
ML Interview Q Series: Definition of bias in ML, causes of bias in LLMs, and methods to reduce bias.


📚 Browse the full ML Interview series here.
Comprehensive Explanation
Bias in machine learning refers to the systematic deviation of a model’s outputs or predictions from the true underlying patterns of data, often resulting in unfair or skewed outcomes when the model is deployed in real-world scenarios. In the context of large language models, bias can manifest as stereotypes, harmful associations, or unbalanced representations of certain groups.
One way to mathematically view bias is through the lens of the bias-variance decomposition of the mean squared error (MSE). While not the only way to interpret bias, it is a commonly used framework in basic ML theory.
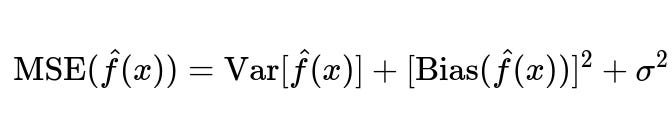
Here, Var[\hat{f}(x)] represents how much the model’s predictions fluctuate around their mean prediction across different training sets. Bias(\hat{f}(x)) indicates the difference between the average prediction and the true value. And sigma^2 is irreducible noise in the data. For large language models, bias can appear in the parameters themselves when they systematically produce disproportionate or skewed content about certain topics or demographics.
Factors that give rise to biases in large language models include the nature of the training data (which may already contain societal stereotypes or imbalances), how the model’s training objective is formulated (such as masked language modeling possibly amplifying dominant narratives), and reinforcement learning steps that might inadvertently align the model more with the viewpoints of those providing the feedback rather than an objective ground truth.
Mitigating bias in ChatGPT or any large-scale language model entails carefully addressing data collection, model training, and refinement processes. These strategies include curating balanced datasets, employing debiasing algorithms, applying rigorous evaluation metrics, and using oversight or post-processing filters to reduce the risk of harmful responses. Different teams may also employ alignment techniques such as Reinforcement Learning from Human Feedback (RLHF) to fine-tune the model’s outputs to align with ethical and fairness guidelines.
How Bias Emerges in Large Language Models
Bias can stem from data, modeling choices, and even from subtle feedback loops:
Data Imbalance and Representation Large language models often consume massive text corpora gathered from the internet. These corpora can inherently over-represent certain groups or under-represent others, leading to an asymmetric view of the world encoded in the model’s weights. If, for instance, certain minorities are discussed only in negative or rare contexts in the training data, the model may learn undesirable or misleading patterns.
Historical and Societal Influences Language data reflects historical or cultural biases that exist in society. Models trained on such data can inherit and even amplify these biases, especially if the training objective unconsciously gives more weight to prevalent or frequently repeated associations.
Feedback Loops When users interact with large language models, their feedback or usage patterns can bias future iterations of these models. For instance, if certain prompts that reflect offensive viewpoints become frequent, a new fine-tuning cycle might reinforce these perspectives, unless explicitly controlled for during data cleaning or model alignment.
Model Architecture and Training Objective Some architectural choices or training paradigms might unintentionally magnify biases. In certain generative tasks, the model might place disproportionate emphasis on patterns that are more easily predictable (e.g., popular narratives about particular groups). If the training objective or the token distribution is skewed, biases can become more pronounced.
Approaches to Mitigate Bias in ChatGPT
Addressing bias requires interventions at multiple stages of the pipeline, from the initial data gathering to final model deployment:
Careful Data Collection and Preprocessing Constructing balanced corpora where possible is a key step. While perfect balance is often unattainable at scale, thorough data audits can reduce overt representation imbalances. Techniques like data augmentation can also be used to ensure broader coverage of under-represented groups.
Debiasing Algorithms Certain methods attempt to remove or lessen the associations that connect protected group tokens (e.g., gender, race, religion) with negative stereotypes. These can involve adversarial training, where a secondary model detects bias and encourages the primary model to produce more neutral representations. Another example is projection-based debiasing, where directions in the model’s embedding space corresponding to protected attributes are identified and neutralized.
Refining Training Objectives Instead of pure likelihood-based language modeling, specialized objectives that emphasize fairness or neutrality can be used. Sometimes this means re-weighting loss terms to penalize biased associations more heavily. Alternatively, specialized approaches can incorporate group fairness objectives or perform multi-task learning to reduce the model’s reliance on spurious correlations.
Human-in-the-Loop Alignment Large-scale language models like ChatGPT often undergo an additional fine-tuning phase informed by human feedback. This is Reinforcement Learning from Human Feedback (RLHF). Human evaluators provide direct input on which outputs are undesirable or harmful. The system is then adjusted to avoid these outputs or at least flag them. This process can be extended with specialized “red-teaming” methods, where a diverse set of users tries to intentionally elicit biased or harmful responses, to expose vulnerabilities that can be rectified before broader release.
Post-Processing Filters After generating a response, additional filters or classifiers can scan the output for potential biased or offensive content. If such content is identified, the system can either revise the response, provide a warning, or refuse to respond. This approach can catch certain mistakes that slip through earlier debiasing steps.
Continuous Monitoring and Iteration Bias mitigation is not a one-time fix. As models are retrained on updated data or fine-tuned over time, new biases can arise or old biases can resurface. Continuous evaluation using bias detection metrics and routine audits helps ensure that bias remains as low as possible throughout the model’s lifecycle.
Could There Be Trade-offs Between Reducing Bias and Preserving Accuracy?
Reducing bias can sometimes introduce trade-offs. By forcing a model to produce more balanced outputs, there are scenarios where certain frequent patterns from the training set might be de-emphasized. For instance, if a model is systematically overlooking subtle patterns that are important in predicting outcomes for certain groups, a naive debiasing technique might inadvertently degrade performance for everyone. This is why careful measurement of both fairness and predictive accuracy is essential. Properly designed approaches, such as including fairness constraints while training, can preserve model utility while diminishing harmful biases.
Is There a Standard Metric for Quantifying Bias in Large Language Models?
Various metrics attempt to quantify bias. They often measure how differently the model handles or associates certain demographic tokens (like male vs. female names, majority vs. minority groups) with specific sentiments or contexts. Examples include:
• Word embedding association tests, which measure the strength of associations between demographic identifiers and certain sets of attribute words. • Generated text evaluations, where evaluators or automated tools assess the model’s output for bias when given standardized prompts.
In practice, no single metric is universally accepted. Different teams rely on a mixture of qualitative analyses, user feedback, and automated tests tailored to their domain.
How Do We Distinguish Between Harmless Stereotypes and Harmful Bias?
Distinguishing a trivial stereotype from a harmful one can be complex and context-dependent. Harmless stereotypes might be those that are more neutral or do not adversely affect the rights, opportunities, or dignity of a group (e.g., saying that “Certain regions have warmer climates” is a broad statement that may have limited social implications). On the other hand, harmful biases can perpetuate discrimination, cause emotional distress, or reflect prejudiced assumptions (e.g., attributing undesirable traits to specific racial groups without justification). Domain experts, ethicists, and stakeholder groups typically collaborate in large organizations to define guidelines that clarify these distinctions and identify harmful content that must be mitigated.
Could You Provide a Simple Python Code Example Illustrating a Debiasing Step?
One straightforward approach for word embeddings is to remove or minimize the direction correlated with certain attributes (e.g., gender) from embeddings. Below is a simplified example using Python-like pseudocode:
import numpy as np
# Suppose we have an embedding matrix 'W' where each row is a word embedding
# and a vector 'gender_direction' that identifies the gender axis.
def neutralize_embedding(W, gender_direction):
# Normalize the gender direction
gender_unit = gender_direction / np.linalg.norm(gender_direction)
# Project each embedding onto the gender direction and remove the projection
for i in range(W.shape[0]):
projection = np.dot(W[i], gender_unit) * gender_unit
W[i] = W[i] - projection # remove the gender component
return W
# This simplistic approach tries to remove the dimension of 'gender_direction'
# from all word embeddings, thereby reducing explicit gender associations.
In practice, real-world scenarios require more nuanced solutions, and extensive evaluation is necessary to ensure that the overall semantic quality of embeddings remains good while also reducing bias.
How Does Reinforcement Learning from Human Feedback Help in Mitigating Bias?
Reinforcement Learning from Human Feedback (RLHF) is a powerful alignment technique. After the large language model is trained, a separate step is introduced where human annotators provide feedback on generated text. These annotations might highlight undesirable biases, harmful content, or other quality issues. A reward model is then trained to predict these human preference signals, and the main language model is fine-tuned to optimize this reward. By continually focusing on reducing dispreferred outputs, the model can learn to avoid generating biased or offensive language while still preserving fluency and coherence.
Summary of Key Insights
Bias in machine learning arises when the model systematically deviates from representing or treating different inputs fairly, often reflecting societal stereotypes or data distribution imbalances. Large language models inherit these biases from the massive text data they consume and from their training objectives. Effectively mitigating bias involves a pipeline of careful data collection, algorithmic debiasing, alignment with human values through techniques like RLHF, and continuous monitoring. Despite these efforts, bias mitigation remains an ongoing challenge requiring collaboration among data scientists, ethicists, and domain experts.
Below are additional follow-up questions
What is the role of intersectionality in detecting and mitigating biases, and how can it complicate debiasing efforts?
Intersectionality recognizes that individuals or groups can be disadvantaged by multiple axes of identity simultaneously, such as race, gender, age, socioeconomic status, and more. When these intersect, they can compound or alter how bias manifests. For instance, techniques that address gender bias in a generic sense may not effectively remedy bias against people who belong to both an underrepresented gender and a marginalized racial group. This complexity can lead to scenarios where a model that seems fair when evaluating gender and race separately fails to account for those who exist at the intersection of both categories.
A pitfall here is that many bias metrics focus on singular attributes (e.g., only race or only gender). If a dataset is small for individuals at certain intersections (e.g., older women of a particular ethnic background), the model might perform worse for that subgroup. The challenge is ensuring that debiasing is thorough while balancing computational constraints and data availability. Without sufficient representation of each intersection in the training set, the model risks overlooking rare but critical demographics.
In practice, addressing intersectionality involves: • Collecting richer datasets that annotate multiple demographic attributes without breaching privacy. • Evaluating model performance and bias metrics across combined subgroups (e.g., race+gender+age). • Designing fairness objectives that penalize poor performance for any intersectional subgroup, even if that subgroup is low in frequency.
However, intersecting these attributes can quickly create many subcategories and exacerbate data sparsity. Careful sampling, data augmentation, or synthetic data generation may be required, but such interventions must be carried out responsibly to avoid introducing artificial or misleading patterns.
How can we identify implicit vs. explicit bias in large language model outputs, and why is this distinction important?
Explicit bias is relatively straightforward to detect because it manifests as overtly negative or stereotypical statements about a protected group. Implicit bias, however, may appear in subtle ways: a model might produce consistently more positive or authoritative descriptions for one group compared to another, without using obviously offensive language. For example, a model may portray a certain group as perpetually in need of help or less competent than others. The difference can be detected through nuanced analyses or specialized test prompts.
The distinction matters because a system that avoids explicit slurs or hateful remarks may still amplify stereotypes or produce systematically skewed portrayals. Relying exclusively on profanity filters or toxicity detection can miss these subtler biases. Understanding implicit bias requires analysis of model behaviors across numerous prompts and context-specific usage to see patterns in how the model frames certain groups or issues.
Potential pitfalls include: • Overlooking subtle bias if the only evaluation metric is explicit hate-speech detection. • Difficulties in measurement: implicit associations may require extensive test sets and creative prompts to reveal. • Risk of false positives: not all differences in language usage are necessarily harmful, so it’s crucial to interpret patterns carefully.
When might over-correction or “erasure” of certain attributes become a problem during debiasing, and how do we address it?
Over-correction or “erasure” refers to the scenario where a debiasing technique removes or blurs any mention of protected attributes, resulting in a system that avoids discussing these attributes at all. This can be problematic because ignoring demographic factors can itself be a form of bias. For instance, in some medical or social contexts, certain groups face specific challenges that legitimately need to be recognized to provide accurate recommendations or responses.
The main challenge is that some form of attribute awareness can be beneficial or even necessary for equitable outcomes. If a model is completely purged of any knowledge about, say, race or gender, it may fail to address group-specific concerns or respond effectively to questions related to those attributes.
Addressing it requires: • Fine-grained debiasing methods that remove harmful stereotypes without erasing valuable information. • Constructing a robust fairness objective that balances avoiding negative associations while retaining the ability to handle legitimate contexts. • Close domain expert involvement to decide when attribute references are appropriate and non-discriminatory.
A potential pitfall occurs if the team sets out to eliminate all potential bias signals by removing any demographic terms from the training set. This might inadvertently degrade the model’s performance on tasks that legitimately need these concepts (e.g., “What health screenings might be more relevant for group X?”). Finding the right balance is a nuanced process that often requires iterative refinement and feedback from diverse stakeholders.
Can the distribution shift in real-world data lead to emergent biases that were not observed during training, and how do we manage that risk?
Distribution shift happens when the data the model encounters in production differs from the data it was trained on. Even if a system was carefully audited for bias during development, changing real-world contexts can introduce new stereotypes, cultural references, or usage patterns that shift the model’s outputs.
Emergent biases might appear due to: • Current events: A sudden surge of content about a topic or group might skew the language model’s output or degrade its performance if that domain was previously underrepresented. • Shifts in language usage: Slang, culturally loaded terms, or newly coined words can introduce biases the model hasn’t learned how to handle appropriately. • Societal changes: Norms about what is considered offensive or problematic can evolve over time, making an older model’s responses outdated or biased.
Managing this risk involves: • Ongoing monitoring of production outputs, including collecting user feedback and automatically analyzing text for harmful content. • Periodic retraining or fine-tuning with more recent datasets so the model remains current with evolving language and cultural contexts. • Agile update processes to incorporate new known biases or emergent patterns quickly, rather than waiting for a single large release cycle.
A pitfall here is that an organization may assume the problem is solved after an initial debiasing stage. Without continuous vigilance, newly introduced data or usage scenarios can cause biases to reappear in unpredictable ways.
How do we balance preserving cultural context or humor while avoiding offensive or biased content?
Large language models often learn humor, idioms, and cultural references from their training data. Some humor relies on stereotypes or subtext that can be harmful if the model repeats it uncritically. On the other hand, removing all culturally specific references can make the model dull or unrelatable.
Achieving balance requires: • Context-specific analysis to understand when a humorous reference is harmless or culturally acceptable versus when it perpetuates stereotypes. • Carefully calibrated classification systems or human review processes that can differentiate nuanced cultural jokes from overtly harmful statements. • Providing user-facing controls such that if a user wants more “safe” or “family-friendly” outputs, the system can scale back riskier jokes or references, but still allow more open-ended or contextually relevant humor when appropriate.
Edge cases arise with global usage: a joke acceptable in one region might be deeply offensive in another. Thus, localizing the model or applying region-specific filters can be necessary. However, that introduces complexity in how the model is distributed and maintained across diverse linguistic or cultural groups.
What are the risks associated with relying solely on user feedback for bias identification, and how can we mitigate them?
User feedback is valuable because it provides real-world signals about offensive or biased outputs that might not be captured in internal tests. However, relying exclusively on user reports can be problematic for several reasons:
• Reporting bias: Users from marginalized communities might be less likely to submit feedback due to skepticism or fear of not being heard. On the other hand, more vocal user groups might flood the system with minor complaints, overshadowing more serious bias issues that affect smaller communities. • Latency: The model might generate harmful outputs repeatedly before enough user complaints accumulate to trigger a fix. • Strategic manipulation: Organized actors with certain agendas could potentially generate a large volume of complaints to push the model in directions that may not be equitable or beneficial to all users.
To mitigate these risks, organizations need: • Proactive bias detection tests, including automated scanning for known harmful patterns and synthetic “red-teaming” prompts. • Mechanisms to prioritize and categorize user feedback based on severity, potential harm, and repeated patterns. • A balanced approach that includes domain experts, diverse testers, and external stakeholders in regular audits to spot gaps in user feedback.
What best practices can be applied to large-scale multilingual models to ensure bias mitigation efforts are effective across different languages?
When a model is trained on texts from multiple languages, biases can manifest differently depending on cultural context, linguistic structures, and available data. A language that is underrepresented in the training data might have more skewed associations or outdated references. Similarly, social hierarchies and stereotypes vary across cultures, so debiasing in one language may not apply cleanly in another.
Key best practices: • Collect and maintain comprehensive multilingual corpora, ensuring that data is not solely drawn from one region’s online sources. • Engage native speakers to identify biases or stereotypes specific to their language. Automatic translation tools may miss nuanced issues like slurs or certain coded terms that appear in local dialects. • Evaluate performance and fairness metrics across languages to detect if the model is biased toward or against certain linguistic groups. • Implement language-specific fine-tuning or adapter modules that can address localized biases without disrupting performance in other languages.
A pitfall arises when developers assume that solutions for one language generalize directly to others. Cultural norms differ, so a “neutral” statement in one language might carry a negative connotation in another. Continuous review by native speakers and region-specific domain experts is crucial.
What happens if a debiasing approach conflicts with local regulations or cultural norms in a specific jurisdiction?
In some regions, local laws or cultural norms may define “bias” or “harmful content” differently. For example, certain political statements might be regarded as discriminatory in one country but as free speech in another. This can create tension if a global model is consistently applying one set of debiasing standards everywhere.
Potential challenges: • Conflict with laws that mandate blocking content related to specific groups or topics could force the model to produce artificially “sanitized” or suppressed outputs in certain jurisdictions. • Users in other regions might criticize such model behavior as censorship or a violation of their right to information. • Cultural norms vary widely, and a single global policy may leave local stakeholders feeling misrepresented or disrespected.
Organizations typically address this by: • Working closely with legal teams and local advisors to ensure that the model complies with the relevant regulations while maintaining as much open discourse as possible. • Allowing region-specific customizations or “model variants” that adopt local definitions or filters, balanced against universal ethical principles. • Maintaining transparency about what changes are made for compliance, so users understand why certain outputs are restricted in their region.
Pitfalls include a lack of clarity about where local regulations stop and universal company policies begin. This can lead to accusations of inconsistent or selective enforcement, undermining trust in the model. Maintaining detailed and transparent documentation of each region’s stance is key to reducing confusion.
How should teams approach measuring the real-world impact of biases that occur in niche domains or specialized user bases?
Some forms of bias may affect specialized user groups, such as professionals in a narrow domain or individuals seeking niche information. If the overall user base is large, these smaller communities could be overlooked when designing and testing debiasing measures. Yet, for those niche users, seemingly minor biases might cause significant harm or misinformation.
Ways to measure impact: • Targeted user studies or focus groups from the specific domain to gather qualitative feedback on whether the model meets their needs without introducing bias. • Tracking domain-specific query logs to identify if certain specialized topics produce skewed or harmful outputs. • Developing fine-grained metrics that reflect domain-relevant fairness criteria (e.g., how medical advice might differ incorrectly for one demographic group in a medical chatbot scenario).
The pitfall is assuming that standard fairness metrics or broad user satisfaction scores capture every form of bias. These niche groups might not submit a high volume of feedback, so specialized evaluations and domain expertise are crucial. If ignoring them, the model could perpetuate harmful stereotypes or misinform a vulnerable audience that relies on accurate, unbiased content.