
ML Interview Q Series: Chi-Square Test: Validating Poisson Distribution for Particle Count Data

Browse all the Probability Interview Questions here.
In a famous physics experiment performed by Rutherford, Chadwick and Ellis in 1920, the number of α-particles emitted by a piece of radioactive material were counted during 2,608 time intervals of each 7.5 seconds. There were 57 intervals with zero particles, 203 intervals with 1 particle, 383 intervals with 2 particles, 525 intervals with 3 particles, 532 intervals with 4 particles, 408 intervals with 5 particles, 273 intervals with 6 particles, 139 intervals with 7 particles, 45 intervals with 8 particles, 27 intervals with 9 particles, 10 intervals with 10 particles, 4 intervals with 11 particles, 0 intervals with 12 particles, 1 interval with 13 particles, and 1 interval with 14 particles. Use a chi-square test to investigate how closely the observed frequencies conform to Poisson frequencies.
Short Compact solution
The parameter of the hypothesized Poisson distribution describing the number of counts per time interval is estimated from the data as 10,094/2,608 = 3.8704. We group the time intervals into 12 categories by combining all intervals with 11 or more particles into a single category. The expected frequencies under this Poisson model are computed for each category. The chi-square test statistic is given by ( (57 - 54.768)²/54.3768 ) + ( (203 - 210.4604)²/210.4604 ) + … + ( (6 - 5.7831)²/5.7831 ) = 11.613. Because the Poisson parameter was estimated from the data, the chi-square distribution with 12 - 1 - 1 = 10 degrees of freedom is used. The probability P(χ²₁₀ ≥ 11.613) = 0.3117. Hence, the Poisson distribution provides a good fit.
Comprehensive Explanation
Overview of the Problem
We have experimental data on the number of α-particles emitted during 2,608 consecutive 7.5-second intervals. The question is whether a Poisson distribution, with its parameter estimated from the observed data, is a good model for the distribution of the counts of α-particles per time interval.
Estimating the Poisson Parameter
For a Poisson random variable X with rate λ, the mean of X is λ. To fit a Poisson distribution to data, the sample mean is used as the estimator of λ. Specifically, if we observe a total of M α-particles over N intervals, then the maximum-likelihood estimate of λ is (M / N).
From the data, we have a total of 10,094 α-particles observed over 2,608 intervals. Therefore the Poisson parameter is estimated as 10,094 / 2,608 ≈ 3.8704.
Expected Frequency Calculation
Under the Poisson model with parameter λ, the probability of observing k particles in a given interval is:
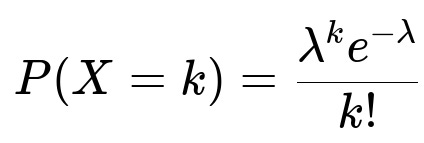
where λ is 3.8704 in this experiment. For each count k, the expected frequency is given by N × P(X = k), where N = 2,608 is the total number of intervals.
Because some of the higher counts (like 11, 12, 13, 14 particles) occur very rarely, we combine them into a single group “11 or more” to maintain sufficiently large expected counts in each category. This grouping ensures that each category’s expected frequency does not become too small (a common heuristic is that each category’s expected frequency should ideally be at least 5 for the standard chi-square test approximation).
Chi-square Test Statistic
The chi-square goodness-of-fit test for this scenario uses the following test statistic:

Here:
g is the number of categories (after grouping).
O_i is the observed frequency in category i.
E_i is the expected frequency in category i under the fitted Poisson model.
In this experiment, we end up with g = 12 categories (0 particles, 1 particle, 2 particles, …, 10 particles, and ≥11 particles). Plugging in the values:
For 0 particles, O_0 = 57, E_0 ≈ 54.768
For 1 particle, O_1 = 203, E_1 ≈ 210.4604
…
And for ≥11 particles, O (combined) = 6, E (combined) ≈ 5.7831
Summing each (O_i - E_i)²/E_i yields 11.613.
Degrees of Freedom
Because the Poisson distribution parameter λ is estimated from the data, the degrees of freedom for the chi-square test is (g - 1 - number_of_estimated_parameters). We have:
g = 12 total categories
We estimated 1 parameter (λ)
We also lose 1 degree of freedom due to the sum of O_i = sum of E_i
Hence the degrees of freedom is 12 - 1 - 1 = 10.
P-value and Conclusion
We compare the computed chi-square statistic 11.613 with the chi-square distribution χ²(10). The p-value is P(χ²(10) ≥ 11.613) ≈ 0.3117. Because 0.3117 is not too small, we do not reject the hypothesis that the counts follow a Poisson distribution. In other words, the data are consistent with the Poisson model.
Potential Follow-up Questions
How do you handle small expected frequencies in a chi-square goodness-of-fit test, and why did we group categories ≥11?
When using a chi-square goodness-of-fit test, if the expected count in any category is too small (often less than 5), the chi-square approximation may not be valid. To handle this, we merge categories together until the expected count in each combined category reaches an acceptable threshold. In this problem, the interval counts of 11, 12, 13, and 14 occurred so rarely that each individual category would have had very small expected counts, so we combined them into one group “≥11.” This keeps the chi-square approximation more accurate.
Why do we use df = 12 - 1 - 1 for the chi-square distribution’s degrees of freedom?
In a standard chi-square goodness-of-fit test, if we have g categories, the degrees of freedom are g - 1. However, each parameter estimated from the data reduces the degrees of freedom by 1. For a Poisson model, we estimate λ from the data. This means the degrees of freedom is (g - 1 - 1). Here, g = 12, so df = 10.
Could we use a different test for the same hypothesis instead of a chi-square test?
Yes. One could use the likelihood ratio test (G-test) or even compare the empirical distribution function with the theoretical Poisson distribution (e.g., using a Kolmogorov–Smirnov type approach). Each test might have slightly different properties in terms of power, sensitivity to outliers, and how it handles small counts.
What are some assumptions behind modeling the count data with a Poisson distribution?
Independence of events within each interval.
A constant average rate of occurrence (λ).
The occurrence of one event in a very small sub-interval does not change the probability of another event occurring in that sub-interval.
If any of these assumptions are violated—e.g., strong dependence between particles, or a changing rate over time—the Poisson model might not fit well.
If a researcher found that the data do not follow a Poisson distribution, what might that indicate?
It could indicate that the process has overdispersion (variance exceeds the mean) or underdispersion (variance smaller than the mean). In real-world particle counting, overdispersion sometimes arises if there are variations in the underlying intensity or if particles interact. A negative binomial or other generalized count models might be more appropriate in such cases.
How would you implement this chi-square test in Python?
Below is an illustrative Python snippet showing how one might compute the chi-square statistic for a given dataset with a Poisson fit. We assume we already have the observed counts in some array, and we compute λ from the data.
import numpy as np
from math import factorial, exp
from scipy.stats import chi2
# Suppose observed_counts is a list or NumPy array of length N
# observed_counts[i] = number of intervals in which i particles were observed
# Merge categories as needed (e.g., 11 and above).
observed_counts = [57, 203, 383, 525, 532, 408, 273, 139, 45, 27, 10, 4, 0, 1, 1]
N = 2608 # total intervals
total_particles = sum(i * observed_counts[i] for i in range(len(observed_counts)))
lambda_est = total_particles / N
# Create categories 0..10 and >= 11
# For demonstration: let's store them in a new array
grouped_observed = observed_counts[:11] + [sum(observed_counts[11:])] # Combine >= 11 into one bin
def poisson_pmf(k, lam):
return (lam**k * exp(-lam)) / factorial(k)
# Compute expected frequencies
grouped_expected = []
for k in range(11):
# P(X=k) * N
grouped_expected.append(poisson_pmf(k, lambda_est) * N)
# Probability for >= 11
p_ge_11 = 1 - sum(poisson_pmf(k, lambda_est) for k in range(11))
grouped_expected.append(p_ge_11 * N)
# Compute chi-square
chi_square_stat = 0.0
for obs, exp_val in zip(grouped_observed, grouped_expected):
chi_square_stat += (obs - exp_val)**2 / exp_val
# Degrees of freedom = number of groups - 1 (from sum of prob=1) - 1 (from parameter estimation)
df = len(grouped_observed) - 1 - 1
# p-value
p_value = 1 - chi2.cdf(chi_square_stat, df)
print("Chi-square statistic:", chi_square_stat)
print("Degrees of freedom:", df)
print("p-value:", p_value)
This code illustrates how to group categories, calculate expected counts under a Poisson distribution, and obtain the chi-square statistic and its p-value. The final step is to interpret whether the data appear consistent with a Poisson model by examining the p-value.
Below are additional follow-up questions
How would you construct a confidence interval for the Poisson rate parameter λ in this experiment?
One direct way to approximate a confidence interval for λ is to use the asymptotic properties of the maximum likelihood estimate (MLE). Recall that for a Poisson distribution, the MLE for λ is the sample mean: total count / total number of intervals. Under large-sample assumptions, the sampling distribution of this estimate is approximately normal with variance (λ / N), where N is the number of intervals. Therefore:
Compute the MLE: λ_hat = total_particles / N.
Approximate the variance of λ_hat as λ_hat / N.
Then the 95% confidence interval can be approximated by λ_hat ± z * sqrt(λ_hat / N), where z is the critical value from the standard normal distribution (e.g., z=1.96 for 95%).
A potential pitfall is that if the total number of intervals N is not large or if λ is quite small or large, the normal approximation may not be very accurate. One might instead use approaches based on the exact or near-exact confidence intervals derived for Poisson means (e.g., a method based on the chi-square distribution or profile likelihoods). In real-world experiments, especially where λ is not large and N might be moderate, these more exact methods may be preferable for improved accuracy.
What if the data were observed to be overdispersed relative to a Poisson model?
Overdispersion means the observed variance in the counts exceeds the mean by more than what would be expected under the Poisson assumption (which requires var = mean = λ). If the data show significantly larger variance, then the Poisson might systematically under-predict the frequency of intervals with high counts and over-predict the frequency of intervals with lower counts, causing a poor fit and larger chi-square statistic.
An alternative approach would be to consider models such as the negative binomial (also called the Polya distribution) which has an additional “dispersion” parameter. That extra parameter allows the variance to be larger than the mean. One risk is that if we quickly jump to negative binomial or other more flexible models without verifying that the fundamental Poisson assumptions have been violated, we may introduce unnecessary model complexity. Also, diagnosing overdispersion can be tricky in smaller samples, where random variation alone might cause apparently high variance.
Could the length of each interval (7.5 seconds) affect whether a Poisson is appropriate?
Yes. A Poisson process is often described for continuous time, assuming that events occur independently at a constant average rate. If 7.5-second intervals are chosen arbitrarily, or if the process within each interval exhibits temporal clustering (e.g., bursts of α-particle emissions), then the distribution of counts in each interval might not be strictly Poisson. For instance, if the emission rate changes within each 7.5-second interval—say, due to some external factor like temperature changes—then the data might instead be described by a nonhomogeneous Poisson process.
Another subtle pitfall is if the process is truly Poisson at a smaller time scale but the 7.5-second window is large enough that the independence assumption breaks down due to unmodeled correlations or gating effects. One approach is to test whether different interval lengths (e.g., 1 second vs 7.5 seconds vs 15 seconds) yield consistent estimates of λ and consistent distributional fits, which can help confirm or refute the assumption of a stationary Poisson process.
How does one assess goodness of fit if we suspect multiple parameters need to be estimated?
The Poisson distribution is a single-parameter model. However, if we suspected a more complex model—like a mixture of two Poisson distributions (e.g., half the time with one rate λ1, half the time with another rate λ2)—we would need to estimate additional parameters. Each new parameter reduces the degrees of freedom in the chi-square test by one. Hence, for a mixture model with two Poisson components, we would have at least two parameters (the two rates) plus the mixing weight. This can lead to challenges in how we group the categories so that expected counts remain sufficiently large. A more robust approach might be to use likelihood-based model selection methods (AIC or BIC) that account for the complexity of the model when comparing different distributions.
A pitfall is that as you allow the model more degrees of freedom, it may fit the current data more closely but lose interpretability and predictive power. Overfitting can happen, especially if the number of intervals is not large enough to reliably fit multiple parameters.
What if the experiment were performed in multiple runs with potentially different underlying rates?
Realistically, the emission rate of a radioactive sample might change slightly over time or across different runs due to physical conditions (temperature, partial decay of the source over long periods, etc.). If the data come from multiple runs, each might have a different “true” λ. Pooling all runs together and treating them as one dataset can mask that heterogeneity.
A more refined approach is to stratify data by run or by some measure of time, then fit a Poisson model (and perform a goodness-of-fit test) within each subset. You might also fit a hierarchical model where each run has its own rate λ_i drawn from a common hyperdistribution. Such hierarchical models can capture variability across runs better than forcing a single global λ. If one lumps all intervals together ignoring differences across runs, the overall chi-square test might appear to confirm or reject the Poisson fit without revealing that only some runs deviate. The pitfall is that you lose interpretability or mix data from distinct conditions if you fail to consider the possibility of multiple underlying rates.
How should one proceed if some intervals have extremely high counts that seem inconsistent with the rest of the data?
Intervals with very high counts relative to λ can heavily affect the chi-square statistic. A single outlier category could push the chi-square value high enough to reject the Poisson model. In practice, it is important to verify the validity of these high-count intervals:
Were they measurement errors?
Did the instrument malfunction?
Was there contamination from another source?
If those outliers are indeed valid observations, they may signal that the Poisson assumption is not correct, possibly indicating overdispersion or a time-varying rate. To handle these edge cases, one might combine high-count categories as done here (≥ 11). But if even with grouping, the outliers have a substantial effect on the chi-square statistic, further investigation of alternative models may be warranted. In mission-critical or high-stakes settings, you might do an in-depth root cause analysis of each outlier observation before concluding that the Poisson assumption fails.