
ML Interview Q Series: Can you build a model to extract aspects from reviews and identify sentiment for each aspect?

📚 Browse the full ML Interview series here.
Comprehensive Explanation
Aspect-based sentiment classification focuses on identifying the relevant attributes in a text (e.g., food, service) and predicting sentiment (e.g., positive, negative, neutral) for each identified aspect. This requires two main steps: extracting or recognizing the aspects, and classifying the corresponding sentiment for each aspect. There are different approaches:
Extraction of Aspects
One way to isolate the relevant attributes of a review is to train or use a pre-trained named entity recognizer (NER) or a specialized aspect extractor. Deep learning architectures, such as Transformers, can be fine-tuned on aspect extraction tasks. Another approach is to rely on syntactic rules or chunking to detect candidate nouns or noun phrases that might represent aspects. In practice, combining rule-based strategies with learned models (through semi-supervised or supervised approaches) can increase performance.
Sentiment Classification for Each Aspect
Once the aspects are detected, each aspect or aspect phrase is passed through a sentiment classification component. This component can be a fine-tuned Transformer (such as BERT), or a more classical model like an LSTM. The model would take the review text, the aspect span, and potentially additional context as input to produce a label (e.g., positive, negative, neutral).
Typical Training Objective
When training a model for multi-aspect sentiment classification, one often uses cross-entropy as the loss function. For each aspect i in a given training example, the model outputs a probability distribution p over sentiment categories. Let y_i be the ground truth label (e.g., y_i=1 if the sentiment is positive, 0 otherwise). The cross-entropy loss is then computed for each aspect and aggregated across all aspects.
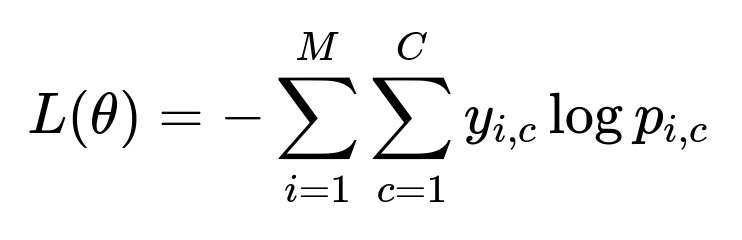
Here, M is the number of aspects in a training instance, C is the number of possible sentiment classes, y_{i,c} is 1 if aspect i belongs to class c, and p_{i,c} is the predicted probability that aspect i belongs to class c. Summation is done over all aspects M in a review, and for each aspect, over all classes C. This objective can then be averaged across the entire training dataset.
Data Collection and Labeling Strategy
Building this classifier can require a specialized dataset where each review is annotated not just with a sentiment but also with the specific attributes mentioned in the text. Manual annotation can be expensive, so weaker forms of supervision or domain-specific lexicons might be used to bootstrap aspect extraction. Once a comprehensive annotated dataset is prepared, one can adopt a pipeline approach:
Identify candidate words or phrases (nouns, entities).
Classify or group them as aspects of interest (e.g., food, service).
Apply or fine-tune a sentiment classifier on the text snippet containing that aspect.
Implementation Example
import torch
from transformers import BertTokenizer, BertForTokenClassification, BertForSequenceClassification
# Step 1: Aspect Extraction (NER-like model)
tokenizer_aspect = BertTokenizer.from_pretrained('bert-base-uncased')
model_aspect = BertForTokenClassification.from_pretrained('bert-base-uncased', num_labels=num_aspect_labels)
def extract_aspects(text):
inputs = tokenizer_aspect(text, return_tensors='pt')
outputs = model_aspect(**inputs)
# post-process outputs to identify aspect tokens or phrases
aspect_spans = decode_aspect_spans(outputs.logits)
return aspect_spans
# Step 2: Aspect Sentiment Classification
tokenizer_sentiment = BertTokenizer.from_pretrained('bert-base-uncased')
model_sentiment = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3) # for pos/neg/neutral
def classify_sentiment_for_aspect(text, aspect_span):
aspect_text = text[aspect_span[0]:aspect_span[1]] # slice text or use sub-word offsets
inputs = tokenizer_sentiment(aspect_text, return_tensors='pt')
outputs = model_sentiment(**inputs)
sentiment_label = torch.argmax(outputs.logits, dim=1).item()
return sentiment_label
def process_review(text):
aspects = extract_aspects(text)
results = {}
for asp in aspects:
sentiment_label = classify_sentiment_for_aspect(text, asp)
# label mapping {0: 'negative', 1: 'positive', 2: 'neutral'}
results[asp] = sentiment_label
return results
This simplified example shows a two-model pipeline. In real-world scenarios, you might combine these steps into a single transformer model that does aspect detection and sentiment classification jointly.
Practical Considerations and Pitfalls
It can be challenging to handle subtle sentiment (e.g., sarcasm), context-dependence (e.g., “great portion sizes but overpriced”), or complicated multi-aspect phrases. Data sparsity can arise if some aspects are rarely mentioned. Additionally, as the domain evolves (menu items or features of a restaurant change), the model may require retraining or domain adaptation. Handling synonyms and ambiguous references is another common challenge (e.g., “The steak was decent, but they messed up the order.” which might refer to “food” or “service” or both).
Possible Follow-Up Questions
How do you handle reviews where multiple aspects appear in the same sentence with different sentiments?
One approach is to identify the spans of text that refer to different aspects. For each span, you gather enough localized context (for instance, a window of tokens around that span) to decide its sentiment. Another approach might use dependency parsing to more precisely connect descriptive phrases (adjectives) with the corresponding nouns.
Is there a way to build a single model that jointly extracts aspects and classifies sentiment?
Yes. Joint modeling uses either a single encoder (e.g., BERT) with a multi-task learning framework. The encoder captures the contextual embeddings, and then you have separate heads (like token classification for aspects and sequence classification for sentiment). Such an approach can reduce error propagation seen in pipeline methods because the model learns the interplay between aspects and sentiment end-to-end.
How do you address implicit aspects (e.g., “It arrived cold” might refer to the food aspect even if the user doesn’t explicitly mention “food”)?
Handling implicit aspects relies on context-based or common-sense inference. A more advanced model or a knowledge-augmented model can better identify that “arrived cold” likely references the dish or food. You can also augment your training set with examples of implicit mentions and rely on large-scale language models to generalize from those patterns.
What if the distribution of aspects is highly unbalanced (some aspects rarely appear)?
Use techniques like oversampling, undersampling, or focal loss. Data augmentation can also help by artificially creating more examples for the infrequent aspects. Transfer learning from similar domains can sometimes provide robust representations for the rarer aspects.
How would you evaluate this multi-aspect sentiment classifier?
One needs to measure both aspect extraction performance (precision, recall, F1 score for each aspect category) and sentiment classification performance (accuracy, F1 for positive/negative classes, etc.). A combined metric could consider correct detection of the aspect and correct classification of the corresponding sentiment simultaneously (e.g., aspect-level F1).
Below are additional follow-up questions
How do you handle incomplete or missing aspect annotations in the training data?
When annotation resources are limited, or when only a portion of reviews are fully labeled for aspects, a model trained purely on supervised data may struggle due to the limited coverage. Semi-supervised learning methods can help, where you combine a smaller labeled dataset with a larger unlabeled corpus. You might perform pseudo-labeling, in which your current model (or a simpler rule-based system) predicts aspects on unlabeled data, and you iteratively refine these predictions. This approach can gradually improve the system’s ability to extract unknown or underrepresented aspects. However, an obvious pitfall is propagating errors from imperfect pseudo-labels, which can reinforce biases in your model. One needs to carefully monitor the model’s performance and validate pseudo-labeled data periodically.
Can a single sentence contain conflicting sentiment for the same aspect, and how would you address this?
Yes, a single sentence might contain contradictory statements about the same aspect. For instance, “I usually love their pizza, but this time it was bland.” Here, the pizza aspect is normally associated with a positive sentiment, yet the current experience is negative. A purely token-level classification that tries to assign one sentiment label per aspect may overlook these nuances. One way to manage this is to split the text into smaller spans or clauses, then identify the aspect mentions within each. Each clause would have its own local context, allowing the model to capture the sudden shift in sentiment. Another pitfall is misattributing the contradictory sentiment to a different aspect if the structure of the sentence is complex. Careful phrase-level analysis (e.g., using syntactic parsing or advanced attention mechanisms in Transformers) can help.
Could you incorporate external knowledge graphs or domain ontologies to identify relevant aspects?
Yes, external knowledge sources (like a knowledge graph of restaurant terminology or a domain ontology for cuisine types) can help in mapping textual mentions to standardized aspects. This is especially valuable in handling synonyms or domain-specific slang. For instance, “appetizers” could be matched with “starters,” or “chips” might be recognized as “fries” in certain locales. However, a pitfall arises when the knowledge base is incomplete or outdated, causing mismatches between the text and the graph entries. Another challenge is deciding when to rely on the knowledge graph for aspect identification versus letting the model’s learned representations handle novel or creative expressions that are not in the graph. Hybrid solutions that combine learned embeddings with symbolic knowledge can strike a balance.
How do you handle code-mixed or multi-lingual reviews?
In real-world settings, users might switch between languages or incorporate words and phrases from multiple languages. A single pipeline model pre-trained only on English data might fail to detect aspects or assign sentiments correctly for code-mixed text. To address this, you can fine-tune a multi-lingual Transformer model (like XLM-R) on a dataset containing code-mixed examples. You may also use language identification to split segments of the text by language, then pass them to language-specific sentiment classifiers. Still, a major pitfall is that code-switching can occur mid-sentence, making naive segmentation inaccurate. Effective multi-lingual handling requires enough examples of code-mixed usage to teach the model how to parse the combined context properly.
Can zero-shot or few-shot learning be leveraged to handle new aspects or sentiment targets not encountered during training?
Yes, zero-shot or few-shot models (often based on large language models) can infer sentiment about novel aspects if given a suitable prompt or minimal labeled examples. For instance, you can feed the model a prompt like “Identify the sentiment about the following aspect: X” and rely on the model’s inherent language understanding. This is valuable in fast-evolving domains where new menu items or new restaurant features might appear. A pitfall is that zero-shot performance often lags behind fully supervised models on seen aspects. Also, few-shot approaches require carefully selected examples for fine-tuning; otherwise, the model might overfit to those examples or fail to generalize.
In practice, do you integrate rule-based components with machine learning methods, and how do you balance their trade-offs?
Yes, many production systems fuse a rule-based approach (for easy-to-recognize patterns or domain-specific keywords) with a learned model that handles more nuanced or context-dependent cases. The advantage of rules is that they are transparent and directly reflect domain expertise (for instance, a dictionary of sentiment-laden words related to food quality). However, rule sets can grow unwieldy, and they may fail to generalize to new expressions. A typical pitfall is conflicting rules or excessive manual maintenance as the domain evolves. A hybrid system might first apply a rule-based filter to catch straightforward patterns, then pass ambiguous text to a machine learning classifier for deeper contextual analysis.
What strategies can detect domain drift or linguistic shifts over time, and how can you adapt the model to these changes?
To detect domain or linguistic drift, you can track data distribution changes. For example, monitor the frequency of certain aspect keywords or measure divergence in the embeddings of newly collected reviews versus older reviews. Once drift is detected, you can adapt the model via incremental or continuous learning. For instance, a model can be fine-tuned on a small batch of new, representative data. A significant pitfall lies in catastrophic forgetting, where adapting to new patterns may degrade performance on previously learned concepts. Techniques like replay buffers (keeping a curated subset of old data) or parameter regularization can help preserve knowledge of older distributions while updating on new data.
When would you choose a hierarchical model architecture for multi-aspect sentiment classification, and how would you design it?
A hierarchical model becomes useful when reviews are lengthy and contain multiple sentences describing numerous attributes. You might first have a sentence-level encoder (often an RNN, CNN, or a segment-level Transformer) to capture local context within a sentence. Then, an upper-level encoder aggregates sentence representations to form a document-level summary. The model can identify which sentences are likely to contain references to aspects, and subsequently classify sentiment at the sentence or aspect level. A pitfall here is that hierarchical models can be complex and computationally expensive. Also, if the review lumps multiple aspects into one sentence, you might still need finer-grained token-level analysis. Ensuring you do not lose fine-grained signals in the aggregation step is crucial.
How do you handle privacy concerns or sensitive data in restaurant reviews, such as personal information or protected group references?
Some reviews contain private or personally identifying information (like the reviewer’s name or phone number) or sensitive content referencing personal traits (e.g., ethnicity, religion). It might be necessary to redact or anonymize these portions before training, particularly in jurisdictions with strict data protection regulations. A pitfall arises if sentiment toward an aspect is conflated with discrimination or hate speech (e.g., a negative statement about a certain group). You might need to incorporate a separate content moderation classifier to filter out or handle hateful or offensive content. Another subtle issue is fairness—models should not learn spurious correlations between sensitive demographics and certain sentiment patterns.
How might you employ an ensemble of models for improved aspect-based sentiment classification, and what are the trade-offs?
Ensembling can be done by training multiple models (e.g., different Transformer architectures or different random seeds) and combining their predictions through voting or averaging. This often boosts performance by smoothing out the idiosyncrasies of a single model. You can also ensemble different modeling paradigms, like an NER approach for aspect extraction combined with a sequence classification approach for sentiment. However, ensembles typically increase inference latency and memory usage, which can be problematic in high-traffic environments (like a large-scale review platform). There can also be complexities in deploying and maintaining multiple models in production, and debugging becomes harder if you do not know which sub-model contributed to an erroneous ensemble decision.