
ML Interview Q Series: Circle Area Probability Density from Normal Variables via Chi-Square Distribution

Browse all the Probability Interview Questions here.
Let (X) and (Y) be independent random variables each having the standard normal distribution. Consider the circle centered at the origin and passing through the point ((X,Y)). What is the probability density of the area of the circle? What is the expected value of this area?
Short Compact solution
We know that (R = \sqrt{X^{2} + Y^{2}}) is the radius of the circle, and so the area of the circle is ( \pi (X^{2} + Y^{2})). Since (X) and (Y) are independent standard normals, (X^{2} + Y^{2}) follows a chi-square distribution with 2 degrees of freedom, which is an exponential distribution with the density:
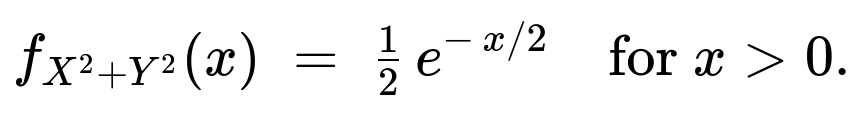
Hence, if we denote (V = \pi , (X^{2} + Y^{2})) (the area), we find its PDF by change of variables. The result is an exponential distribution with parameter (1/(2\pi)). Therefore:

The expected value of an exponential random variable with parameter (1/(2\pi)) is (2\pi). Hence the expected area is (2\pi).
Comprehensive Explanation
Random Radius and the Chi-Square(2) Distribution
When (X) and (Y) are independent standard normal random variables, each has mean 0 and variance 1. The sum of their squares, (X^{2} + Y^{2}), is known to follow a chi-square distribution with 2 degrees of freedom. Equivalently, this is an exponential distribution with rate 1/2. In simpler text form, we say:
PDF of (X^{2} + Y^{2}) = (1/2) e^(-x/2), for x>0.
Deriving the Distribution of the Area
We define the area of the circle by (V = \pi (X^{2} + Y^{2})). To find the PDF of (V), we use a standard change-of-variables technique. Set (V = \pi W) where (W = X^{2} + Y^{2}). Then for v>0:
P(V <= v) = P(W <= v / pi).
We already know the CDF of W is 1 - e^(-(v/pi)/2). Differentiating that CDF with respect to v gives us the PDF of V. Accounting for the derivative dW = dv/pi leads to:
f_V(v) = (1 / pi) * f_W(v / pi).
Substituting f_W(x) = (1/2) e^(-x/2), we get:
f_V(v) = (1 / pi) * (1/2) e^{- (v/pi) / 2} = (1 / (2 pi)) e^{- v / (2 pi)}, for v>0.
This shows that V is exponential with parameter 1/(2 pi).
Expected Value of the Area
For an exponential distribution with parameter λ = 1/(2π), the expected value is 1/λ, which is 2π. Thus,
E[Area] = 2π.
This aligns with the intuitive fact that E[X^2 + Y^2] = 2, so multiplying by π gives an expected area of 2π.
Potential Follow-Up Questions
What does it mean that (X^{2} + Y^{2}) is chi-square with 2 degrees of freedom?
Since both X and Y are N(0,1) and independent, (X^{2} + Y^{2}) represents the sum of squares of 2 standard normal variables. By definition, this sum follows a chi-square distribution with 2 degrees of freedom, which is also an exponential distribution with mean 2.
Could we generalize this to higher dimensions?
Yes. If you had n independent N(0,1) variables, the sum of squares would follow a chi-square distribution with n degrees of freedom. The “area” would then be replaced by the corresponding n-dimensional “surface” measure of the sphere. The approach of using a change of variables would still hold, leading you to a gamma distribution in higher dimensions.
How would we verify this result computationally?
We could run a simulation in Python:
import numpy as np
N = 10_000_000
X = np.random.randn(N)
Y = np.random.randn(N)
areas = np.pi*(X**2 + Y**2)
# Estimate the mean
empirical_mean = np.mean(areas)
print("Empirical mean:", empirical_mean)
We would expect the empirical mean to be close to 2π for a large sample size.
How does this relate to radial symmetry?
Because X and Y are isotropic (identical, independent normal distributions centered at 0), the distribution of their radius sqrt(X^2 + Y^2) does not depend on direction, only on distance from the origin. Hence the area of the circle through (X,Y) must depend on an exponentially distributed random variable.
Why is the PDF of V itself exponential?
It is an application of the linear transformation of an exponentially distributed random variable: If W is exponential with mean 2, then c·W is exponential with mean 2c. Here, c=π, so the distribution of πW has mean 2π, confirming that it remains exponential.
All these details illustrate the key properties of the circle’s random area, its exponential shape, and why the expected value turns out to be 2π.
Below are additional follow-up questions
How can we derive the moment generating function of the area distribution, and how does it confirm the mean and variance?
The moment generating function (MGF) of a random variable helps us systematically obtain its moments (like mean and variance). For the area V = π(X^2 + Y^2), we know V follows an exponential distribution with parameter 1/(2π). The MGF of an exponential random variable with parameter λ is M(t) = λ / (λ - t), for t < λ. In our case, λ = 1/(2π).
Hence, the MGF of the area V is:

From this MGF, the mean of V is obtained by taking the first derivative at t=0. That derivative is 1/λ = 2π, which is the expected area. The second derivative at t=0 allows us to compute the variance as 1/λ^2 = (2π)^2 = 4π^2.
A subtle pitfall occurs if you try to evaluate M(t) beyond t >= 1/(2π), where the MGF does not converge; this reminds us that the MGF of an exponential distribution has a finite radius of convergence. In practice, this might matter if you are working with generating functions in certain approximate expansions or transformations.
Does the result change if X and Y are not standard normal but have different variances or a correlation?
If X and Y have identical but non-unit variance, say variance σ^2, then X^2 + Y^2 follows a different scaled chi-square distribution. Specifically, X/σ and Y/σ would be standard normals, so (X^2 + Y^2)/σ^2 would be chi-square(2). The area would become V = π (X^2 + Y^2) = πσ^2((X/σ)^2 + (Y/σ)^2). Thus, V scales by πσ^2 times the original chi-square(2). In that scenario, the parameter of the exponential distribution for V changes accordingly.
If there is correlation between X and Y, then (X^2 + Y^2) does not follow a simple chi-square(2) distribution. You would need the joint distribution of X and Y to determine how X^2 + Y^2 is distributed. Typically, with correlation ρ, you cannot decompose X^2 + Y^2 into a standard chi-square form unless ρ=0. This fundamentally alters both the PDF and the expected value of the circle’s area. A practical pitfall is to assume zero correlation in real-world data that actually exhibits correlation, thus incorrectly modeling the distribution of the area.
What is the variance of the area, and can we derive it directly from its PDF?
We know from the exponential distribution with rate 1/(2π) that the variance is (1/λ^2). Since λ = 1/(2π), the variance is (2π)^2 = 4π^2. Alternatively, you can calculate this directly from the PDF of V by integrating v^2 times f_V(v) over all v>0 and subtracting the square of its mean. Doing this integral:
E[V^2] = ∫ from 0 to ∞ of v^2 * (1/(2π)) e^(-v/(2π)) dv,
and since for an exponential distribution with rate λ, E[V^2] = 2/λ^2, you get 2 * (2π)^2 = 8π^2. Subtracting (2π)^2 from 8π^2 yields 4π^2 for the variance.
A subtlety arises if you attempt to compute the second moment by naive integration without carefully handling the exponential’s normalization or the change of variables from X^2 + Y^2. It’s important to perform each step carefully, ensuring the integral bounds and Jacobian factors are correct.
Could we consider real-world data where X and Y may not be exactly normal but approximately normal?
Yes. In many applications, data might come from distributions that are close to normal but not perfectly so. If X and Y are only approximately normal, the distribution of X^2 + Y^2 might deviate somewhat from the chi-square(2). That implies the area of the circle π(X^2 + Y^2) might deviate from a perfect exponential distribution. The expected area might still be “close” to 2π if the deviations from normality are small.
A practical pitfall is blindly applying theoretical distributions (like chi-square) in real-world scenarios without checking normality assumptions. Significant departures from normality—heavy tails, skewness, or multimodality—could produce overestimates or underestimates of the expected area and misrepresent the tail probabilities. In a real production setting, one would perform normality tests or use more robust distributional assumptions.
How do rounding and numerical overflow/underflow affect simulations of the area?
In large-scale simulations with extremely large sample sizes, floating-point precision issues can arise. For instance, if X and Y have large magnitudes, X^2 + Y^2 can overflow for high-precision floats, though this is less common in standard double precision. Similarly, exponentiating negative numbers for the PDF can cause underflow if v/(2π) is large.
One mitigation strategy is to use log probabilities. For example, when computing f_V(v) = (1/(2π)) e^(-v/(2π)), you might track log f_V(v) = -ln(2π) - v/(2π) and exponentiate only when necessary. This ensures stable computations for large v. In practical big-data or simulation contexts, ignoring these numerical issues may lead to incorrect or misleading probability estimates.
How might we interpret this problem in a geometrical or application-based scenario?
A geometric interpretation is that if you pick a point at random in the plane with coordinates (X, Y) from a 2D Gaussian distribution, you then draw a circle centered at the origin passing through that point. The radius is the distance from the origin to (X, Y). The question about the distribution of the circle’s area arises, and we find it is exponentially distributed. In practice, one might use this to analyze radial distances in a 2D Gaussian field—for instance, in signal processing or anomaly detection, where radius thresholds define “contours” of equal probability density.
A subtle real-world pitfall is that some might confuse the circle we draw (which is random, due to the random radius) with the probability contours of a 2D Gaussian distribution. The 1-sigma, 2-sigma circles for a 2D Gaussian are deterministic in radius, whereas the random circle here depends on the outcome of X and Y themselves. Always distinguish between the distribution of a random radius and the fixed radii associated with contour lines in a Gaussian density.
What if we condition on the radius exceeding a certain threshold? How does that conditional distribution look?
Suppose we want the distribution of the area V given that V > a certain constant v0 (meaning the radius is greater than sqrt(v0/π)). For an exponential distribution with parameter 1/(2π), the conditional distribution remains exponential with the same parameter but shifted by v0. Formally, for v>v0:
P(V <= v | V > v0) = [P(V <= v) - P(V <= v0)] / [1 - P(V <= v0)].
Since V ~ Exponential(1/(2π)), this means:
P(V <= v | V > v0) = 1 - exp[-(v - v0)/(2π)].
This “memoryless property” is unique to exponential distributions. In real-world usage, a common pitfall is to assume memorylessness for distributions that do not have this property. If the distribution of the radius (or area) was not exponential, conditioning on large radii could change the tail shape significantly.