
ML Interview Q Series: Combatting Overfitting and Co-Adaptation in Neural Networks Using Dropout Regularization.

📚 Browse the full ML Interview series here.
4. Dropout Regularization: Explain how dropout works as a regularization technique in neural networks. What exactly happens during training when using dropout, and what changes in the model’s behavior during inference (deployment) time? Discuss how dropout prevents co-adaptation of neurons by randomly dropping units during training, and how at inference time all connections are used but with appropriately scaled weights.
How Dropout Works as a Regularization Technique Dropout is a powerful and widely used regularization strategy in neural networks. The fundamental idea is to reduce overfitting by intentionally “dropping” a certain percentage of neurons (or activations) randomly during training. In a standard dense or convolutional layer, each neuron can rely heavily on specific co-adaptations of other neurons to minimize the training loss. This can lead to overfitting because the network as a whole may learn very specialized patterns that do not generalize well to unseen data. Dropout alleviates this problem by forcing the network to learn more robust features that do not overly depend on specific, narrowly focused neuron interconnections.
Mechanics of Dropout in Training To implement dropout at training time, the network zeroes out (or “drops”) the outputs of certain neurons with some probability (often referred to as the dropout rate). For instance, if the dropout rate is 0.5, each neuron’s output is independently set to zero 50% of the time. Mathematically, one can treat it as sampling a mask from a Bernoulli distribution. If the output of a particular neuron is denoted as (h_i), then, with a dropout mask (m_i) sampled from a Bernoulli random variable with probability (p = 1 - \text{dropout rate}), the dropped output is:
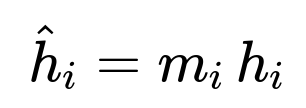
where
(m_i) is 1 with probability (p), and 0 with probability (1-p).
(p) is typically the “keep probability.” If the dropout rate is 0.5, the keep probability is 0.5.
During forward propagation, a new random mask is sampled at each mini-batch (and sometimes at each training example, depending on the implementation), effectively ensuring that a different sub-network architecture is used in each pass. This forces each neuron to learn representations that are helpful independently of the exact set of other neurons that might co-occur in the sub-network. Consequently, neurons must learn robust features that collaborate with a variety of different subsets of other neurons.
Model Behavior During Inference At inference time (i.e., once the model is deployed), no neurons are dropped. Instead, all connections are used, but in order to ensure consistency of the expected activations, the neuron outputs are scaled by the factor (p) (the keep probability). By multiplying the outputs by (p), the model approximates the effect of averaging the predictions of all possible sub-networks that were sampled during training.
One can view this as training an implicit ensemble of smaller networks and then at inference time combining all of them in a single forward pass. Scaling the weights or activations ensures that the magnitude of signals flowing through the network remains comparable to what the network experienced on average during training.
Why Dropout Prevents Co-Adaptation Without dropout, certain sets of neurons could learn to rely heavily on each other, forming strong co-adaptations that may not generalize beyond the training set. By randomly removing neurons and their connections during training, a neuron is less likely to depend on a specific subset of other neurons. Instead, it develops features that are broadly useful across many potential contexts. This yields a more generalized set of features that contribute to improved performance on unseen data.
Practical Implementation Details One can implement dropout easily in popular deep learning frameworks such as PyTorch or TensorFlow. Below is a simple example in PyTorch:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleNetwork(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, dropout_rate=0.5):
super(SimpleNetwork, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.dropout = nn.Dropout(p=dropout_rate)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.dropout(x) # dropout only applied during training
x = self.fc2(x)
return x
model = SimpleNetwork(input_dim=100, hidden_dim=50, output_dim=10, dropout_rate=0.5)
When you call model.train(), PyTorch automatically applies dropout using the specified rate. When you switch to model.eval(), dropout is disabled, and the framework internally scales the neuron outputs to match the expected activation magnitude.
Subtle Issues and Edge Cases One should choose the dropout rate wisely. Too high a dropout rate can degrade performance because the network effectively becomes too sparse, making training more difficult. Too low a rate might not provide enough regularization. Common choices range from 0.1 to 0.5, though the best value usually depends on the task, architecture, and dataset. Moreover, dropout can be applied to different layers, including inputs, hidden layers, or even convolutional filters. Careful experimentation is often needed to find the most effective approach for a particular network design. Dropout is generally more common in fully connected layers; in convolutional layers, spatial dropout variants sometimes provide better results by dropping entire feature maps.
Effects of Dropout on Model Predictions By training many random sub-networks (implicitly), dropout helps the model reduce variance in its predictions. Consequently, the model becomes more robust to perturbations in the input data. It also lowers the chance that a few neurons that detect overly specific patterns dominate the decision. In essence, dropout fosters a more diverse representation in the hidden layers, improving the model’s ability to generalize.
Potential Pitfalls If the batch size is extremely small, the randomness introduced by dropout can sometimes destabilize training. Additionally, applying dropout in recurrent networks (like RNNs, LSTMs, or GRUs) must be done carefully (e.g., using techniques like variational dropout) to maintain consistency across time steps. Another caveat is that if a network is already heavily regularized (for example, with strong weight decay and data augmentation), adding too much dropout can hurt performance or slow down convergence.
Use in Combination with Other Regularization Methods Dropout is often used in combination with other techniques such as weight decay ( regularization), batch normalization (though one must carefully tune the combination of dropout and batchnorm), and data augmentation. Each method regularizes the model in a slightly different way. When used prudently, these techniques can complement each other without redundancies.
Common Follow-up Question: How is Dropout Different from Early Stopping and Regularization?
Early stopping halts training before the model overfits, relying on validation loss or other metrics to determine when overfitting starts. It does not directly alter the model parameters or architecture during training; it just stops the optimization process early. By contrast, dropout actively modifies the network during training, dropping random activations to reduce co-adaptations. regularization discourages large weights by adding a penalty to the loss function. Dropout, on the other hand, randomly zeroes out activations, effectively limiting how strongly neurons can rely on specific other neurons during training. These methods can be used together.
Common Follow-up Question: Why Scale Weights at Inference Time Instead of Keeping Dropout?
If one were to keep dropping neurons at inference time, the network’s predictions would be stochastic and lower in magnitude on average compared to training. This could lead to unpredictable performance and hamper reproducibility. By using all neurons and scaling them appropriately, the model reintroduces the entire representational capacity. The scaling factor ensures that the expected outputs during inference match the average activations observed during training, preserving performance while eliminating random fluctuations.
Common Follow-up Question: Does Dropout Work Well in All Types of Networks?
Although dropout is powerful, it may not be the best option in every scenario. In convolutional neural networks, batch normalization and other forms of regularization can sometimes provide enough stability, and high dropout rates can overly hamper performance. In recurrent networks, one might consider specific variants like “variational dropout” to ensure consistent dropout masks over time steps. Thus, while dropout can be quite beneficial, the design choice depends on the network architecture and problem domain.
Common Follow-up Question: How to Choose the Dropout Rate?
Practitioners often start with a dropout rate of 0.5 in fully connected layers. For some tasks, a smaller rate like 0.2 or 0.3 might suffice. In deeper architectures, different layers may benefit from different dropout rates. It is a hyperparameter that typically requires validation set tuning. A well-managed hyperparameter search, or domain knowledge about the network’s capacity and data complexity, can guide its final selection.
Common Follow-up Question: How Does Dropout Affect Training Speed and Memory Usage?
During training, dropout introduces random masks, which is computationally negligible in modern frameworks. The main effect is that the effective batch gradient is computed on a randomly thinned network, and this does not significantly increase memory usage. However, one might see slower convergence in some cases because the network must learn robust features under varying sub-network configurations. This can sometimes be mitigated by using a slightly higher learning rate or other training heuristics, but these details are highly architecture and problem dependent.
Common Follow-up Question: Why Not Drop the Weights Instead of Neuron Outputs?
Randomly dropping entire weights instead of outputs is a related idea (like DropConnect). However, dropping neuron outputs (standard dropout) is more common. When you drop the output of a neuron, you remove its entire contribution. Dropping individual weights is a sparser and more granular operation, which can be beneficial in some cases but can also complicate implementation. Standard dropout is effective, easier to implement, and widely supported in deep learning frameworks.
Common Follow-up Question: Is Dropout the Only Way to Achieve Ensemble-Like Behavior?
Dropout can be thought of as training many sub-networks simultaneously, which leads to an approximate ensemble prediction at test time. Another approach is to train multiple independent models and ensemble them at inference, but that is more expensive in both training and inference. Dropout is relatively efficient because it collapses the ensembling into a single pass at inference time, with a simple scaling of the neuron outputs.
Common Follow-up Question: Do We Always Disable Dropout at Inference in Practice?
Yes, typically dropout layers are turned off at inference. However, there is a concept called “test-time dropout,” sometimes used for Bayesian uncertainty estimation. In that scenario, we keep dropout active during inference to produce multiple stochastic forward passes, generating a distribution over outputs. This helps to quantify uncertainty, but it is a special use case. For standard deterministic deployment, dropout is disabled, and all neurons remain active with scaled weights or outputs.
Common Follow-up Question: Could Dropout Hurt Performance If the Dataset Is Very Small or Very Large?
For small datasets, dropout can help reduce overfitting. However, if the dataset is extremely tiny, too high a dropout rate may remove too many features at once, destabilizing training. On the other hand, for very large datasets, overfitting is less severe, and regularization needs might differ. Practitioners might opt for data augmentation, weight decay, or batch normalization before deciding if heavy dropout is necessary. There is no universal rule, and experimentation remains crucial.
Common Follow-up Question: How Does Dropout Interact with Batch Normalization?
Batch normalization normalizes layer inputs based on the current mini-batch’s statistics and a running average of means and variances. Applying dropout before or after batch normalization can change the statistics that BN sees. Some practitioners do not use dropout at all when they employ BN, while others place dropout after the activation following BN. The arrangement is somewhat empirical: in many modern CNN architectures, dropout usage is reduced in favor of BN, although in fully connected layers, dropout remains common. If both are used, hyperparameter tuning is essential to find a stable configuration.
Common Follow-up Question: Are There Variants of Dropout for Convolutional Layers?
Convolutional layers have spatial structure. Dropping individual activations in a convolutional layer can sometimes create unnatural patterns in feature maps. Spatial dropout (sometimes called 2D dropout) drops entire channels or contiguous regions in feature maps, preserving the spatial correlation within a channel while removing entire channels at random. This can yield stronger regularization for convolutional networks. Another variant is channel dropout, in which entire feature map channels are dropped at random. These techniques can be more effective in certain computer vision tasks.
Common Follow-up Question: How Could One Validate That Dropout Is Effectively Reducing Overfitting?
One way is to look at training vs. validation accuracy curves. Overfitting typically manifests as a high training accuracy with a lower (and diverging) validation accuracy. Introducing dropout should reduce the gap between them by curbing the model’s ability to memorize the training data. If done correctly, the validation accuracy should improve or at least remain stable, and the gap to training accuracy should diminish. Additionally, monitoring metrics like calibration error or the model’s behavior on unseen data can give insights into whether dropout is helping.
Common Follow-up Question: Can Dropout Be Applied to Recurrent Connections?
Yes, but it needs to be done carefully. In many frameworks, a naive application of dropout in RNNs can produce undesirable side effects because the random mask is re-sampled at every time step, disrupting temporal correlations. Variational dropout addresses this by sampling a single dropout mask per training sequence, keeping it consistent across time steps. LSTMs or GRUs often include built-in dropout options that do this. However, one has to verify the exact implementation, as different frameworks might handle recurrent dropout differently.
Common Follow-up Question: When Should We Not Use Dropout?
In certain architectures—like transformer-based models that rely heavily on attention mechanisms—large-scale pretraining plus layer normalization and residual connections might supply sufficient regularization, so dropout might be less critical or used only in specific layers. Another situation might be extremely small networks or tasks where underfitting is the main issue. In such cases, adding more regularization (like dropout) could worsen underfitting. Therefore, it is best to evaluate whether a model truly benefits from dropout rather than including it by default.
Common Follow-up Question: Is There Any Theoretical Basis for Why Dropout Performs So Well?
One viewpoint is that dropout approximates training a large ensemble of networks that share weights. Each subset of neurons forms a slightly different network, and this randomness acts as a strong regularizer. The averaging effect of these sub-networks at inference time stabilizes predictions. Additionally, from an information-theoretic perspective, dropout injects noise that forces the network to learn more robust, generalizable features. While a complete theoretical characterization can be intricate, empirical evidence and partial theoretical models strongly support dropout’s effectiveness as a regularizer.
Common Follow-up Question: How Does Dropout Compare to Data Augmentation for Vision Tasks?
Data augmentation is another way to reduce overfitting, typically by expanding the effective dataset size through random transformations (e.g., flips, crops, rotations). These methods regularize the model from the data side, teaching it invariances and robust representations. Dropout, on the other hand, regularizes the model by introducing internal noise in the hidden activations. Both can be used together: data augmentation ensures the network sees more diverse inputs, while dropout reduces reliance on any particular co-adaptation in the internal representations. Often, combining these approaches yields strong improvements over either technique alone.
Common Follow-up Question: Could Dropout Interfere with Gradient Flow?
Dropout zeroes out random activations, which can affect the gradient flow through those neurons. However, because the dropped neurons do not contribute to the forward pass, they similarly do not receive gradients for that pass. Across many training steps, all neurons should still get sufficient updates on average. If the network is extremely deep or the dropout rate is very high, gradient flow might become more challenging, so one should balance the dropout rate and network architecture for stable training.
Below are additional follow-up questions
Could Dropout Be Used at the Input Layer for Dimensionality Reduction or Data Augmentation?
Dropout can indeed be applied to the input layer, sometimes called "input dropout," though its motivation differs slightly from dropout in hidden layers. Traditionally, dropout is used in hidden layers to reduce co-adaptation by removing random neurons. When applied to the input layer, dropout randomly zeroes out portions of the raw input features. This can act as a form of data augmentation, since the model effectively sees perturbed versions of the input. It might also behave similarly to dimensionality reduction in that it forces the network to rely on many different subsets of the input dimensions over the course of training.
In practice, however, dropping a large fraction of the input features can sometimes hurt performance if the model heavily depends on fine-grained features to make accurate predictions. If the dropout rate at the input layer is too high, the model might fail to learn sufficient detail about the data distribution. On the other hand, a moderate dropout rate (e.g., 0.1 to 0.2) in the input layer can help in scenarios where:
The dataset is relatively small, and overfitting is significant.
The model can handle partial feature corruption gracefully (e.g., certain NLP tasks might see partial words dropped, but contextual embeddings can still fill in meaning).
One wants to simulate scenarios of missing features to make the model robust to incomplete or noisy data.
Potential pitfall: If the input features have very different degrees of importance for the task, input dropout could disproportionately remove critical features, especially with a high dropout rate. This can lead to slow or unstable learning. Hence, one must empirically verify the benefits of input dropout and tune the dropout probability carefully.
How Does Dropout Affect Interpretability Methods Such as Saliency Maps or Feature Attribution?
When using techniques like saliency maps, integrated gradients, or class activation mappings to interpret network decisions, dropout can introduce noise into which neurons or activations are utilized at training time. By forcing the network to learn distributed representations (because no single neuron can rely on specific co-adaptations), the salient regions might become more spread out across multiple neurons.
During inference (where dropout is typically off), interpretability methods will look at the entire network without active dropout masks. Thus, the final saliency or attribution might be more stable in well-regularized models compared to heavily overfit ones. However, one subtle issue arises if an interpretability method requires multiple forward passes (e.g., using dropout at test time to estimate model uncertainty). In that scenario, the randomness from dropout can alter the saliency or attribution for each pass.
Potential pitfall: If someone accidentally leaves dropout on (e.g., forgetting to switch to eval mode in PyTorch) while generating saliency maps, the interpretability results could vary with each forward pass. This could make it more difficult to analyze or compare results. The best practice is typically to disable dropout for a standard deterministic interpretability procedure, unless the goal is specifically to measure uncertainty or variability in the attributions.
What Happens If We Forget to Scale Activations at Test Time After Using Dropout in Training?
The mathematics of dropout typically expects that at test (inference) time, the outputs of neurons are scaled by the keep probability. If one forgets to do this scaling (or if the framework does not handle it automatically), the activations at inference will be higher than what the network “expects.” For example, if a layer was trained with a dropout rate of 0.5, the keep probability (p) is 0.5. During training, each neuron’s output is zeroed out half of the time on average, so effectively the network sees half the activation in expectation. If we then use all neurons at test time without scaling, we effectively double the activation magnitudes. This mismatch can severely degrade inference performance.
Fortunately, modern deep learning frameworks like PyTorch or TensorFlow handle the scaling automatically when switching between training and evaluation modes. For instance, in PyTorch, when you call model.eval(), dropout layers will no longer drop activations and do the internal scaling as intended. The user does not need to manually scale weights unless they are doing custom dropout logic.
Potential pitfall: Implementing dropout manually (for example, writing your own forward pass with random masks) can lead to forgetting the scaling step. This results in test-time predictions that are systematically biased. Verifying your test-time performance matches the scale of training-time expectations is crucial to avoid such pitfalls.
When Is It Beneficial to Apply Dropout in Only Certain Layers Rather Than All Layers?
Not all layers benefit equally from dropout. For many architectures, applying dropout to every single layer can be excessive or may harm performance, especially in networks with batch normalization or residual connections. Practitioners often find the most benefit from applying dropout:
After fully connected (dense) layers in deep networks, where co-adaptation is often more pronounced.
Towards the end of the network, where feature abstraction is highest and overfitting can be more prominent.
In extremely large hidden layers where the capacity is excessive relative to the dataset size.
Conversely, some layers might be harmed by dropout, such as early convolutional layers that capture low-level features. In these layers, a different regularization strategy (like small kernel sizes, weight decay, or data augmentation) may be more suitable. Applying dropout to the very first layers of a CNN can degrade the learning of critical local structures such as edges or color gradients. For RNNs or Transformers, specialized dropout patterns (like attention dropout, hidden state dropout, or feed-forward dropout) may already be built-in and tuned.
Potential pitfall: If you randomly apply dropout at too many places or with too high a rate, your network might underfit or fail to converge. Balancing the dropout locations and rates often requires empirical experimentation. Blindly applying dropout everywhere can lead to an overly regularized model.
Could Dropout Be Detrimental in Certain Architectures, Such as Very Wide Networks or Very Small Networks?
Yes, dropout can sometimes hinder performance in very wide or very small networks. In very small networks with limited capacity, dropping many neurons at once can cause the model to underfit because it lacks enough representational power to begin with. For extremely large or wide networks, other forms of regularization (like strong weight decay, batch normalization, or improved data augmentation) may be more effective and stable.
For instance, in wide residual networks for image recognition, researchers often rely heavily on batch normalization and data augmentation, finding that dropout might not significantly improve performance—or it might be used only in the final layers. On the other hand, small networks that are already prone to underfitting may see no benefit (or even worse performance) if the dropout rate is not carefully tuned.
Potential pitfall: Overly wide networks combined with a high dropout rate can lead to slow training convergence. The optimization algorithm can struggle when the effective network architecture changes drastically from iteration to iteration. If used incorrectly, dropout can overshadow the benefits of having a wide architecture or a small, carefully tuned model.
How Does Dropout Compare to Techniques Such as Scheduled Dropout or DropConnect?
Scheduled dropout (or “dropout scheduling”) involves varying the dropout rate over time. For example, one may start with a higher dropout rate early in training to aggressively regularize and gradually reduce it as training progresses, allowing the network to refine its learned representations more precisely. Some claim this can provide a better trade-off between strong initial regularization and final convergence. Similarly, cyclical dropout schedules can be employed, though results can be dataset-dependent.
DropConnect, on the other hand, randomly drops individual weights (rather than entire neuron outputs), effectively creating a different “sparsified” weight matrix at each iteration. This can be more granular and sometimes provides stronger regularization, but it is typically more complex to implement and less common in practice than standard dropout.
Potential pitfall: Overly complex dropout schedules or advanced variants can make training behavior harder to interpret. Tuning these hyperparameters (e.g., the schedule shape, the maximum/minimum rates, the transition epochs) can become quite involved, and it is easy to over-regularize or under-regularize if the schedule is not carefully calibrated.
How Can We Debug if Dropout Is Causing Training Instability or Hurting Performance?
One systematic way to debug is to compare three training runs:
Baseline: No dropout at all.
Dropout: The intended dropout configuration.
Reduced dropout: Lower dropout rate than the intended setting.
By checking the validation and training accuracy curves, one can see if the dropout version is diverging, converging slower, or failing to match baseline performance in a situation where overfitting is not your biggest concern. If the model with dropout drastically lags behind the baseline in training performance yet does not improve validation scores, it suggests that dropout might be too aggressive or placed in an unhelpful part of the network.
One can also look at gradient norms or monitor how quickly the loss decreases in the early epochs. If early training struggles, you might try decreasing the dropout rate, relocating dropout layers, or adjusting the optimizer settings (like a slightly higher learning rate or different momentum).
Potential pitfall: If you suspect dropout is harming performance, double-check you are toggling train() and eval() modes correctly in your framework. A common bug is forgetting to switch to eval mode for inference or forgetting to switch back to train mode—leading to unexpected behaviors.
Is Dropout Still Beneficial When the Dataset Is Extremely Large with Extensive Data Augmentation?
Dropout can still help in large-scale settings. Even with substantial data augmentation, neural networks can be prone to overfitting if the architecture is extremely high-capacity (e.g., large Transformer models). Many popular architectures retain some form of dropout in their design (e.g., dropout in the feed-forward layers of a Transformer) to prevent over-reliance on certain pathways.
However, one might find that as dataset size grows, the network requires less aggressive regularization. When you have hundreds of millions of training samples, the natural variety in the data plus robust data augmentation might already act as strong regularizers. In that scenario, dropout rates are often set lower than they would be for smaller datasets. Alternatively, an architecture might omit dropout in some layers, relying on other regularization approaches such as weight decay, label smoothing, or advanced normalization methods.
Potential pitfall: Large-scale models with minimal dropout may still overfit certain domain-specific artifacts if the data distribution is skewed or not as diverse as presumed. It is always wise to validate any assumption about not needing dropout. The presence of extensive data does not automatically eliminate overfitting potential.
How Do We Handle Dropout with Large Batches Versus Small Batches?
The batch size can influence how dropout noise interacts with the training process. With small mini-batches (e.g., batch size of 8 or 16), the random dropping of neurons can cause high variance in the gradient estimates. This might lead to training instability or require a more cautious tuning of hyperparameters like the learning rate. Conversely, with very large mini-batches (e.g., batch size of 1024 or more), each batch average might “smooth out” the random effect of dropout, leading to more stable learning.
In small-batch scenarios, you might consider:
Reducing the dropout rate slightly so that the model does not see an overly sparse set of activations in each step.
Lowering the learning rate to compensate for the increased variance in gradient updates.
Potential pitfall: If you scale the batch size drastically without adjusting other hyperparameters (learning rate, momentum schedule, etc.), the interplay with dropout might produce suboptimal convergence. For instance, a very large batch size plus a strong dropout rate can lead to slower training or suboptimal minima if the learning rate is not properly scaled. Always re-tune dropout rates when changing the batch size significantly.
Does Dropout Help with Out-of-Distribution Detection or Adversarial Robustness?
Some research suggests that standard dropout may not inherently solve out-of-distribution detection or adversarial robustness issues. However, it can slightly improve robustness by discouraging reliance on narrow sets of features. There are specialized variants (e.g., Monte Carlo dropout) that keep dropout active during inference and produce multiple stochastic predictions to quantify uncertainty. That approach can help detect out-of-distribution samples if the model’s predictions exhibit high variance across stochastic passes.
For adversarial robustness, dropout alone is generally insufficient as a defense against well-designed adversarial attacks. Attackers can often craft perturbations that remain effective despite random dropout masks. More specialized defenses, such as adversarial training, are typically needed to robustly address adversarial examples.
Potential pitfall: Relying solely on dropout for out-of-distribution or adversarial detection can give a false sense of security. While some uncertainty-aware methods use dropout at test time, they do not guarantee strong adversarial protection unless combined with more robust training strategies or specialized detection mechanisms.
How Do We Approach Applying Dropout in Residual Networks (ResNets) or Transformers Where Residual Connections Are Critical?
Residual networks and Transformers rely heavily on skip connections that pass information forward unchanged, helping with gradient flow and stable training in deep architectures. Introducing dropout in these connections can disrupt the careful balance of information flow. Typically, practitioners insert dropout in specific locations where it will not break the essential identity mappings:
In a ResNet, it is common to put dropout in the fully connected (classification) head, or occasionally within the convolutional blocks in a carefully orchestrated manner.
In Transformers, standard practice includes attention dropout, which randomly zeroes out some attention weights, and feed-forward dropout, which randomly zeroes some hidden units in the feed-forward sublayer. However, the skip connections themselves usually remain intact without direct dropout.
Potential pitfall: If someone tries to apply dropout directly to the residual path in an unstructured way, it can lead to difficulties in optimization. For instance, if you zero out entire skip connections frequently, the deeper layers might not receive the stable signals they need from earlier layers. This can cause training to stall or degrade performance.
What Happens if We Increase the Dropout Rate Too Late in Training?
If one decides to change the dropout rate mid-training (e.g., you start with a low rate and then suddenly raise it), the network parameters may have already adapted to a certain level of noise. A sudden increase in the dropout rate can disrupt previously learned representations, causing a sharp increase in training loss, sometimes leading to partial catastrophic forgetting of what was learned in earlier epochs. On the flip side, gradually increasing the dropout rate in a “scheduled” manner might allow the network to adapt incrementally.
Potential pitfall: Abrupt changes to the dropout rate can destabilize training unless carefully planned and accompanied by an adjustment of the learning rate or other hyperparameters. If you see performance drop after raising the dropout rate, that might indicate the network was too dependent on certain co-adaptations that now get zeroed out more frequently.
Are There Tasks Where Dropout Might Be Counterproductive, Such as Autoencoders or Generative Models?
Certain tasks, like autoencoders or generative models (e.g., VAEs, GANs), might not benefit from dropout in the same way discriminative models do. Autoencoders already learn to reconstruct their input, and corrupting the hidden representations can conflict with the training objective unless it is explicitly part of the design (as in denoising autoencoders). In generative models, dropout might complicate the balance between generator and discriminator, especially in GANs, leading to instability.
That said, some generative setups do use dropout effectively, but it requires careful placement and consideration. If the core objective is to capture detailed structures of the input distribution, randomly zeroing out neurons might degrade generative quality. On the other hand, for denoising autoencoders, dropping inputs or hidden units is precisely the point, and that can help them learn robust features.
Potential pitfall: Blindly applying dropout to a generative model might cause mode collapse in GANs or poor reconstructions in certain autoencoders. Always verify whether the objective can tolerate or benefit from the additional noise introduced by dropout.
How Could Mixed Precision or Quantization Interact with Dropout?
Mixed precision training uses half-precision (FP16 or BF16) for certain operations to speed up training. This typically does not conflict heavily with dropout, as the random mask multiplication is straightforward and numeric precision is rarely compromised. However, it is important to ensure that the scaling of activations is handled consistently for both forward and backward passes. In practice, frameworks that support mixed precision handle dropout seamlessly without special user intervention.
Quantization (reducing weights and activations to lower bit depths) might require awareness of how zeros introduced by dropout interact with quantized values. Zeros are typically represented exactly, so that part is not problematic. However, if the dynamic range of a layer’s activations is heavily reduced by dropout, the quantization algorithm must ensure it does not overly compress or saturate the remaining non-zero activations.
Potential pitfall: If the quantization calibration process is done in a mode where dropout is not disabled, it might calibrate the scales or ranges incorrectly, anticipating more zeroed-out channels or activations than will actually occur at inference (when dropout is off). This discrepancy can degrade quantized performance. It is therefore standard to disable dropout during quantization calibration or to replicate the exact inference environment.
Can We Use Dropout to Handle Missing Data at Inference Time?
While dropout introduces random data corruption at training time, it does not automatically handle missing data at inference. If your inference inputs have truly missing features, you cannot rely on dropout to fix or impute them. Dropout is a training regularization technique, not a direct solution for test-time missing feature imputation. However, the robustness learned from dropout training can sometimes help the model handle partial corruption or random noise in the test data a bit better, but it is not a guaranteed or systematic approach to missing data.
Potential pitfall: Confusing training-time random dropout with the actual real-world scenario of missing data can lead to suboptimal solutions. If missing data is a genuine concern in your domain, you should explore specialized methods like data imputation, domain-specific preprocessing, or model architectures designed to handle partial observations (e.g., flexible mask-based attention for missing tokens in NLP).