks immediately raise an error. Others may produce a zero or negative dimension, resulting in an invalid or empty output. For example, if your input width is 4 and kernel width is 3, but stride width is 3 with no padding:
That still works. But if the stride is 4:
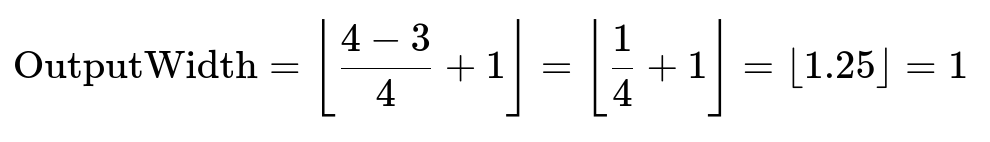
So that still works. But if the kernel was bigger, e.g., 5, you get:

Hence, an output width of 0, which means effectively no valid convolution region.
Pitfall to watch out for:
Large stride combined with large kernel can inadvertently reduce your spatial dimensions to zero or near zero.
Does zero padding (padding='valid') mean absolutely no padding in all frameworks?
Yes, in most deep learning frameworks, "valid" means no padding. But note that sometimes “valid” padding might still apply minimal internal constraints if you set special parameters. Typically though, "valid" strictly means convolving only over locations where the kernel fully fits in the input.
Pitfall to watch out for:
Confusing "valid" with "same." "Same" attempts to pad so that the output height and width match the input (when stride=1), whereas "valid" discards any partial overlap at the boundaries.
What if we wanted to incorporate a global pooling after the convolution?
If you apply global average pooling (GAP) or global max pooling after a convolution, you reduce each channel’s spatial dimension to a single scalar by averaging or taking the maximum across all spatial locations. For an output shape of (27, 13, 64), applying global average pooling yields a shape of (64) per batch example (assuming channels-last, that would be (1, 64) if including a batch dimension). This drastically reduces the dimensionality and is often used at the end of classification networks.
Pitfall to watch out for:
If your network requires more spatial resolution for subsequent operations (like fully connected layers that expect a certain dimension), global pooling may collapse that too early.
How do precision (e.g., float16, int8) or quantization methods affect the output shape?
The shape typically remains unchanged by using different numerical precisions or quantization approaches. Convolution with float16 (half precision) or int8 quantized weights still yields the same spatial dimension and channel count. The difference is how the data is stored and computed internally:
Reduced precision can speed up computations and lower memory requirements on hardware that supports fast half-precision or int8 ops.
The final numerical results or training dynamics might differ slightly due to rounding and quantization errors.
Pitfall to watch out for:
Aggressive quantization can degrade model accuracy if not carefully calibrated. But the shape remains the same.
Could we run into boundary effects for smaller batches, such as batch size = 1?
Batch size does not affect the spatial dimension, so you still get (27, 13, 64). However, having a very small batch size in training can lead to high variance in gradient updates. The shape of each individual output remains unaffected, but the stability of training might be reduced. Also, certain layers like batch normalization can have issues if the batch dimension is extremely small, as their statistics might be poorly estimated.
Pitfall to watch out for:
Overfitting or unstable training with extremely small batch sizes, especially if batch normalization is used.
Could we fuse this convolution with the subsequent activation or batch normalization for performance?
Yes, many frameworks or inference-optimized runtimes can fuse operations like convolution + ReLU or convolution + batch normalization + ReLU into a single kernel to speed up inference. This does not change the output shape but can improve runtime performance.
Pitfall to watch out for:
Fusing might complicate debugging or introspection, because intermediate outputs (e.g., pre-activation values) are no longer explicitly computed. However, the final shape remains identical.
What if we want to upsample right after this layer to get back the original spatial size?
If you apply an upsampling operation (e.g., nearest-neighbor, bilinear interpolation) or a transposed convolution with stride=2 in the width dimension, you can attempt to restore the spatial resolution to (28, 28) or something similar. For instance, if your width dimension is now 13 after the convolution, and you want to get back to 28, you might do an upsampling factor of 2, though 13 × 2 = 26, which is not exactly 28. You might do a custom scale factor or a carefully designed transposed convolution to get exactly 28.
Pitfall to watch out for:
Mismatch in dimensions if the upsampling factor times the new dimension does not match the original dimension. You might end up with an off-by-one or off-by-two difference.
If the stride was (1, 2) but we only wanted to reduce the width dimension, why didn’t we set stride=(1,1) for the height?
We did set stride=1 for height (the first element of the stride tuple is 1 for height). That means the height dimension is convolved at every possible spatial step, while the width dimension is convolved every 2 steps, effectively halving the resolution along width. This is a design choice often used in networks that want to preserve detail along height but reduce dimension along width more aggressively.
Pitfall to watch out for:
Potential distortion of aspect ratio if you repeatedly reduce one dimension and not the other. In some tasks, this might or might not be desirable.
Why do some frameworks require specifying padding explicitly, even if we say "valid"?
Some frameworks (like older versions of certain deep learning libraries) might require an integer or tuple for padding, even if you want zero padding. If you pass "valid," it might internally set "padding=0." For more advanced uses (like "same" or custom padding), you must specify the exact sizes.
Pitfall to watch out for:
Mismatch between your mental model of "valid" or "same" and the actual zero or non-zero padding the framework applies. Always verify the final shape in code.
If we do multi-GPU training, does it affect the output shape?
Not in terms of each sample’s per-GPU output shape. Multi-GPU training typically splits the batch among GPUs, but every GPU processes smaller subsets of the data with the same model. Each GPU’s local mini-batch generates the same output shape. The global batch is aggregated across GPUs, so your overall training shape logic remains consistent.
Pitfall to watch out for:
Implementation details with data parallel or model parallel strategies might require dimension changes for splitting data or splitting the model. But for a straightforward data parallel scenario, the shape per sample remains the same.
How do we handle shaped constraints in skip connections or residual blocks?
If we are implementing a skip connection from an earlier layer of size (28,28,4) to a later layer of size (27,13,64), we can’t directly add or concatenate these feature maps because their spatial dimensions and channels differ. Typically, we either:
Apply appropriate downsampling (pooling or strided convolution) on the skip path to match the shape of (27,13,4), then possibly project channels from 4 to 64 with a 1×1 convolution.
Or rearrange the main path so that the shapes match the skip path, possibly removing the stride or using partial strides.
Pitfall to watch out for:
If you attempt to do a naive addition between (28,28,4) and (27,13,64), you get dimension mismatch errors. Residual blocks usually require carefully matching dimension or using a projection layer.
How might kernel regularization or weight decay impact the layer’s behavior?
Regularization (L2 weight decay, for instance) doesn’t change the shape or parameter count but influences how the weights are updated during training. If you apply strong regularization, it might push the filter weights towards smaller magnitudes, potentially impacting representational capacity. The output shape remains the same, though.
Pitfall to watch out for:
Over-regularizing to the point that all filters have negligible weights, harming performance, but not changing the shape.
Could we accidentally create a bottleneck if we reduce width drastically but keep stride=1 for height?
Yes. If the network’s next layers expect a certain ratio of height-to-width or if the task demands wide field-of-view along the horizontal axis, halving the width dimension at this stage might hamper performance on tasks requiring horizontal context. This design choice must align with domain considerations.
Pitfall to watch out for:
Suboptimal dimension reductions that degrade performance in tasks like object detection where wide objects need high resolution across the horizontal dimension.
In practical data pipelines, might we reorder the input dimensions at preprocessing to keep everything consistent?
Yes, you often see data pipelines that explicitly transpose images from (height, width, channels) to (channels, height, width) if a framework expects channels-first. Or you might ensure that all augmentations produce (batch_size, height, width, channels) if your framework is TensorFlow and defaults to channels-last.
Pitfall to watch out for:
Data augmentation libraries might output different dimension orders if not configured carefully. This leads to shape mismatches or unexpected layer errors once training starts.
How could we systematically confirm the shape for complicated combinations of kernels, strides, dilations, and paddings?
Use a small script or snippet in your chosen framework (PyTorch/TensorFlow) with randomly generated input data. Print out the shape after each layer. For example:
import torch
import torch.nn as nn
x = torch.randn(1, 4, 28, 28) # batch=1, channels=4, height=28, width=28
conv = nn.Conv2d(
in_channels=4,
out_channels=64,
kernel_size=(2, 3),
stride=(1, 2),
padding=0, # valid
dilation=1
)
out = conv(x)
print("Output shape:", out.shape) # Expect [1, 64, 27, 13]
This direct check is often the best way to confirm your theoretical calculations.
Pitfall to watch out for:
Relying solely on theory and forgetting to validate with actual code. Implementation details or library-specific quirks can lead to unexpected shapes.
How important is it to memorize the convolution shape formulas?
While memorizing the shape formula is helpful, the conceptual understanding of how kernel size, stride, and padding interact to determine the output dimension is more crucial. Many engineers rely on rules of thumb or code checks. But in interviews, demonstrating you know the formula or can derive the result is a strong indicator of solid fundamentals.
Pitfall to watch out for:
Rote memorization without understanding. In real-world debugging, you need to reason about why your shape is off by a certain number, not just recite a formula.
How do we incorporate these details into larger architectures like Fully Convolutional Networks (FCN) or U-Net?
In FCNs or U-Nets:
The exact output shape at each stage is vital for skip connections (U-Net) or upsampling (FCN).
Each downsampling step typically halves the spatial resolution if stride=2, until the network bottleneck is reached.
Then, upsampling steps restore the resolution. If you mismatch these shapes, the skip connections won't align.
Pitfall to watch out for:
Wrong stride or kernel size at one step can ripple through the entire architecture, causing mismatch in skip connections or in the final output resolution.
Could we do a convolution that only modifies the channel dimension but leaves height and width the same?
Yes, by setting kernel size = (1,1), stride=(1,1), and padding=0. This is sometimes called a pointwise convolution. That operation changes only the channel dimension (e.g., from 4 input channels to 64 output channels), while preserving height and width.
Pitfall to watch out for:
Not realizing that a "1×1" convolution is a powerful operation for mixing channels, but it does not alter spatial size unless there's padding or other operations.
In summary, how do these considerations map back to the original shape question?
The original question about the output shape (27, 13, 64) is straightforward when you apply the standard convolution formulas with kernel size (2,3), stride=(1,2), and no padding to an input (28,28,4).
The follow-up details highlight how real-world scenarios (like odd input sizes, grouping, dilation, depthwise, alpha channels, batch norms, skip connections, etc.) can influence or complicate the shape calculation or the network design.
Always verify shapes in practice if in doubt, and remember the formula is a guide, but implementation specifics can create minor or major deviations if you add advanced features or different types of padding.