
ML Interview Q Series: Calculating the Two-Child Probability Puzzle using Conditional Probability and Sample Spaces.

Browse all the Probability Interview Questions here.
Suppose a couple has two children, and you learn that at least one of them is a boy. What is the probability that the other child is also a boy?
Short Compact solution
Let "B" denote a boy, and "G" denote a girl. The complete set of outcomes for two children is BB, BG, GB, GG, assuming each gender is equally likely for each child. If you already know one child is a boy, the GG case (both girls) is ruled out. That leaves BB, BG, and GB as equally likely possibilities. In only one of these three cases is the other child also a boy (the BB case). Therefore, the probability is

Comprehensive Explanation
Reasoning About the Sample Space
When analyzing the probability of an event, it often helps to list all possible outcomes in the sample space. For two children, the possible gender combinations (assuming independence and equal probability of boy or girl) are:
ParseError: KaTeX parse error: Can't use function '$' in math mode at position 14: \text{(B, B)}$̲$: first child …
ParseError: KaTeX parse error: Can't use function '$' in math mode at position 14: \text{(G, B)}$̲$: first child …
Each outcome, under a simplistic assumption that the chance of any child being a boy is
0.5
and the chance of any child being a girl is
0.5
, has probability
0.25
.
Now, because we are told at least one is a boy, any scenario in which both children are girls is impossible. Thus, the revised set of equally likely outcomes shrinks to:
(B, B)
(B, G)
(G, B)
Since only in one of these three (B, B) are both children boys, the probability is

Common Intuition Pitfalls
A frequent mistake is to narrow the sample space incorrectly to assume the probability is

. That often happens when someone immediately thinks: “We already know one is a boy, so the other child has a 50% chance of being a boy.” However, by ignoring the specific positions and counting BG and GB as the same scenario, the different positions of the boy can be overlooked. BG and GB are distinct outcomes in this problem because it matters which child is identified as the boy (e.g., older vs. younger).
Simulation Approach
To build deeper intuition, consider a quick Python simulation to empirically check the probability. We can generate many pairs of children, filter to those pairs containing at least one boy, and see how many times both children are boys:
import random
def simulate(num_trials=10_000_000):
count_at_least_one_boy = 0
count_both_boys = 0
for _ in range(num_trials):
child1 = random.choice(['B', 'G'])
child2 = random.choice(['B', 'G'])
if 'B' in [child1, child2]: # at least one boy
count_at_least_one_boy += 1
if child1 == 'B' and child2 == 'B':
count_both_boys += 1
return count_both_boys / count_at_least_one_boy
prob_estimate = simulate()
print(prob_estimate)
You would see a result close to 0.333..., supporting the

theoretical answer.
If the Known Boy is Specified (Older or Younger)
Sometimes, the puzzle is framed slightly differently, for example: “If you know the older child is a boy, what is the probability that both children are boys?” In that version, you remove any scenario in which the older child is a girl. The reduced space is then only two equally likely outcomes: (B, B) and (B, G). Out of these two, (B, B) is the only case with both children as boys, making the probability

Notice the difference between knowing “one child is a boy” (not specifying which child) versus “the older child is a boy.” The more specific your information is, the more it constrains the sample space in a particular way.
Follow-up Question: Is the Probability Affected by Extra Details Like Birthdays or the Day of the Week?
In a more advanced variant—sometimes called the Boy-or-Girl paradox—people might say: “You meet a man who says he has two children, and at least one is a boy born on a Tuesday. What’s the probability the other child is also a boy?” If you incorporate the extra detail of “born on a Tuesday,” you must expand the sample space to reflect each child’s day of birth. For each child, we have 14 possibilities (Boy or Girl) × 7 possible birthdays. That can significantly change how many combinations are ruled out, and the probability can be different (no longer

). The key idea is that whenever you gain more specific information about the child identified as a boy, it changes which cases remain possible and how likely they are.
Follow-up Question: Real-World Considerations (Non-50/50 Probability)
In reality, the probability of a child being a boy or girl might not be an exact 50/50 split. Also, real data shows slightly differing birth rates by gender. If you incorporate these real-world biases, or any difference in how you discover or observe that at least one child is a boy, the probabilities might shift. Nonetheless, the conceptual approach remains: define your sample space accurately, eliminate the impossible cases, and then determine the fraction of remaining cases where both children are boys.
Follow-up Question: Could the Probability Change If We Met the Boy in Person?
Yes. This depends on the condition under which you learn the child’s gender. Suppose you randomly bump into one specific child of the two, and you see it is a boy. That leads to another variation of the problem sometimes referred to as the “boy you meet in the street” scenario. In that scenario, the sample space can shift if your chance of encountering a boy vs. a girl is relevant. The puzzle becomes more complex because now some families with a boy are more likely to be encountered than those with only girls (which you do not encounter), and the order or which child you actually meet matters. Carefully modeling how you acquired the information (“seeing a boy” vs. “told there is at least one boy”) is necessary for computing the correct probability.
Follow-up Question: Implementation Pitfalls in Code
When running simulations, a subtle bug might be incorrectly filtering or duplicating outcomes. If you inadvertently merge BG and GB into the same outcome or incorrectly assign random child genders, your numerical results can deviate from the theoretical value. You should always verify your simulation logic matches your theoretical assumptions.
These variants highlight how crucial it is to define the information given and how it’s obtained, then clearly translate that into constraints on the sample space. That systematic approach leads you to the correct probability in each scenario.
Below are additional follow-up questions
If Parents Misremember or Give Unreliable Information
One interesting scenario is: what if we are not fully certain that the statement "at least one child is a boy" is accurate or complete? For example, parents might have made an offhand remark but could be mistaken or might not have clarified the statement properly.
Detailed Answer and Pitfalls When there is uncertainty about the reliability of the statement itself, the probability calculation changes because our conditional information is less reliable. We typically assume the statement "there is at least one boy" is factually correct with probability 1. If that statement is only 90% likely to be true, for instance, we have a more complex Bayesian update process:
We would create a joint probability distribution over (1) the actual family composition and (2) the correctness of the statement.
If we weigh the possibility that the statement might be in error, we cannot simply exclude the GG (girl, girl) case outright.
In a real-world setting, this may be relevant if we suspect miscommunication or incomplete information from the parents.
This question highlights how the standard

result relies on complete trust that the “at least one boy” statement is correct and precise. If that assumption is questionable, we need to adjust the probability accordingly.
Handling Cultural or Social Factors in Identifying “At Least One Boy”
Sometimes, whether a parent or an acquaintance shares that “one child is a boy” might be influenced by cultural or social preferences. For example, in certain societies, there might be a higher chance that people mention having a boy than having a girl.
Detailed Answer and Pitfalls When the probability of disclosing a boy vs. disclosing a girl is not equal, the likelihood of each scenario within your sample space shifts. For instance, a parent might be more inclined to volunteer “I have a boy” rather than “I have a girl.” This means that outcomes with a boy could be reported more frequently, altering the conditional probabilities.
To analyze this properly, you would assign a probability that a parent will say “I have a boy” if a boy exists. If there are two boys, maybe that probability goes up even more because there might be more occasions to mention a boy. Each scenario (BB, BG, GB, GG) would no longer be equally likely to lead to the statement “at least one boy.” The revised sample space weighting would then change the final probability.
Considering a Scenario Where Children Are Not Equally Likely to Be Boy or Girl
In certain real-world demographic data, the birth of a boy might occur with probability slightly different than 0.5 (for example, 0.51). How would that alter the

conclusion?
Detailed Answer and Pitfalls If the probability of having a boy is
p
(instead of 0.5), then the unconditional sample space probabilities for each pair become:

Knowing “at least one boy,” you exclude the GG case. Your conditional probability that both are boys is then


, the final probability is slightly larger than
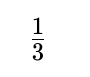
. This can be generalized for any real-world biases in birth probabilities.
Large Sample Observations and Frequentist Interpretation
A related question: if you observe many families with two children, and you select only those families that have at least one boy, how many would you expect to find that have two boys? Would it still come to about a third?
Detailed Answer and Pitfalls Yes, in a frequentist sense, if the probability of a boy is 0.5 per child and each family is independent, about a quarter of all families (on average) are BB, a quarter are GG, and half are BG or GB. Among those families that do not have two girls (GG), you have BB, BG, or GB. Thus, one-third of that subset will be BB. Potential pitfalls include:
Not having a large enough sample size to see the law of large numbers converge.
Accidental misclassification of families (e.g., mixing up who has at least one boy).
Social biases where some families might be underrepresented in your sample.
Cases Where Children Are Not Distinguishable by Birth Order
Sometimes, we might abstract away birth order and just say “the family has two children; at least one is a boy.” If we treat BG and GB as the same situation—because we do not care about which child was older—then do we still get

?
Detailed Answer and Pitfalls If you explicitly remove the concept of order, the distinct outcomes become:
Two boys
One boy and one girl
Two girls
Once you know there is at least one boy, the possibilities are “two boys” and “one boy and one girl.” That yields a

probability. However, this reasoning only applies if you genuinely treat (BG) and (GB) as the same event from the start (i.e., you do not count them as two separate outcomes). A common pitfall is mixing up the approach where we first treat BG and GB as distinct but then incorrectly count them as a single scenario. You must be consistent in your initial definition of the sample space. If you treat each child as distinguishable in principle (like older vs. younger), you keep BG and GB as separate. If you treat the children as an indistinguishable set, you fuse BG and GB.
Considering a Nonbinary Child or a Third Gender Possibility
In the real world, there may be additional gender categories beyond the traditional boy/girl binary. If the question is generalized to any “at least one child is of a specific gender,” how does that affect the sample space?
Detailed Answer and Pitfalls Assume three categories: Boy (B), Girl (G), and Nonbinary (N). Then the full sample space for two children has 3 × 3 = 9 outcomes:
(B, B), (B, G), (B, N),
(G, B), (G, G), (G, N),
(N, B), (N, G), (N, N).
If the statement is “at least one child is a boy,” we exclude any pair that has no boy at all. That removes (G, G), (G, N), (N, G), (N, N). The new set is:
(B, B), (B, G), (B, N), (G, B), (N, B).
If we assume each child’s gender is equally likely among B, G, N for simplicity (each with probability 1/3), then we can weigh these outcomes accordingly. The probability of (B, B) among these five scenarios depends on their original probabilities (since (B, B) had probability (1/3)*(1/3)=1/9, etc.). You end up with a more complex ratio. This scenario highlights that any real-world expansion of possible gender identities changes the probability in nontrivial ways.
Ignoring the Possibility of Twins or Triplets
A subtle question might be: does the logic change if the siblings are twins or have a certain correlation in their gender, or if there could be more than two children?
Detailed Answer and Pitfalls If there are only exactly two children but they are twins, in principle the probability approach remains the same provided each child’s gender is still an independent 50/50 event. However, some research suggests the probability of boy/girl pairs might differ for certain types of twins (e.g., identical vs. fraternal). If that correlation is introduced, the independence assumption breaks. Then we must reevaluate the probabilities in each case:
Identical twins must be the same gender, so the possible pairs become: BB or GG (no BG or GB). Then “at least one is a boy” implies you must have both boys with probability 1 in the identical-twin scenario.
If the twins are fraternal, we return to something closer to the normal 50/50 scenario, but there might be slight variations in probability.
For families with more than two children, the complexity grows, and we have to define precisely which children’s genders we’re referencing when we say “at least one is a boy” and how that filters the sample space of possible compositions.
Confusion Over “At Least One Boy” vs. “Exactly One Boy”
Another subtlety: is there a possibility that the statement “one child is a boy” is interpreted by some as “exactly one child is a boy”?
Detailed Answer and Pitfalls If an interviewer or a puzzle is poorly worded, one might mistakenly believe the statement means that precisely one of the two children is a boy. That would immediately exclude (B, B) from the sample space and lead to different outcomes. This misunderstanding drastically changes the probability from

to 0, because (B, B) would be excluded. It’s crucial in probability problems to distinguish between “at least one child is a boy” and “exactly one child is a boy.” The difference is subtle in casual language but fundamental in probability terms.
Potential Application to Machine Learning Classification
Another angle is imagining a machine learning classification scenario where a model identifies the gender of each child from some data or images, and we receive partial information (“the model is sure at least one is a boy”) but not full details.
Detailed Answer and Pitfalls
We might have uncertainties in model output, with probabilities assigned to each gender classification.
If the model states “at least one child is predicted male,” we might incorporate each child’s predicted probability of being male or female.
We then have to recast the problem as a Bayesian update, weighting each possible combination by the model’s predicted confidence.
A potential pitfall is ignoring correlated errors (e.g., if the model systematically confuses younger female children for male more often). Real-world classification tasks can introduce bias that changes how we condition our sample space.
Impact on Real-World Survey Studies
Finally, in a broader data-collection scenario, if we are surveying families and track only families that mention having a boy, how do we handle that selection bias when analyzing the frequency of two-boy families?
Detailed Answer and Pitfalls Selection bias emerges when you only include respondents who have at least one boy. You systematically exclude families that have no boys, which skews your statistics about how many two-boy families you observe relative to the entire population. To account for this, you need to do post-stratification or weighting in your dataset to handle the missing GG families. You must also confirm that families are equally likely to respond or that your data collection method does not further distort the proportions.
Any real-world scenario combining selection bias with statements about children’s genders can create subtle misinterpretations of data if you fail to consider that you have already filtered your sample based on partial knowledge of family composition.