
ML Interview Q Series: Deriving the Probability Density of Circle Area from a Uniform Radius

Browse all the Probability Interview Questions here.
The radius of a circle is uniformly distributed on (0,1). What is the probability density of the area of the circle?
Short Compact solution
We let X be the radius, which is uniform(0,1). The area of the circle is Y = π X^2. To find the probability distribution of Y, we first compute the CDF:
P(Y ≤ y) = P(π X^2 ≤ y) = P(X ≤ sqrt(y/π)) = sqrt(y/π), for 0 ≤ y ≤ π.
Differentiating with respect to y gives the PDF:

for 0 ≤ y ≤ π, and g(y) = 0 otherwise.
Comprehensive Explanation
Uniform distribution of the radius
Since the radius X is uniform on (0,1), it has a PDF f(x) = 1 for 0 < x < 1 and 0 otherwise. The support of X is therefore the interval (0,1).
Definition of the area variable Y
The area of a circle is given by the formula Y = π X^2, where X is the radius. Because X is between 0 and 1, Y ranges between 0 and π.
Finding the CDF
To find the distribution of Y, one of the common approaches is to use the CDF method:
P(Y ≤ y) = P(π X^2 ≤ y).
Since π X^2 ≤ y means X^2 ≤ y/π, we have X ≤ sqrt(y/π). For valid y (0 ≤ y ≤ π), sqrt(y/π) lies between 0 and 1, so:
P(Y ≤ y) = P(X ≤ sqrt(y/π)).
Because X is uniform(0,1), the probability that X ≤ some value z is simply z if z is in (0,1). Here, z = sqrt(y/π). Hence:
P(Y ≤ y) = sqrt(y/π), for 0 ≤ y ≤ π.
When y < 0, the probability is 0, and when y > π, the probability is 1.
Deriving the PDF
We get the PDF by differentiating the CDF with respect to y. For 0 < y < π:
d/dy [ sqrt(y/π) ] = 1 / (2 sqrt(π y)).
Thus:

valid for 0 ≤ y ≤ π, and 0 otherwise.
Verifying the PDF
One can verify that g(y) integrates to 1 on [0, π]. Specifically, the integral from 0 to π of 1/(2 sqrt(π y)) dy can be shown to equal 1. This ensures that g(y) is a properly normalized probability density function.
Practical implementation aspect
In a simulation context, to sample from this distribution, you could first sample X ~ uniform(0,1), then compute Y = π X^2. This automatically yields Y values with the derived PDF. Conversely, if you needed direct sampling from Y’s distribution, you could implement the inverse transform method using P(Y ≤ y) = sqrt(y/π), but it is simpler to sample X and convert to Y.
Potential Follow-Up Question 1
How would you sample from Y directly using the inverse CDF method, rather than generating X first?
When using the inverse CDF method, you generate a random variable U that is uniform(0,1), then solve:
sqrt(y/π) = U
for y. Specifically:
y = π (U^2).
Hence, one can implement direct sampling by:
Generate U ~ uniform(0,1).
Set Y = π (U^2).
This Y will have the correct PDF g(y) = 1/(2 sqrt(π y)) for 0 ≤ y ≤ π.
Potential Follow-Up Question 2
Could we derive the PDF of Y by the general variable transformation formula instead of the CDF approach?
Yes. The general formula for a monotonic transformation Y = h(X) gives:
g(y) = f_X(h^{-1}(y)) * | d/dy [h^{-1}(y)] |,
where f_X is the PDF of X. Here, h(x) = π x^2, so h^{-1}(y) = sqrt(y/π). The derivative of sqrt(y/π) with respect to y is 1/(2 sqrt(π y)). Because f_X(x) = 1 for 0 < x < 1, we have:
g(y) = 1 * (1/(2 sqrt(π y))) = 1/(2 sqrt(π y)),
valid for 0 < y < π, and 0 otherwise. This is the same result we obtained using the CDF method.
Potential Follow-Up Question 3
What happens if the radius had been distributed on (0, a) instead of (0,1)? How would that change the PDF for Y?
If X were uniform(0, a), then Y = π X^2 could range from 0 to π a^2. The CDF becomes:
P(Y ≤ y) = P(X ≤ sqrt(y/π)) = sqrt(y/π) / a,
provided that 0 ≤ y ≤ π a^2. Differentiating that would lead to:
g(y) = 1/(2 a sqrt(π y)) for 0 ≤ y ≤ π a^2,
and 0 otherwise. Essentially, the factor of 1/a appears because of the uniform(0,a) scaling of X.
Potential Follow-Up Question 4
Can you show a quick Python snippet to demonstrate how to numerically verify that the PDF integrates to 1?
import numpy as np
def pdf_y(y):
return 1.0/(2.0 * np.sqrt(np.pi * y))
def numerical_integration(func, start, end, num_points=100000):
x_vals = np.linspace(start, end, num_points)
fx_vals = func(x_vals)
return np.trapz(fx_vals, x_vals)
# Integrate over y from 0 to pi
integral_value = numerical_integration(pdf_y, 1e-12, np.pi) # avoid y=0 due to singularity
print("Approximate integral of g(y) from 0 to pi:", integral_value)
This code approximates the integral of g(y) from 0 to π using a trapezoidal rule. The result should be close to 1 (you might see a small numerical deviation depending on the discretization and the way the singularity near y=0 is handled).
Below are additional follow-up questions
Follow-up Question 1
Suppose you want to calculate the expected value of the area, E[Y], and its variance Var(Y). How would you go about deriving these, and what are the results?
Answer
To find E[Y], recall that Y = π X^2, where X ~ Uniform(0,1). The expectation of Y is:
We know E[X^2] = 1/3 when X ~ Uniform(0,1). Therefore:
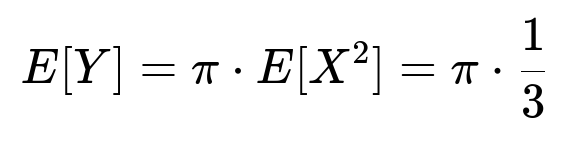
Hence E[Y] = π/3.
For the variance, we use Var(Y) = E[Y^2] - (E[Y])^2. First compute E[Y^2]:
Y^2 = (π X^2)^2 = π^2 X^4. So E[Y^2] = π^2 E[X^4]. Since X ~ Uniform(0,1), E[X^4] = 1/5. Thus,
E[Y^2] = π^2/5.
Then (E[Y])^2 = (π/3)^2 = π^2/9. Hence,
Var(Y) = π^2/5 - π^2/9 = π^2 (1/5 - 1/9) = π^2 (9/45 - 5/45) = 4π^2/45.
A subtle pitfall is forgetting that X^2 has its own mean and that you must compute E[X^4] for the second moment. Another edge case is mixing up the distribution’s domain and integrating incorrectly. Always remember to confirm that X is indeed uniform(0,1) when applying these formulas.
Follow-up Question 2
In practice, you might measure the radius with some noise, meaning the actual measurement could be X + ε where ε is a small random error term. How might this affect the distribution of the measured area Y = π (X + ε)^2, and how would you approach analyzing it?
Answer
When measurement noise is introduced, the radius you use in your calculation is no longer purely uniform(0,1). Instead, it is X + ε, where X is uniform(0,1) and ε could be some zero-mean noise (e.g., Gaussian with small variance). The resulting area variable becomes Y = π (X + ε)^2.
Distribution Changes: The distribution of Y now depends on the convolution of X’s distribution with the distribution of ε. This is more complex than a simple uniform.
Approximation: If ε is small, one might approximate (X + ε)^2 ≈ X^2 + 2Xε and treat that as a perturbation of the original π X^2.
Exact Analysis: You could use the law of total variance, or the law of total expectation, conditioning on X first, and then averaging over ε. Specifically, E[Y] = E[π(X + ε)^2] = π E[X^2] + 2π E[X ε] + π E[ε^2]. Because E[ε] = 0, the term E[Xε] might be zero if X and ε are independent.
Practical Pitfalls: A pitfall is assuming the noise is always small enough to ignore. Another pitfall is ignoring boundary effects if X + ε could exceed 1 or drop below 0, which might be non-physical for a radius. You would need to truncate or clamp negative values.
Follow-up Question 3
If we wanted the distribution of the circle’s circumference C = 2πX, where X is uniform(0,1), how would we derive that distribution and how would it differ from the distribution of the area?
Answer
For the circumference, define C = 2πX. Then C takes values in (0, 2π). Because X is uniform(0,1), we can repeat a similar procedure:
Compute the CDF: P(C ≤ c) = P(2πX ≤ c) = P(X ≤ c/(2π)) = c/(2π), for 0 ≤ c ≤ 2π.
Differentiate to get the PDF: d/dc [ c/(2π) ] = 1/(2π) for 0 ≤ c ≤ 2π.
Thus, the PDF is constant over the interval (0, 2π). By contrast, the area distribution is not uniform on (0, π); it has a PDF 1/(2√(πy)), which skews more density towards smaller areas. A key difference is that circumference scales linearly with X, whereas area scales quadratically with X, causing the area distribution to be more concentrated near 0.
A common pitfall is to assume all circle-related transformations produce the same “shape” of distribution. Another subtlety is ensuring you respect the domain: for C, the domain is (0, 2π), while for area, it is (0, π).
Follow-up Question 4
Consider a scenario where, instead of the radius, the diameter D is uniform(0,2). Could we still use a similar procedure to obtain the area’s distribution? How does that distribution compare to the previous case (radius uniform(0,1))?
Answer
Yes, you can use a similar approach but you must carefully redefine your variables. If D is uniform(0,2), then the radius X = D/2 is uniform(0,1). This reduces to exactly the same distribution for X as in the original problem. Consequently, the area distribution would be identical to the case where X is uniform(0,1).
However, a potential confusion arises if one directly writes Y = π (D/2)^2 without carefully recognizing that D’s range is (0,2). Although the final range for Y is still (0, π), you might mix up the direct uniform distribution for D with the implied distribution for X. If you keep track carefully, you get the same final distribution for the area. The pitfall is forgetting that a uniform distribution on diameter (0,2) is equivalent to a uniform distribution on radius (0,1).
Follow-up Question 5
What if the radius was drawn from a Beta(α, β) distribution on (0,1) instead of a uniform distribution? How would you derive the area’s distribution then?
Answer
If X ~ Beta(α, β) on (0,1), then Y = πX^2. You would typically use a general transformation formula:
g_Y(y) = f_X(h^(-1)(y)) * | d/dy [ h^(-1)(y) ] |,
where h(x) = πx^2, so h^(-1)(y) = sqrt(y/π). The PDF of a Beta(α, β) variable is proportional to x^(α-1) (1 - x)^(β-1). Substituting x = sqrt(y/π) yields:
f_X(sqrt(y/π)) = (1/B(α, β)) [ sqrt(y/π) ]^(α - 1 ) [1 - sqrt(y/π)]^(β - 1 ).
The derivative d/dy [ sqrt(y/π) ] = 1/(2 sqrt(πy)) multiplies this. You get:
g_Y(y) = 1/B(α, β) * ( (y/π)^((α - 1)/2 ) ) * ( 1 - sqrt(y/π) )^(β - 1 ) * 1/(2 sqrt(π y)), for y in (0, π).
This distribution is more flexible, allowing skewness depending on α and β. A common pitfall is ignoring that the Beta distribution has boundary effects at 0 and 1. If α < 1 or β < 1, the PDF might diverge at the endpoints, which affects the shape of the transformed area distribution.
Follow-up Question 6
How would we simulate random draws of the area Y if the radius X is governed by a known distribution, but we only have a function that can sample from X’s distribution (i.e., we do not have a direct formula for Y’s inverse CDF)?
Answer
If you can sample X directly, then the simplest approach is to perform the transformation Y = πX^2. Specifically:
Draw X from its known distribution. This could be uniform(0,1), normal truncated to (0,1), Beta(α, β), etc.
Transform to get Y = πX^2.
You do not need the inverse CDF for Y because you have a direct generative approach for X. This procedure yields samples from the correct distribution of Y by the method of transformation. A potential pitfall is if the radius distribution is not restricted to (0,1) or if negative values are possible—then you must carefully handle transformations. Also, in some distributions, X^2 could cause heavy concentration near 0 if the distribution puts significant mass near X=0.
Follow-up Question 7
Sometimes, one might be interested in extreme quantiles of the area distribution, say the 99th percentile. How would you find that in closed form for the uniform(0,1) radius case?
Answer
For the uniform(0,1) radius and Y = πX^2, the CDF is P(Y ≤ y) = sqrt(y/π). To find the 99th percentile y_0.99, solve:
sqrt(y_0.99 / π) = 0.99.
That implies y_0.99 / π = (0.99)^2. Therefore, y_0.99 = π (0.99)^2.
No integration is needed because we have an explicit expression for the CDF. A subtlety arises if the percentile in question is extremely close to π (e.g., 99.999th percentile), then rounding or floating-point precision might cause numerical issues in real implementations. But conceptually, you simply solve that CDF equation.
Follow-up Question 8
In some applications, the measured circle might have a minimum radius r_min > 0, rather than starting at 0. Could you discuss how that affects the PDF for the area and any potential challenges in computing or using it?
Answer
If the radius X is uniform on (r_min, r_max) with 0 < r_min < r_max, then:
Domain: X now lives on (r_min, r_max). The area Y = πX^2 takes values from π(r_min)^2 to π(r_max)^2.
CDF: P(Y ≤ y) = P(πX^2 ≤ y) = P(X ≤ sqrt(y/π)). However, because X cannot be less than r_min, you must account for that shift:
If y < π(r_min)^2, then P(Y ≤ y) = 0.
If π(r_min)^2 ≤ y ≤ π(r_max)^2, then P(Y ≤ y) = (sqrt(y/π) - r_min) / (r_max - r_min).
If y > π(r_max)^2, then P(Y ≤ y) = 1.
Differentiating: The PDF would be the derivative of the above piecewise CDF. This yields 1 / ( (r_max - r_min) * 2 sqrt(π y ) ) in the relevant range.
Challenges: A major challenge is ensuring your transformation is correct for y < π(r_min)^2 and y > π(r_max)^2. Another subtlety is that if r_min is not negligible, the distribution for Y shifts significantly away from 0, which affects how you interpret near-zero areas. This might be relevant in physical applications where a truly zero radius is impossible or meaningless.
In numerical implementations, forgetting to handle the shifted domain often leads to errors in code that calculates probabilities or quantiles.